
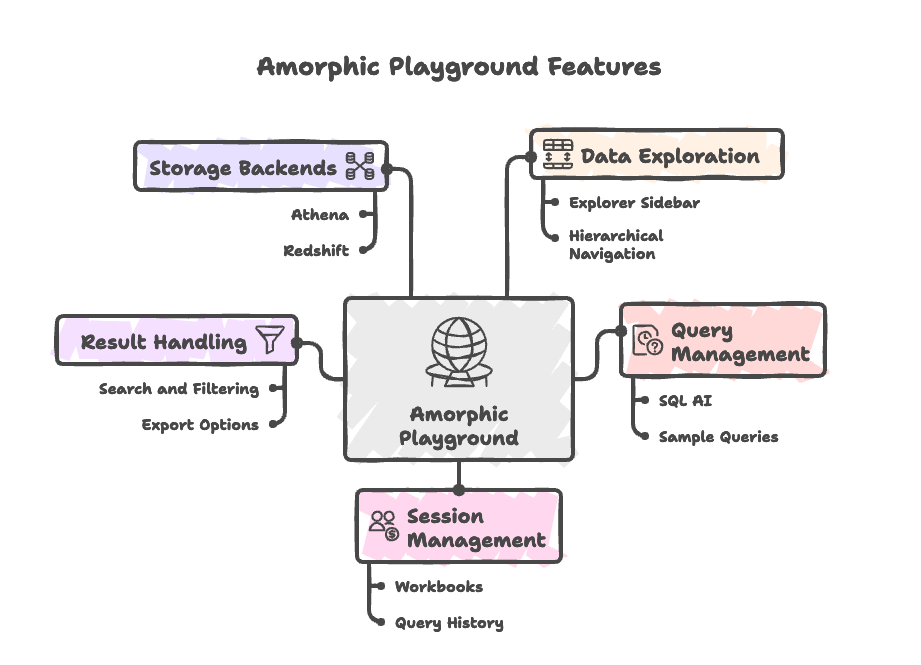
Amorphic Playground
This powerful tool allows you to harness the full potential of your data using familiar SQL queries. Whether your datasets are stored in Amazon S3 or Amazon Redshift, our Playground provides a seamless interface to analyze, explore, and extract insights from your data.
With the Amorphic Playground, you can:
- Browse and search datasets using the Explorer sidebar with hierarchical dataset navigation
- Run standard SQL queries against your datasets with syntax highlighting and multi-line editing
- Use SQL AI for AI-assisted query generation, explanation, and natural language querying
- Generate sample queries to help you get started
- Manage multiple data exploration sessions using workbooks
- View and export query results with search, filtering, and download capabilities
- Track your query history across all workbooks for future reference
- Seamlessly work with different storage backends (Athena and Redshift)
- Export results to datasets or download them for external analysis
This guide will walk you through everything you need to know to make the most of the Playground's capabilities.
Getting Started
The demonstration below illustrates the use of different kinds of operations available in QueryEngine.
Explorer Section
The Explorer section is located on the left sidebar of the Playground interface, providing a centralized view of your available datasets and enabling easy navigation and discovery of your data.
Dataset Navigation
- Search Datasets: Use the "Search datasets" input field with the magnifying glass icon to quickly find specific datasets by name. This search functionality filters the dataset list in real-time as you type.
- DWH Toggle: The "DWH" (Data Warehouse) toggle switch allows you to filter or switch between different data warehouse environments or views, helping you focus on relevant datasets for your analysis.
- Hierarchical Dataset List: Datasets are organized in a hierarchical tree structure, each represented by a folder/database icon. Click the expand arrow next to any dataset to view its nested structure. This organization helps you browse through domains and their associated datasets efficiently.
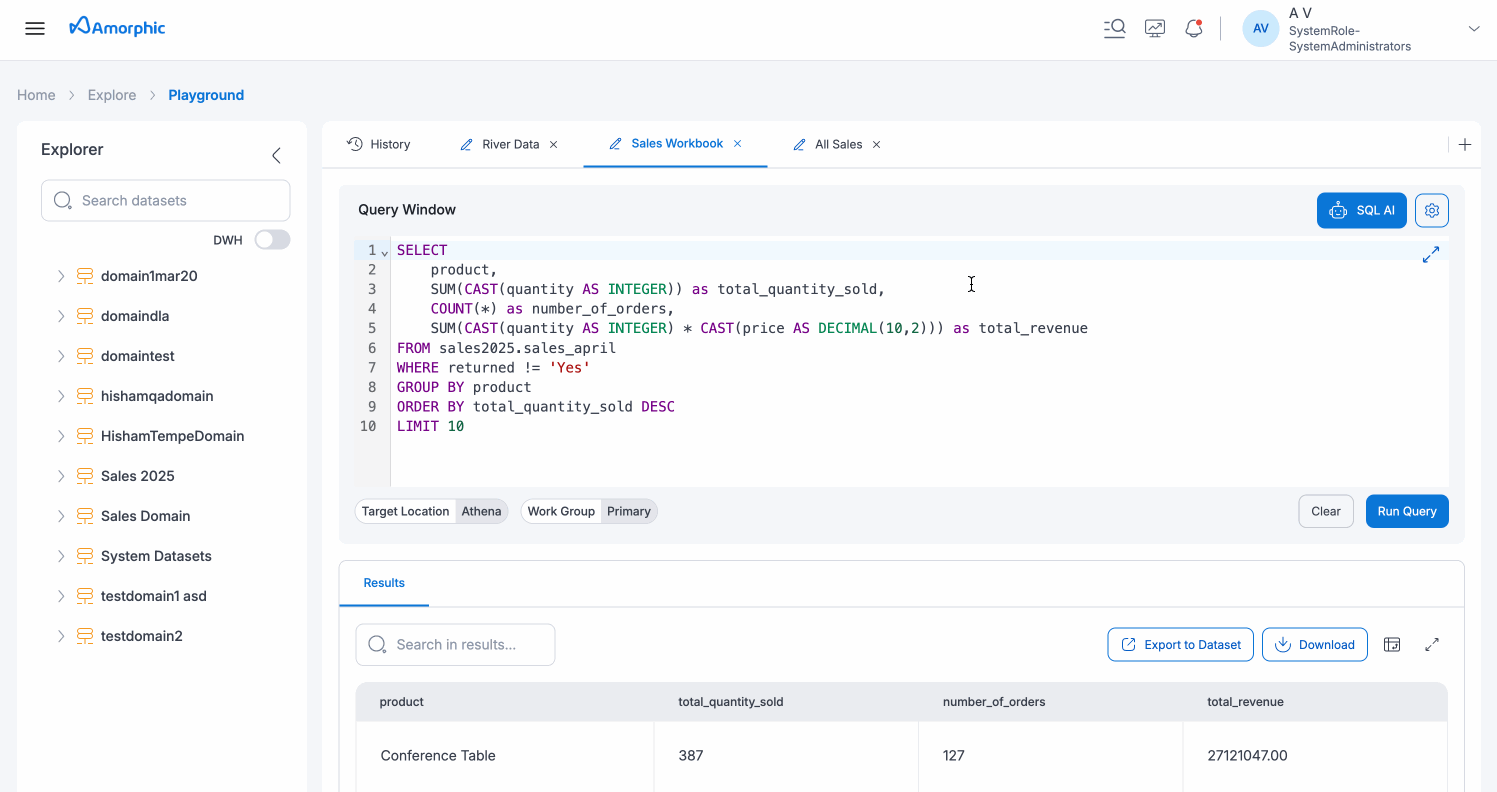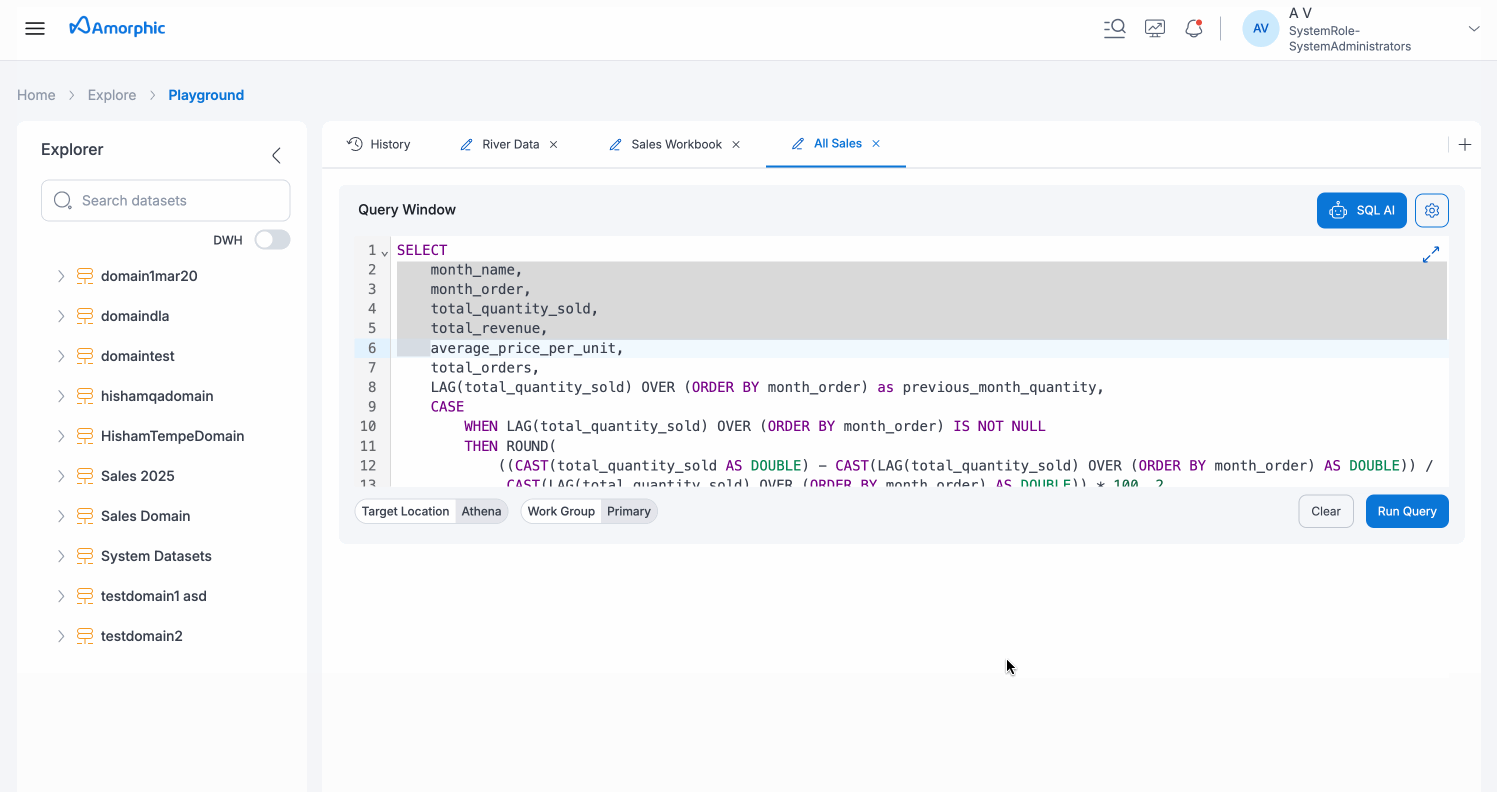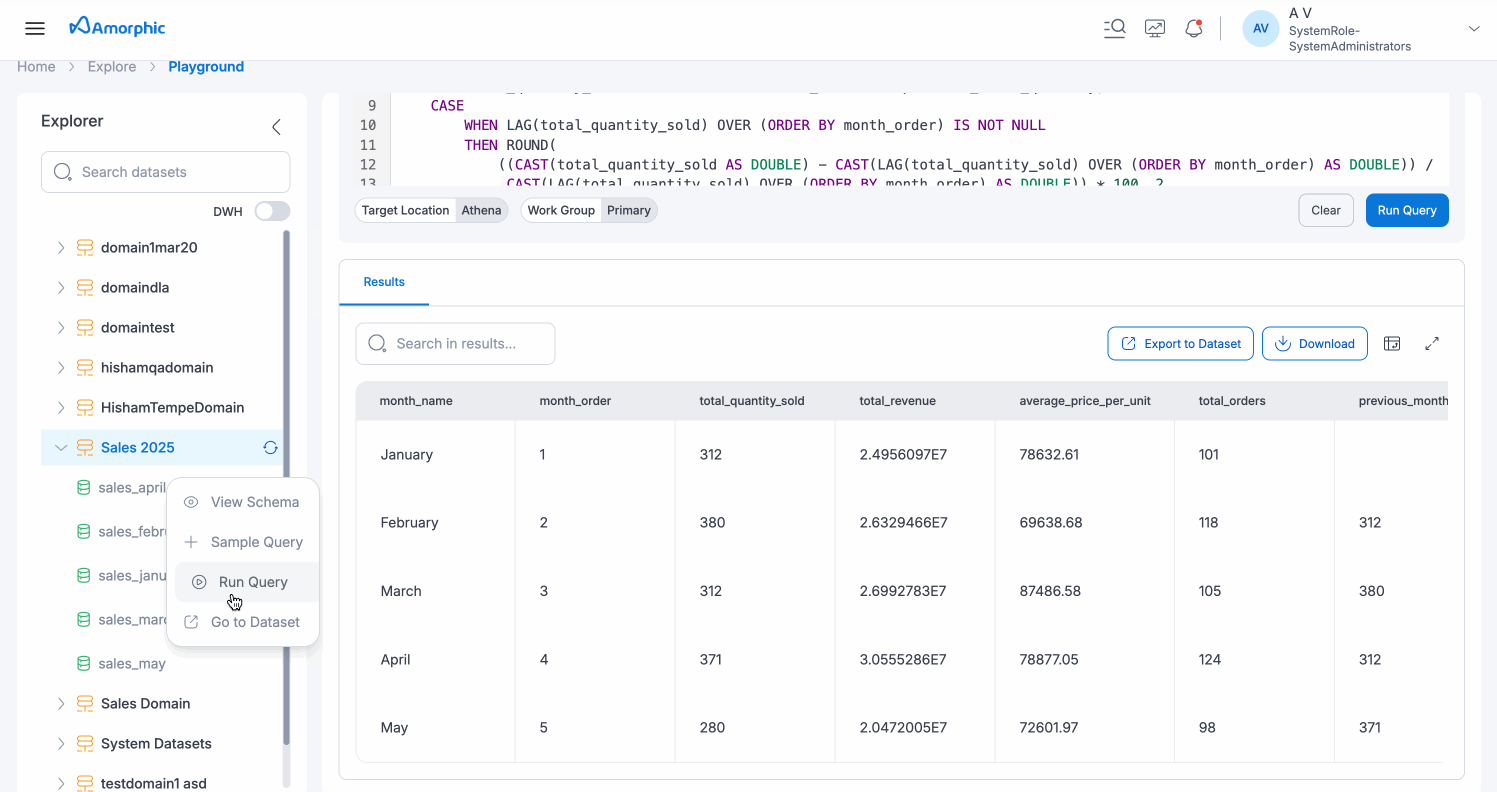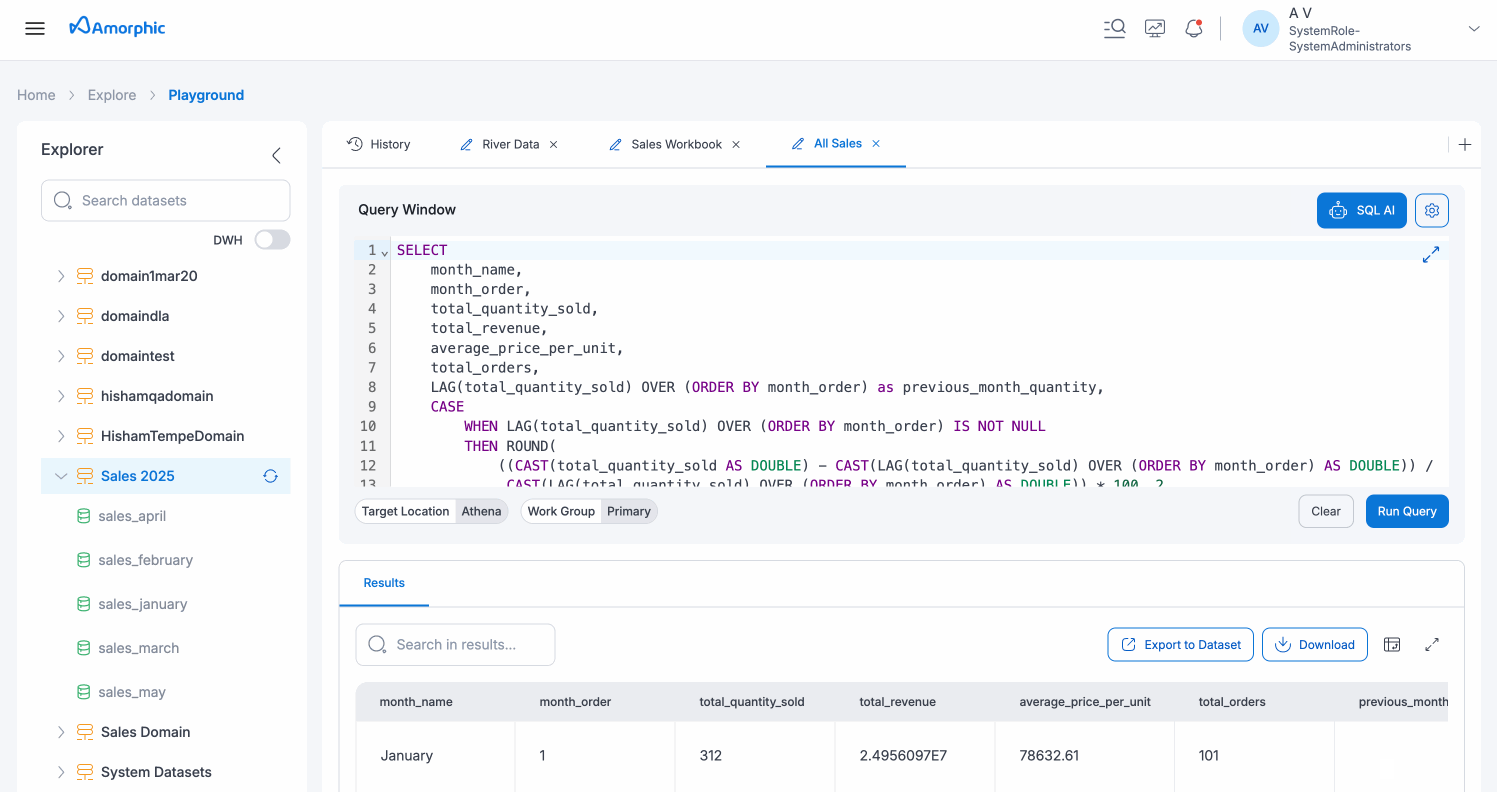
Dataset Context Menu
When you select a dataset in the Explorer, a context menu appears with the following options:
- View Schema: Opens the dataset schema to view column names, data types, and other metadata
- Sample Query: Generates a sample SQL query using the selected dataset, which is automatically populated in the Query Window
- Run Query: Opens the Query Window and prepares it to query the selected dataset
- Go to Dataset: Navigates directly to the dataset's detail page for more information and management options
The Explorer panel can be collapsed or expanded using the arrow icon at the top of the sidebar, allowing you to maximize your workspace when needed.
Workbooks
The Playground uses a workbook-based interface that allows you to manage multiple data exploration sessions simultaneously. Each workbook is a self-contained workspace for your queries, results, and analysis.
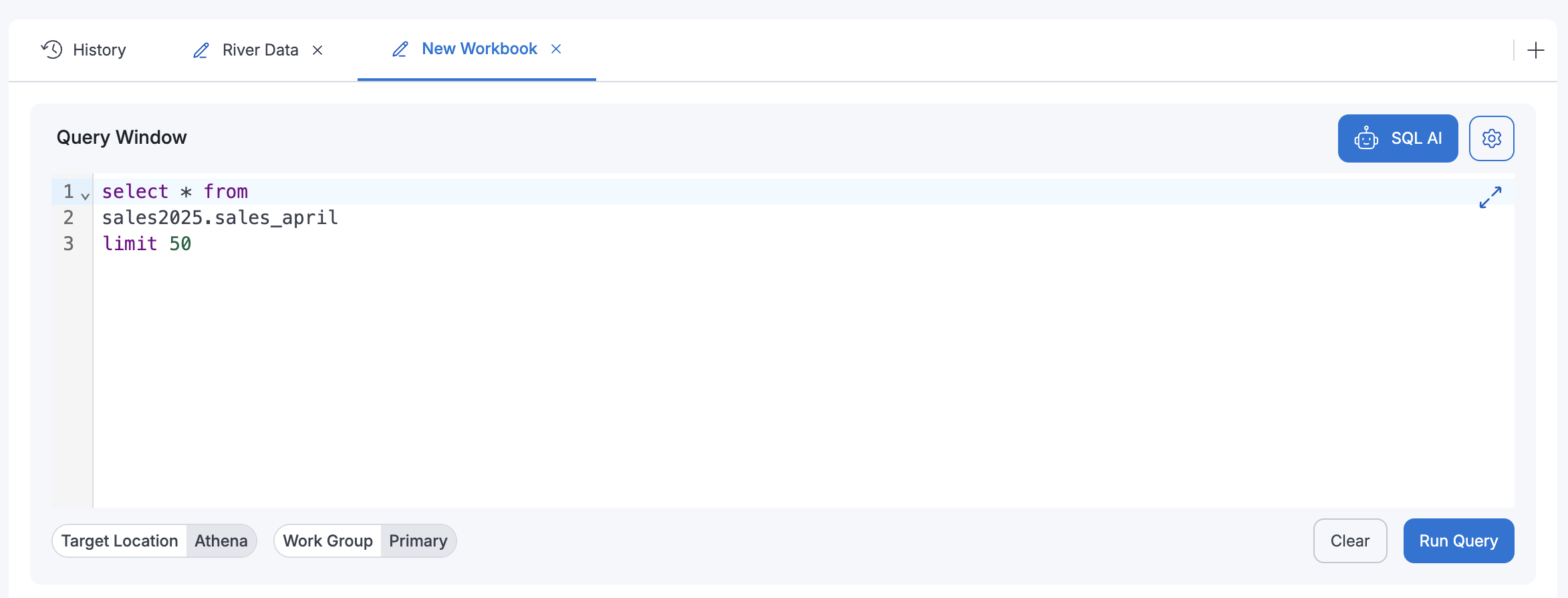
Understanding Workbooks
Workbooks appear as tabs at the top of the Playground interface. Each workbook contains:
- Query Window: A dedicated SQL editor for writing and executing queries. The workbook window displays the last query that was run in that specific workbook.
- Results Section: Displays query results in a table format with search and export capabilities
- Query Configuration: Settings for target location (Athena/Redshift) and workgroup selection
Creating and Managing Workbooks
- Create a New Workbook: Click the '+' icon on the far right of the workbook tabs to create a new workbook. This opens a fresh "New Workbook" tab with an empty query editor.
- Switch Between Workbooks: Click on any workbook tab to switch to that session. Each workbook maintains its own query state and displays the last query that was executed in that workbook.
- Rename Workbook: Click on the pen icon next to workbook name to edit and rename it. This helps you organize and identify your workbooks with meaningful names.
- Delete Workbooks: Click the 'x' icon on any workbook tab to delete that workbook. This permanently removes the workbook from your workspace.
Workbook Use Cases
Workbooks are ideal for:
- Separate Analysis Sessions: Keep different data exploration tasks organized in separate workbooks
- Comparing Queries: Work on multiple query variations side-by-side in different workbooks
- Project Organization: Maintain dedicated workbooks for specific projects or datasets
- Collaboration: Share specific workbook queries while keeping other work separate
History Tab
The "History" tab is available across all workbooks and displays:
- All queries executed by you in the system (not limited to a specific workbook)
- Query execution status and results
- Ability to review and re-run previous queries
- Query execution timestamps
The History tab provides a centralized view of all your query executions across the entire Playground, helping you track your analysis progress and reference successful queries from any workbook.
Query Window
The Query Window is your workspace for crafting and executing SQL queries. It provides a comprehensive SQL editor with multiple features and controls:
- SQL Editor: A multi-line text editor with syntax highlighting for writing your SQL queries. The editor supports standard SQL syntax and provides line numbers for easy reference.
- SQL AI Button: A prominent blue button with a robot icon that provides access to AI-assisted query generation, explanation, and optimization. Click this button to open the SQL AI interface for natural language query assistance.
- Settings Icon: A gear icon located next to the SQL AI button that provides access to query-specific settings and configurations.
- Fullscreen Icon: An expand icon (double-arrow) in the bottom-right corner of the Query Window that allows you to expand the editor to fullscreen mode for a distraction-free editing experience.
Query Execution Controls
Below the SQL editor, you'll find the execution controls:
- Clear Button: Removes all content from the query editor, allowing you to start fresh.
- Run Query Button: Executes the SQL query currently in the editor against your selected target location and workgroup. This is the primary action button (highlighted in blue).
- Target Location: Select the execution engine for your query:
- Athena: For datasets stored in Amazon S3 (default)
- Redshift: For datasets stored in Amazon Redshift
- Work Group: When using Athena, select the appropriate workgroup:
- Primary: Default workgroup for standard datasets
- AmazonAthenaEngineV3: Required for Iceberg datasets and merge operations
Quick Tips:
- Use the Explorer's "Sample Query" option to quickly populate the editor with a starter query
- Use the SQL AI button for help generating or understanding queries
- Expand the editor to fullscreen for complex queries
- Select the appropriate target location and workgroup before executing your query
Generating Sample Queries
Not sure how to structure your query? Let us help you get started:
- Select your Domain and Resource from the dropdown menus
- If querying a Redshift cluster, select the appropriate Tenant
- Click "Generate Sample Query"
- A sample query referencing your dataset will appear in the Query Editor
- Modify the sample query as needed for your specific analysis
Working with Queries
Supported Query Types
The Amorphic Playground supports different SQL commands based on the dataset type:
| S3Athena and Redshift Datasets | Iceberg Datasets | Hudi Datasets |
|---|---|---|
| SELECT | SELECT, INSERT INTO, UPDATE, DELETE FROM | SELECT, INSERT INTO, UPDATE, DELETE FROM |
| MSCK REPAIR TABLE | DESCRIBE, SHOW TBLPROPERTIES | DESCRIBE, SHOW TBLPROPERTIES |
| CREATE TABLE | SHOW PARTITIONS | SHOW COLUMNS, ALTER TABLE |
| CREATE EXTERNAL TABLE | OPTIMIZE, MERGE INTO | VACUUM |
| SHOW PARTITIONS | SHOW COLUMNS |
Query Target Location
Choose where to execute your query based on your data location:
Athena (default): For datasets stored in Amazon S3 Athena.
Redshift: For datasets stored in Amazon Redshift.
Workgroup Selection
When using Athena, you can select specific workgroups for query execution:
Default: This is the "primary" workgroup
Iceberg datasets: Require the "AmazonAthenaEngineV3" workgroup
Other datasets: Can use the default "primary" workgroup.
For Merging the queries user needs a V3 workgroup.
Using Assume Role Feature
Enable the "Assume Role" option when you need to:
- Query datasets with your specific IAM permissions
- Access Lake Formation views with Athena
This role cannot be used for system datasets or if you have more than 220 datasets assigned to you.
Assume Role and IAM policy paths
When Assume Role is used to query datasets, Amorphic follows the same policy pattern used for other shared-domain access: the user's IAM role prefers a single domain/* wildcard over one entry per dataset, to keep the policy compact.
Because Iceberg datasets require a different IAM statement shape than non-Iceberg datasets, domain/* is only used when every dataset in the domain is of the same type:
- Domain with all non-Iceberg datasets → policy uses
domain/* - Domain with all Iceberg datasets → policy uses
domain/*(under the Iceberg-shaped statement) - Domain with a mix of Iceberg and non-Iceberg datasets → policy falls back to individual
domain_name/dataset_name/*entries, since the two statement shapes cannot share a single wildcard
If you want the shorter domain/* form on a domain that already contains an Iceberg dataset, every other dataset in that domain must also be Iceberg type. Mixing types forces the per-dataset expansion.
Query Syntax and Best Practices
Proper Dataset Referencing
| Target Location | Reference Schema Format |
|---|---|
| Redshift resources | tenant_name.schema_name.resource_name |
| S3 Athena resources | schema_name.resource_name |
| Column access | tenant_name.schema_name.object_name.column_name |
When using reserved keywords in your queries, enclose them in double quotes. For instance,
'GROUP' is a reserved keyword, querying dataset where one of the column is 'GROUP'
-- Incorrect usage with reserved keyword
SELECT GROUP FROM domain.dataset
-- Correct usage with reserved keyword
SELECT "GROUP" FROM domain.dataset
For official documentation on reserved keywords, refer to:
Managing Query Results
Results Section
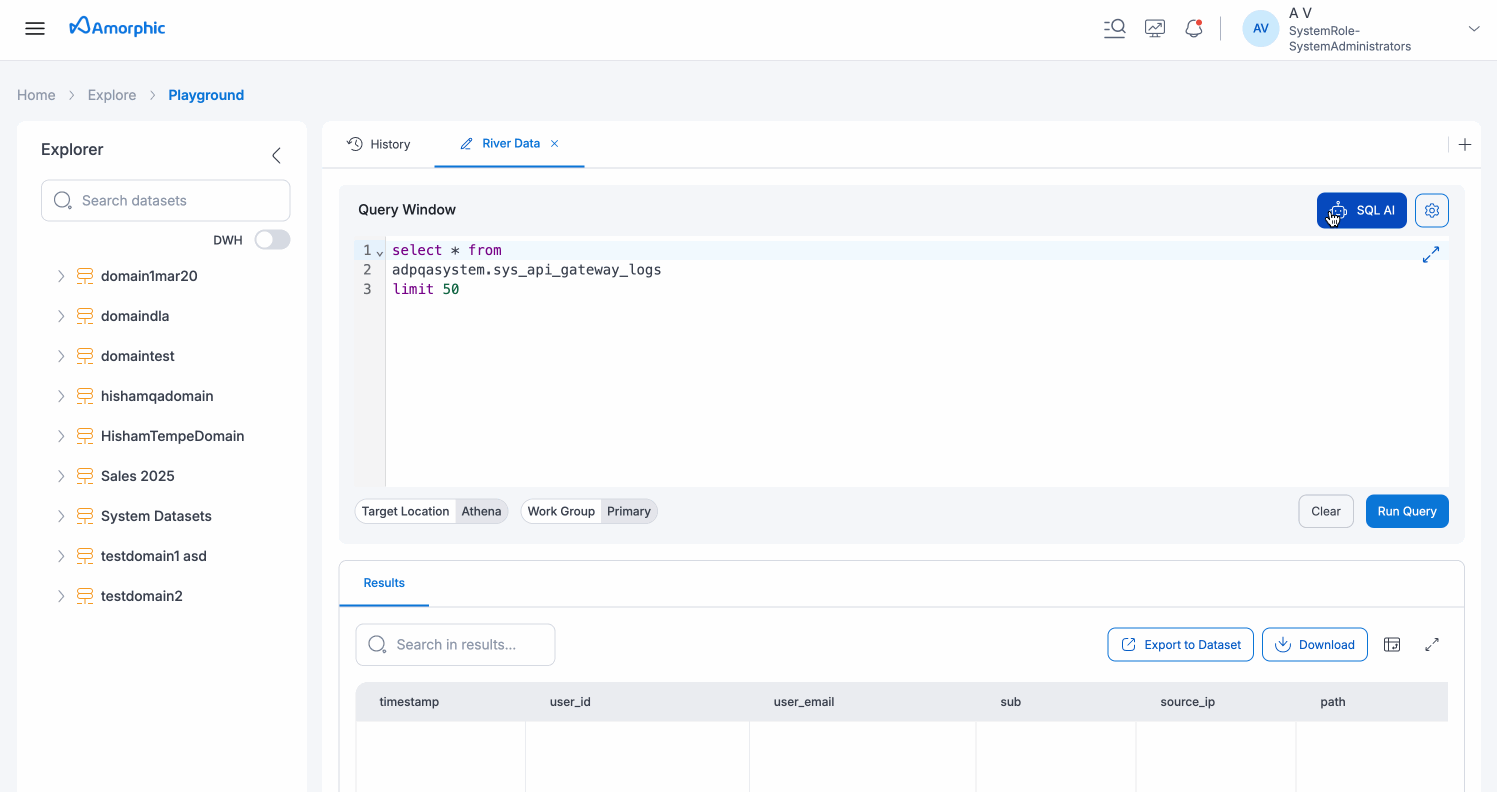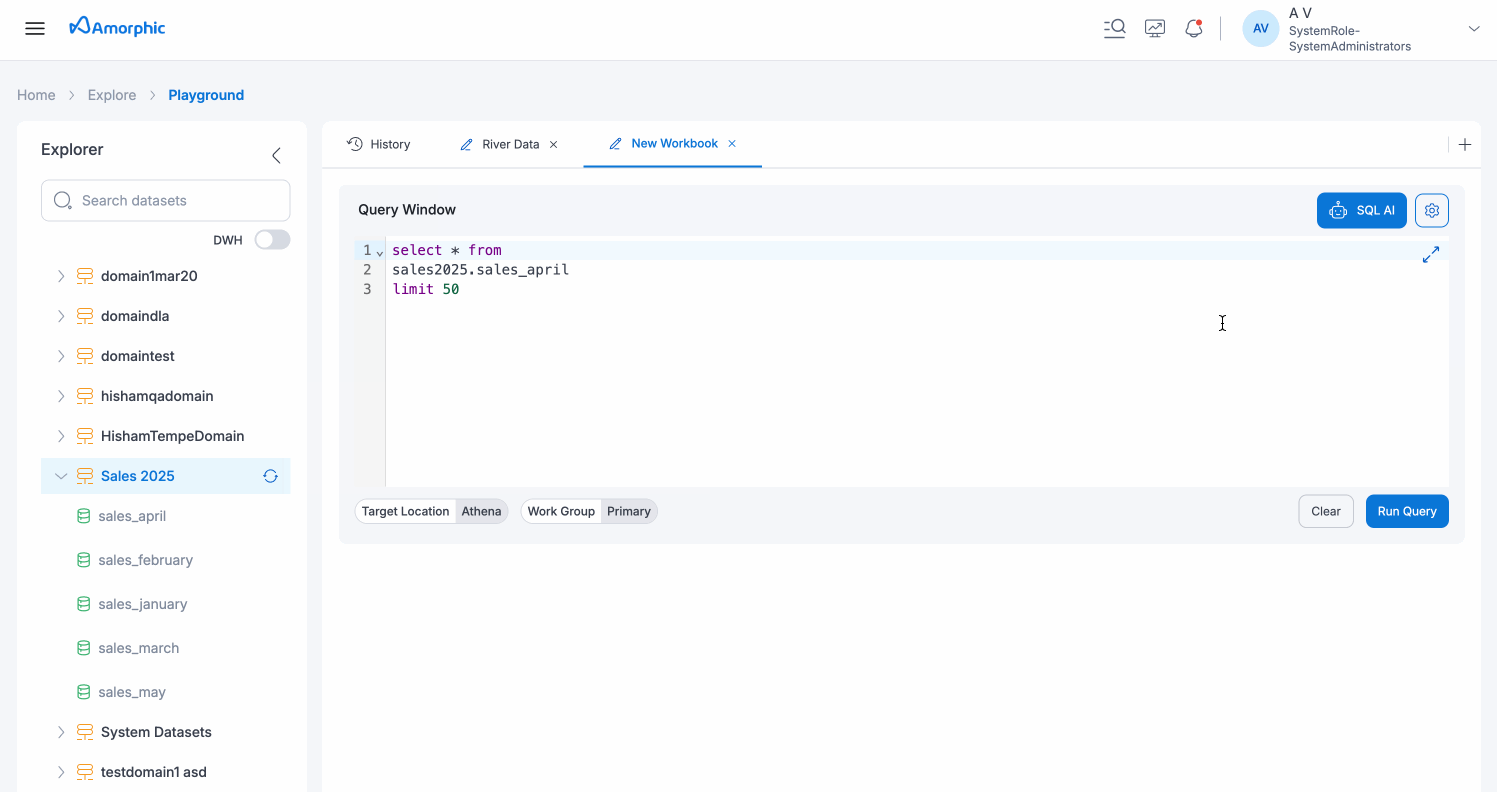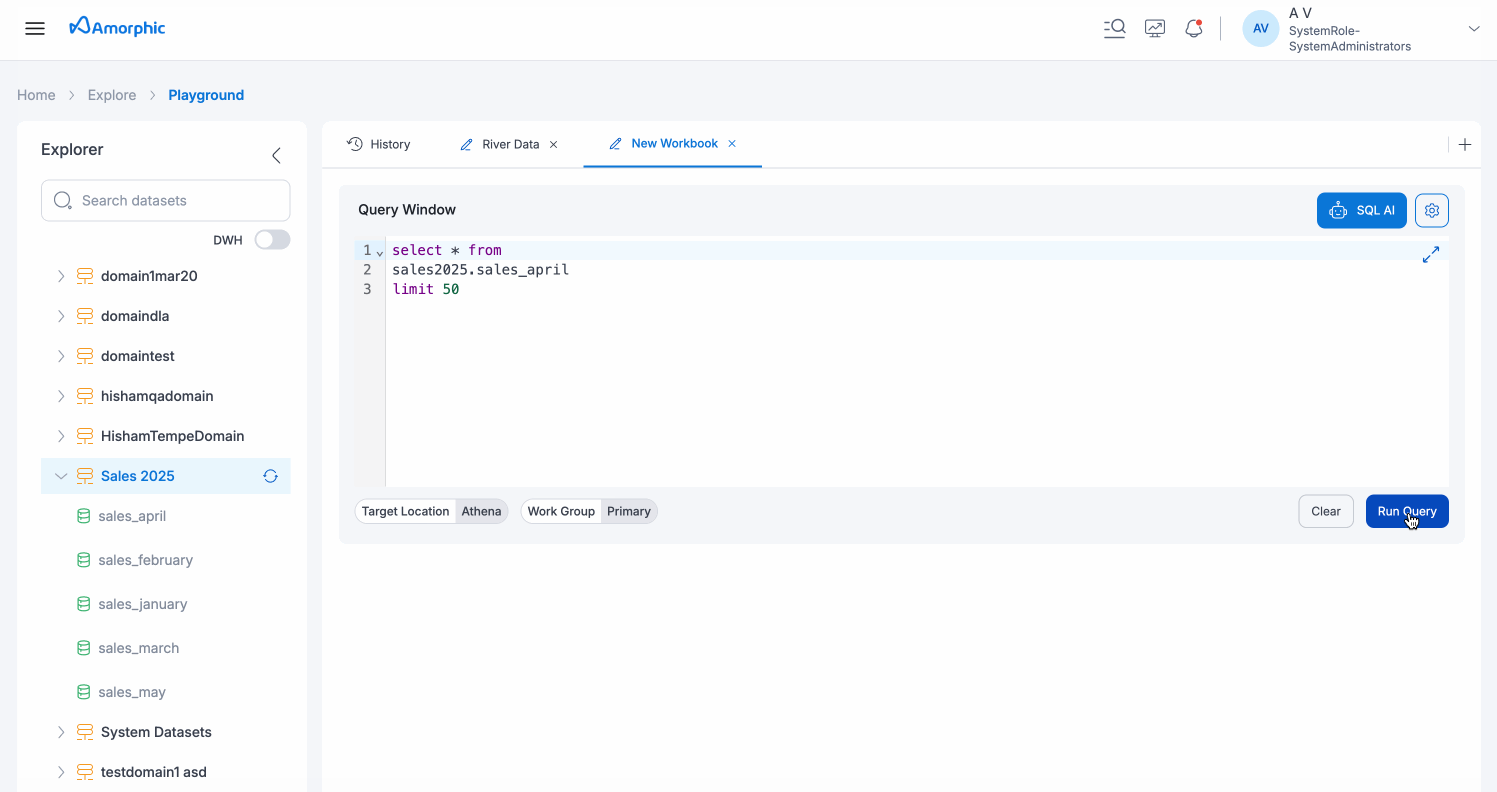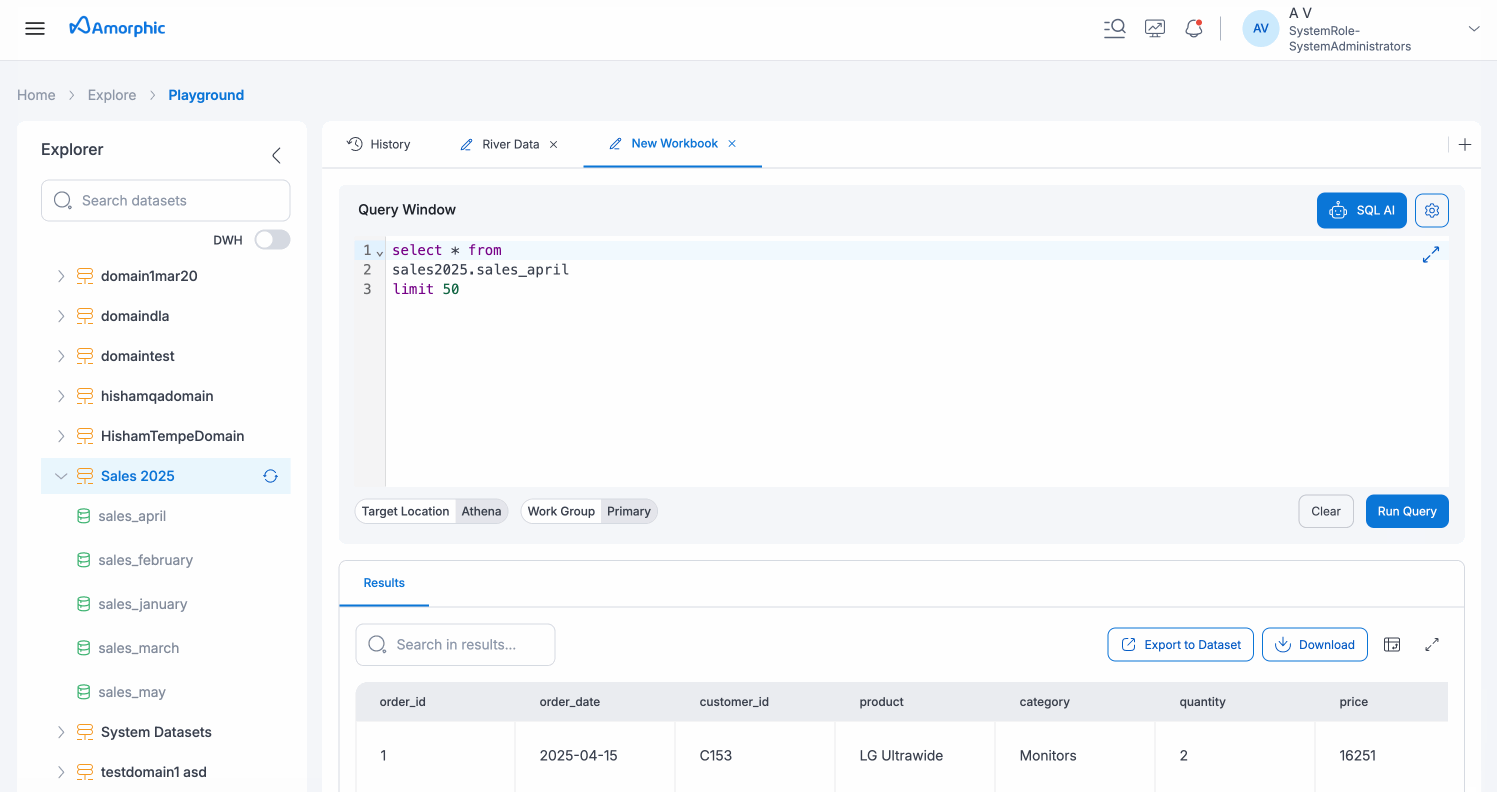
After successfully executing a query, the Results section displays your query output with comprehensive viewing and export capabilities:
- Results Tab: The Results tab appears below the Query Window, showing the executed query's output in a tabular format.
- Search in Results: A search bar labeled "Search in results..." allows you to filter the displayed results in real-time, making it easy to find specific data points within large result sets.
- Export to Dataset: Export your query results directly to a new or existing dataset within the Amorphic platform for further analysis or integration with other workflows.
- Download: Download the complete result set to your local machine in various formats (CSV, Excel, etc.) for external analysis or reporting.
- Fullscreen View: An expand icon allows you to view the results table in fullscreen mode for better visibility of large datasets.
Results Table
The results are displayed in a structured table format with:
- Column headers showing all returned columns from your query
- Scrollable rows displaying the data
- Column sorting capabilities for easy data organization
- Up to 50 records displayed in the initial view
Viewing Results:
- View up to 50 records directly in the Amorphic platform interface
- Use the search functionality to filter results within the displayed data
- Download the complete result set for external analysis (includes all rows, not just the displayed 50)
You can also perform following actions on a successful query result:
- Export query result to an existing dataset
- Create a new dataset from the query result
Query History
Access your past query executions in the History tab located next to the query editor. The History tab shows all queries run across the entire system, regardless of which workbook they were executed from. This helps you:
- Track your analysis progress across all workbooks
- Reference successful queries from any session
- Troubleshoot failed queries
Redshift query results are stored temporarily and expire 24 hours after execution.
API Integration
Execute queries programmatically by making a POST call to /queries with these parameters:
- QueryString: Your SQL query string (required)
- Encoding: Specify how the query is encoded (optional)
- none: Default for most queries
- base64: Required for queries with special characters (e.g., '%%')
Most queries can be run using Encoding set to none . However, you may encounter a forbidden issue due to WAF rules if QueryString contains strings like '%%'. To avoid this issue, we suggest using Encoding set to base64 and providing a base64 encoded QueryString.

Troubleshooting
Common Errors
If you encounter issues with your queries, check these common causes:
- Data-schema mismatches
- Invalid SQL commands
For detailed error information, consult AWS Documentation mentioned below:
Limitations and Considerations
- Maximum of 5,000 rows returned per query
- Redshift datasets cannot be queried alongside non-Redshift datasets
- Cross-tenant querying supported only for Redshift nodes of type "ra3"
When working with unsupported data types, refer to AWS Athena supported data types
Stop Query Option
Users have the option to stop a query whenever necessary during execution by clicking the "Stop Query" button.
Playground dropdowns will display only the user-accessible domains/datasets.