
Libraries
Libraries are an extension of external job libraries. They are mainly used to maintain a central repository of organization-approved libraries/packages to be used across multiple Jobs or Data labs.
These Libraries have the following capabilities:
- They allow users to have multiple packages attached to a job, so they can easily switch between them to perform various actions based on the job requirements.
- They provide the ability to customize job dependencies to a granular level.
- They offer flexibility to choose among the different type of packages.
Currently based on the type of ETL Job, Amorphic supports "py", "egg" and "whl" extensions for python shell applications and "py", "zip", "jar" for pyspark applications.

Library
A Library is a collection of packages/modules that provides a standardized solution for problems in everyday programming. Unlike the OS-provided python supporting the collection, the packages are explicitly designed by User/Organization/Open-Source Community. This encourages and enhances the portability of Python programs by abstracting away the platform-specific APIs into platform-neutral APIs.
The ETL Library has the following properties:
- A Library can have multiple packages attached to it.
- A Library can be attached to multiple Jobs.
Types of Amorphic ETL Libraries:
- External Libraries: Their scope is within the ETL job, and they get removed when user deletes the ETL job.
- Shared Libraries: They possess a universal scope, allowing multiple jobs to utilize the same shared library upon user authentication, and persist in the central repository even after the ETL job has been deleted.
Amorphic Libraries contain the following information:
| Type | Description |
|---|---|
| Library Name | Uniquely identifies the functionality of the library |
| Library Description | A brief explanation of the library typically the contents/package inside it |
| Packages | It is a file or a list of files that can be imported into an ETL Job to perform a specific set of operations. Example: matplotlib is A numerical plotting library used by any data scientist or any data analyzer for visualizations |
| Jobs | The list of ETL jobs to which the library is attached |
| CreatedBy | User who created the library. |
| LastModifiedBy | User who has recently updated the library. |
| LastModifiedTime | Timestamp when the library was recently updated. |
Libraries Operations
Amorphic libraries provides the following operations to manage the libraries:
- Create Library: Create a custom library by choosing the package(s) of the user's choice
- View Library: View existing library Shared ETL Libraries Metadata Information
- Attach Library: Attach an existing library to a ETL Job
- Importing and using a library: Import and use a library in a ETL Job
Create Library
To create a new Library in Amorphic, go to the "Create New Library" section under the "Libraries". The application allows libraries to have zero or more packages/jobs attached to it. After creating the Library user can view, update, & delete it. User can only do these operations if permissions to access the libraries is present on them.
Users cannot delete a shared library if it is attached to the existing ETL Job. So, when attempted to delete such a library, user will be notified with the list of dependent ETL Jobs with a pop-up. Then, user should remove all the libraries used in Jobs and retry to delete the library.
The below gif shows how a user can create a new library.

View Library
To view all the existing library information user must have sufficient permissions. Click the Library name under the "Libraries" section inside the Shared Resources scetion to view the library.
Take a look at how user can view the library information in detail

Attach Library
User can attach a library from the job details page and attach a shared library to a job while creating or updating it. Amorphic provides a list of shared libraries along with other job parameters, which user can then attach to the job. Once attached all the packages in the shared library are passed as arguments to the job automatically without any intervention.
Follow the below gif to attach a shared ETL library to an existing ETL Job.

Importing and using a library
If user has a library with a single version of the required module or multiple different files added in this single library, then they can import the module and use it.
from amorphicutils.common import read_param_store
print(read_param_store("SYSTEM.S3BUCKET.DLZ", secure=False)['data'])
If users have a library with a multiple version of the required module , then they should explicitly insert into the system path the versioned file and then import the module and use it. This ensures it allows picking up the specific version of the library and not a random one.
import sys
# explicitly specify the version user want to use
sys.path.insert(0, "amorphicutils-0.3.1.zip")
from amorphicutils.common import read_param_store
print(read_param_store("SYSTEM.S3BUCKET.DLZ", secure=False)['data'])
System Library
Starting version 3.1, Amorphic Libraries will come with one pre-packaged system library called ETL Toolkit.
This system library contains general set of tools and functionality required for general data preprocessing operations fully compatible with both Spark and Pandas(Python Sheel) data formats.
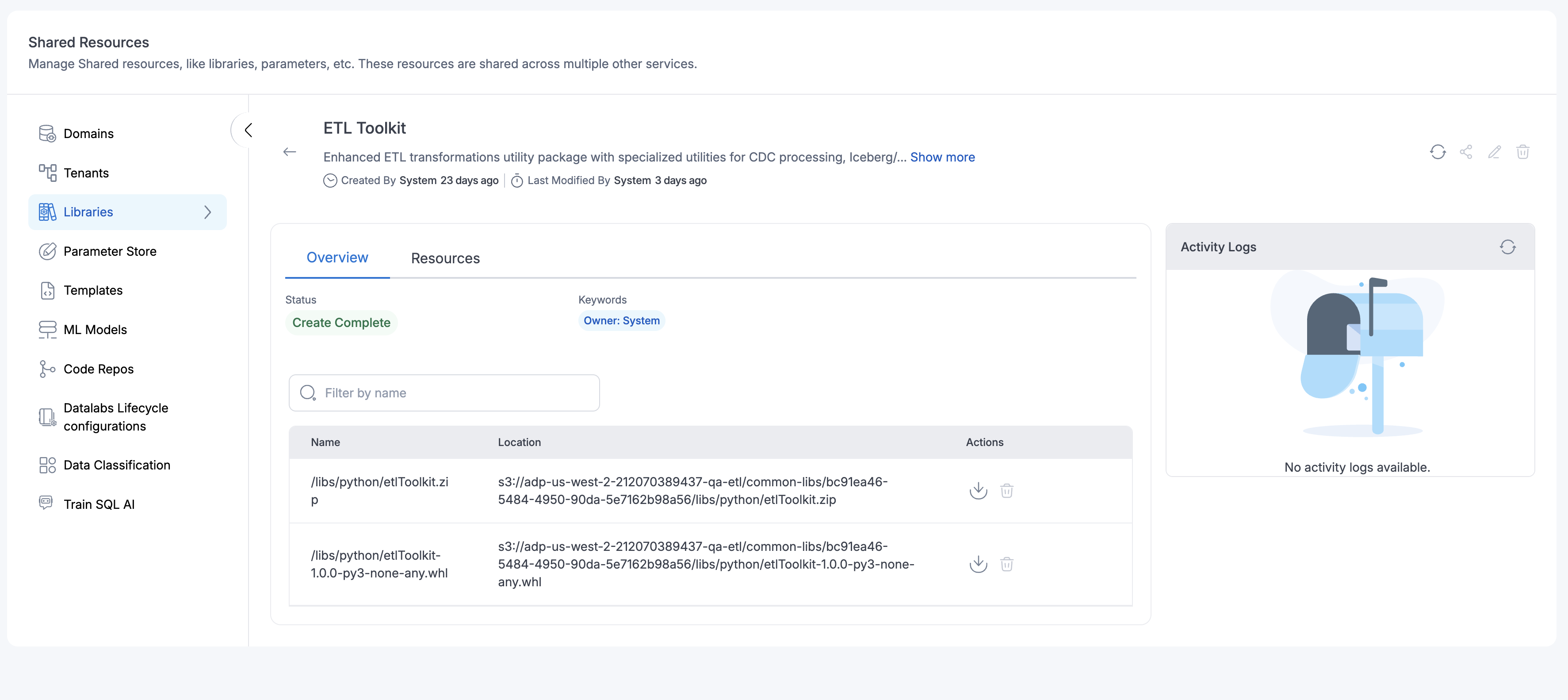
Click to view ETL Toolkit documentation
AWS Glue ETL Toolkit - Complete API Documentation
A comprehensive, high-quality utility package for AWS Glue ETL operations, providing unified interfaces for data transformations and modular components for advanced operations like schema management, CDC processing, and multi-target data loading.
Quick Start
Installation & Basic Usage
from etlToolkit import GlueTransformationsUtil
# Initialize with Spark session - enables all utilities
transformer = GlueTransformationsUtil(spark_session)
# Or initialize for Pandas-only operations
transformer = GlueTransformationsUtil()
Core Transformation Methods
1. change_column_types(df, type_mapping)
Purpose: Convert DataFrame column data types with validation and error handling.
Use Cases:
- Converting string dates to date types for temporal analysis
- Ensuring numeric columns have proper precision for calculations
- Standardizing data types across different data sources
- Preparing data for target system compatibility
Parameters:
df: Input DataFrame (Spark or Pandas)type_mapping: Dict mapping column names to target types
Supported Types: string, integer, long, double, boolean, date, timestamp, decimal
Example:
type_mapping = {
'customer_id': 'string',
'order_amount': 'double',
'quantity': 'integer',
'is_active': 'boolean',
'order_date': 'date',
'created_at': 'timestamp'
}
df_typed = transformer.change_column_types(df, type_mapping)
2. perform_join(left_df, right_df, join_keys, join_type, suffix_left, suffix_right)
Purpose: Join DataFrames with automatic Spark/Pandas detection and conflict resolution.
Use Cases:
- Customer data enrichment with demographic information
- Order-to-product mapping for sales analysis
- Multi-table data consolidation for reporting
- Dimensional modeling for data warehousing
Parameters:
left_df,right_df: DataFrames to joinjoin_keys: Column name(s) to join on (string or list)join_type: 'inner', 'left', 'right', 'outer'suffix_left,suffix_right: Suffixes for duplicate columns
Example:
df_joined = transformer.perform_join(
left_df=orders_df,
right_df=customers_df,
join_keys=['customer_id'], # Single or multiple keys
join_type='left', # inner, left, right, outer
suffix_left='_order',
suffix_right='_customer'
)
3. execute_sql_block(sql_query, dataframes)
Purpose: Execute complex SQL queries on DataFrames using Spark SQL engine.
Use Cases:
- Complex analytical queries with window functions
- Data aggregation and summarization
- Multi-table analytical processing
- Advanced filtering and transformation logic
Parameters:
sql_query: Standard SQL query stringdataframes: Dict mapping table names to DataFrames
Example:
dataframes = {'orders': orders_df, 'customers': customers_df, 'products': products_df}
result = transformer.execute_sql_block("""
WITH monthly_sales AS (
SELECT
customer_id,
DATE_TRUNC('month', order_date) as month,
SUM(amount) as monthly_total,
ROW_NUMBER() OVER (
PARTITION BY customer_id
ORDER BY SUM(amount) DESC
) as rank
FROM orders o
JOIN products p ON o.product_id = p.product_id
GROUP BY customer_id, DATE_TRUNC('month', order_date)
)
SELECT c.customer_name, ms.month, ms.monthly_total
FROM monthly_sales ms
JOIN customers c ON ms.customer_id = c.customer_id
WHERE ms.rank <= 3
""", dataframes)
4. perform_union(dataframes, union_type)
Purpose: Union multiple DataFrames with deduplication options.
Use Cases:
- Combining historical and current data
- Merging data from multiple sources
- Consolidating partitioned datasets
- Data lake aggregation scenarios
Parameters:
dataframes: List of DataFrames to unionunion_type: 'union', 'union_all', 'union_distinct'
Example:
combined_df = transformer.perform_union(
dataframes=[current_df, historical_df, archive_df],
union_type='union_distinct' # union, union_all, union_distinct
)
5. generate_uid_column(df, uid_column_name, uid_type)
Purpose: Generate unique identifier columns for data lineage and tracking.
Use Cases:
- Record-level tracking and auditing
- Deduplication key generation
- Distributed processing coordination
- Data lineage and provenance tracking
Parameters:
df: Input DataFrameuid_column_name: Name for the new UID columnuid_type: 'uuid', 'monotonic', 'timestamp_based'
Example:
df_with_uuid = transformer.generate_uid_column(df, 'record_uuid', 'uuid')
df_with_sequence = transformer.generate_uid_column(df, 'sequence_id', 'monotonic')
df_with_timestamp = transformer.generate_uid_column(df, 'batch_id', 'timestamp_based')
6. perform_lookup(main_df, lookup_df, lookup_key, lookup_value_column, main_key, result_column_name, default_value)
Purpose: High-performance lookup transformations for foreign key resolution.
Use Cases:
- Adding descriptive names to ID-based data
- Currency code to currency name mapping
- Status code to status description enrichment
- Reference data integration
Parameters:
main_df: Main DataFrame to enrichlookup_df: Reference DataFrame with lookup mappingslookup_key: Key column in lookup DataFramelookup_value_column: Value column to retrieve from lookupmain_key: Key column in main DataFrameresult_column_name: Name for new enriched columndefault_value: Value when lookup fails
Example:
enriched_df = transformer.perform_lookup(
main_df=orders_df,
lookup_df=customer_lookup_df,
lookup_key='customer_id',
lookup_value_column='customer_name',
main_key='customer_id',
result_column_name='customer_name',
default_value='Unknown Customer'
)
7. clean_column_names(df, remove_special_chars, to_lowercase)
Purpose: Clean and standardize column names for system compatibility.
Use Cases:
- Preparing data for Iceberg/Snowflake ingestion
- Standardizing column names across data sources
- Removing problematic characters for SQL compatibility
- Data warehouse schema standardization
Parameters:
df: Input DataFrameremove_special_chars: Whether to remove special charactersto_lowercase: Whether to convert to lowercase
Example:
df_clean = transformer.clean_column_names(
df=raw_df,
remove_special_chars=True,
to_lowercase=True
)
8. validate_dataframe_schema(df, expected_columns, strict_mode)
Purpose: Validate DataFrame schema against expected structure.
Use Cases:
- Data quality validation in ETL pipelines
- Contract testing between data sources
- Schema evolution monitoring
- Data governance compliance checking
Parameters:
df: DataFrame to validateexpected_columns: List of required column namesstrict_mode: If True, must have exactly these columns
Example:
expected_columns = ['customer_id', 'order_date', 'amount', 'status']
is_valid = transformer.validate_dataframe_schema(
df=orders_df,
expected_columns=expected_columns,
strict_mode=True # Must have exactly these columns
)
Specialized Utilities
Schema Management
Schema Fetcher
Purpose: Fetch database schemas from multiple sources (AS/400, MariaDB, Generic JDBC) for automated table creation and schema validation.
Access: schema_fetcher = transformer.get_utility('schema_fetcher')
Use Cases:
- Automated schema discovery from legacy systems
- Schema migration from AS/400 to modern data platforms
- Schema validation before data loading
- Dynamic table creation based on source schemas
- Metadata extraction for data cataloging
Key Methods:
fetch_as400_schema(table_name, config)
Purpose: Fetch AS/400 (DB2) table schema with column metadata.
Parameters:
table_name: Name of the AS/400 table (case-sensitive)config: Dictionary with connection details:host: AS/400 server hostnamelibrary: AS/400 library nameuser: Database usernamepassword: Database password
Returns: Schema object with column definitions and data types
Example:
schema_fetcher = transformer.get_utility('schema_fetcher')
as400_config = {
'host': 'as400.company.com',
'library': 'PRODLIB',
'user': 'username',
'password': 'password'
}
schema = schema_fetcher.fetch_as400_schema('CUSTOMER', as400_config)
fetch_mariadb_schema(table_name, config)
Purpose: Fetch MariaDB/MySQL table schema with column metadata.
Parameters:
table_name: Name of the MariaDB tableconfig: Dictionary with connection details:host: MariaDB server hostnameport: Database port (default: 3306)database: Database nameuser: Database usernamepassword: Database password
Returns: Schema object with column definitions and data types
Example:
mariadb_config = {
'host': 'mariadb.company.com',
'port': 3306,
'database': 'production',
'user': 'username',
'password': 'password'
}
schema = schema_fetcher.fetch_mariadb_schema('customers', mariadb_config)
fetch_generic_schema(table_name, jdbc_url, properties, schema_query)
Purpose: Fetch schema from any JDBC-compatible database using custom SQL query.
Parameters:
table_name: Name of the tablejdbc_url: JDBC connection URLproperties: Dictionary of JDBC connection properties (user, password, driver, etc.)schema_query: SQL query to fetch schema information
Returns: Schema object with column definitions and data types
Example:
schema = schema_fetcher.fetch_generic_schema(
table_name='products',
jdbc_url='jdbc:postgresql://localhost:5432/mydb',
properties={
'user': 'user',
'password': 'pass',
'driver': 'org.postgresql.Driver'
},
schema_query="SELECT column_name, data_type FROM information_schema.columns WHERE table_name = 'products'"
)
Table Creator
Purpose: Create tables in target systems (Iceberg, Snowflake) based on schema definitions.
Access: table_creator = transformer.get_utility('table_creator')
Use Cases:
- Automated table creation from source schemas
- Data lake table setup (Bronze, Silver, Gold layers)
- Schema evolution and migration
- Multi-target table creation for data replication
- Initial data warehouse setup
Key Methods:
create_iceberg_table_direct(table_name, schema, catalog, database)
Purpose: Create Iceberg table directly in AWS Glue Data Catalog.
Parameters:
table_name: Name of the table to createschema: Schema object from schema fetchercatalog: Glue catalog name (typically 'glue_catalog')database: Database name in Glue catalog
Returns: Boolean indicating success
Example:
table_creator = transformer.get_utility('table_creator')
success = table_creator.create_iceberg_table_direct(
table_name='customers',
schema=schema,
catalog='glue_catalog',
database='bronze'
)
create_snowflake_table(table_name, schema, config, schema_name)
Purpose: Create Snowflake table with DDL generation.
Parameters:
table_name: Name of the table to createschema: Schema object from schema fetcherconfig: Snowflake connection configuration dictionary:sf_url: Snowflake account URLsf_user: Snowflake usernamesf_password: Snowflake passwordsf_database: Snowflake database namesf_warehouse: Snowflake warehouse namesf_role: Snowflake role name
schema_name: Snowflake schema name (e.g., 'BRONZE', 'GOLD')
Returns: Boolean indicating success
Example:
snowflake_config = {
'sf_url': 'https://account.snowflakecomputing.com',
'sf_user': 'username',
'sf_password': 'password',
'sf_database': 'PROD_DB',
'sf_warehouse': 'COMPUTE_WH',
'sf_role': 'DATA_ENGINEER'
}
success = table_creator.create_snowflake_table(
table_name='customers',
schema=schema,
config=snowflake_config,
schema_name='BRONZE'
)
Change Data Capture (CDC)
Delta Processor
Purpose: Process CDC delta files with deduplication and operation separation for efficient change data capture workflows.
Access: delta_processor = transformer.get_utility('delta_processor')
Use Cases:
- Processing incremental updates from source systems
- Handling CDC files from database replication
- Deduplicating records based on primary keys
- Separating inserts/updates from deletes for merge operations
- Processing batch delta files from multiple sources
Key Methods:
set_primary_key_mapping(table_name, primary_keys)
Purpose: Configure primary key mappings for table-specific deduplication.
Parameters:
table_name: Name of the tableprimary_keys: List of column names that form the primary key
Example:
delta_processor = transformer.get_utility('delta_processor')
delta_processor.set_primary_key_mapping('CUSTOMER', ['customer_id'])
delta_processor.set_primary_key_mapping('ORDER', ['order_id', 'line_item_id'])
process_table_batch(s3_bucket, prefix, table_name, rc_list, add_rccode)
Purpose: Process complete table batch with automatic deduplication and operation separation.
Parameters:
s3_bucket: S3 bucket name containing delta filesprefix: S3 prefix path (e.g., 'bronze', 'raw/cdc')table_name: Name of the table being processedrc_list: List of record codes to process (e.g., ['RC1', 'RC2'])add_rccode: Boolean to add record code column to output
Returns: Tuple of (upserts DataFrame, deletes DataFrame, statistics dictionary)
Example:
delta_processor = transformer.get_utility('delta_processor')
delta_processor.set_primary_key_mapping('CUSTOMER', ['customer_id'])
df_upserts, df_deletes, stats = delta_processor.process_table_batch(
s3_bucket='my-data-bucket',
prefix='bronze',
table_name='CUSTOMER',
rc_list=['RC1', 'RC2'],
add_rccode=True
)
# stats contains: {'upserts': count, 'deletes': count, 'total': count}
read_delta_files(s3_bucket, prefix, table_name, rc_list)
Purpose: Read and combine delta files from S3 into a single DataFrame.
Parameters:
s3_bucket: S3 bucket nameprefix: S3 prefix pathtable_name: Name of the tablerc_list: List of record codes to read
Returns: DataFrame with all delta records
Example:
df_raw = delta_processor.read_delta_files(
'my-bucket',
'bronze',
'CUSTOMER',
['RC1', 'RC2']
)
deduplicate_records(df, table_name)
Purpose: Deduplicate records based on configured primary key mappings.
Parameters:
df: Input DataFrame with potential duplicatestable_name: Table name for primary key lookup
Returns: Deduplicated DataFrame
Example:
df_deduped = delta_processor.deduplicate_records(df_raw, 'CUSTOMER')
separate_operations(df)
Purpose: Separate insert/update operations from delete operations based on operation codes.
Parameters:
df: Input DataFrame with operation codes
Returns: Tuple of (upserts DataFrame, deletes DataFrame)
Example:
df_upserts, df_deletes = delta_processor.separate_operations(df_deduped)
SCD Type 2 Processor
Purpose: Implement Slowly Changing Dimension Type 2 with effective dating and historical record preservation.
Access: scd_processor = transformer.get_utility('scd_processor')
Use Cases:
- Maintaining historical data changes in dimension tables
- Tracking customer or product attribute changes over time
- Implementing effective date ranges for temporal queries
- Preserving audit trails for regulatory compliance
- Building data warehouse dimension tables with versioning
Key Methods:
complete_scd_processing(df, business_key_columns, date_columns, time_columns, create_date_col, create_time_col, update_date_col, update_time_col)
Purpose: Complete end-to-end SCD Type 2 processing with all transformations.
Parameters:
df: Source DataFrame with dimension databusiness_key_columns: List of columns forming the business keydate_columns: List of date column names to formattime_columns: List of time column names to formatcreate_date_col: Name of creation date columncreate_time_col: Name of creation time columnupdate_date_col: Name of update date columnupdate_time_col: Name of update time column
Returns: DataFrame with SCD Type 2 columns (effective_date, end_date, is_current, etc.)
Example:
scd_processor = transformer.get_utility('scd_processor')
df_scd = scd_processor.complete_scd_processing(
df=source_df,
business_key_columns=['customer_id'],
date_columns=['create_date', 'update_date'],
time_columns=['create_time', 'update_time'],
create_date_col='create_date',
create_time_col='create_time',
update_date_col='update_date',
update_time_col='update_time'
)
format_date_columns(df, columns, format)
Purpose: Format date columns to standard format for SCD processing.
Parameters:
df: Input DataFramecolumns: List of date column namesformat: Source date format (e.g., 'yyyyMMdd', 'yyyy-MM-dd')
Returns: DataFrame with formatted date columns
Example:
df_with_dates = scd_processor.format_date_columns(
df,
['order_date'],
'yyyyMMdd'
)
format_time_columns(df, columns)
Purpose: Format time columns to standard format for SCD processing.
Parameters:
df: Input DataFramecolumns: List of time column names
Returns: DataFrame with formatted time columns
Example:
df_with_times = scd_processor.format_time_columns(df, ['order_time'])
calculate_effective_date(df, create_date_col, update_date_col)
Purpose: Calculate effective date for SCD Type 2 records.
Parameters:
df: Input DataFramecreate_date_col: Name of creation date columnupdate_date_col: Name of update date column
Returns: DataFrame with effective_date column
Example:
df_with_effective = scd_processor.calculate_effective_date(
df,
create_date_col='create_date',
update_date_col='update_date'
)
add_scd_ranking(df, business_keys)
Purpose: Add ranking for SCD logic to determine current vs historical records.
Parameters:
df: Input DataFramebusiness_keys: List of business key column names
Returns: DataFrame with ranking columns
Example:
df_with_ranking = scd_processor.add_scd_ranking(df, ['customer_id'])
apply_scd_type2_logic(df, business_keys)
Purpose: Apply SCD Type 2 logic to determine record versions and effective dates.
Parameters:
df: Input DataFramebusiness_keys: List of business key column names
Returns: DataFrame with SCD Type 2 columns applied
Example:
df_final = scd_processor.apply_scd_type2_logic(df, ['customer_id'])
get_current_records_only(df)
Purpose: Filter DataFrame to return only current (active) SCD Type 2 records.
Parameters:
df: SCD Type 2 DataFrame
Returns: DataFrame with only current records (is_current = True)
Example:
current_records = scd_processor.get_current_records_only(df_final)
Database Connections
Database Connector
Purpose: Manage database connections (AS/400, MariaDB, Generic JDBC) with connection pooling and query execution.
Access: db_connector = transformer.get_utility('database_connector')
Use Cases:
- Connecting to legacy AS/400 systems
- Reading data from MariaDB/MySQL databases
- Querying any JDBC-compatible database
- Bulk data extraction from source systems
- Schema discovery and metadata extraction
Key Methods:
configure_as400_connection(name, host, library, user, password)
Purpose: Configure and register an AS/400 (DB2) database connection.
Parameters:
name: Connection name identifierhost: AS/400 server hostname or IPlibrary: AS/400 library nameuser: Database usernamepassword: Database password
Example:
db_connector = transformer.get_utility('database_connector')
db_connector.configure_as400_connection(
name='prod_as400',
host='as400.company.com',
library='PRODLIB',
user='username',
password='password'
)
configure_mariadb_connection(name, host, port, database, user, password)
Purpose: Configure and register a MariaDB/MySQL database connection.
Parameters:
name: Connection name identifierhost: MariaDB server hostname or IPport: Database port (default: 3306)database: Database nameuser: Database usernamepassword: Database password
Example:
db_connector.configure_mariadb_connection(
name='prod_mariadb',
host='mariadb.company.com',
port=3306,
database='production',
user='username',
password='password'
)
test_connection(name)
Purpose: Test database connection to verify connectivity and credentials.
Parameters:
name: Connection name to test
Returns: Boolean indicating connection success
Example:
is_connected = db_connector.test_connection('prod_as400')
execute_query(connection_name, query)
Purpose: Execute SQL query and return results as DataFrame.
Parameters:
connection_name: Name of configured connectionquery: SQL query string
Returns: DataFrame with query results
Example:
df_result = db_connector.execute_query('prod_as400',
"SELECT * FROM CUSTOMER WHERE STATUS = 'ACTIVE'")
read_table(connection_name, table_name, columns, where_clause)
Purpose: Read entire table or filtered subset into DataFrame.
Parameters:
connection_name: Name of configured connectiontable_name: Name of table to readcolumns: List of column names to select (optional, None for all)where_clause: SQL WHERE clause for filtering (optional)
Returns: DataFrame with table data
Example:
df_customers = db_connector.read_table(
connection_name='prod_mariadb',
table_name='customers',
columns=['customer_id', 'name', 'email'],
where_clause="status = 'ACTIVE'"
)
get_table_schema(connection_name, table_name)
Purpose: Get table schema information including columns and data types.
Parameters:
connection_name: Name of configured connectiontable_name: Name of table
Returns: DataFrame with schema information
Example:
schema_df = db_connector.get_table_schema('prod_as400', 'CUSTOMER')
Snowflake Connector
Purpose: Manage Snowflake-specific connections and operations with optimized query execution and data loading.
Access: sf_connector = transformer.get_utility('snowflake_connector')
Use Cases:
- Loading data into Snowflake data warehouse
- Executing analytical queries in Snowflake
- Managing Snowflake table DDL operations
- Bulk data loading with staging tables
- Multi-schema operations across Snowflake databases
Key Methods:
configure_connection(name, sf_url, sf_user, sf_password, sf_database, sf_warehouse, sf_role, sf_schema)
Purpose: Configure and register a Snowflake connection with full account details.
Parameters:
name: Connection name identifiersf_url: Snowflake account URLsf_user: Snowflake usernamesf_password: Snowflake passwordsf_database: Snowflake database namesf_warehouse: Snowflake warehouse namesf_role: Snowflake role namesf_schema: Default schema name
Example:
sf_connector = transformer.get_utility('snowflake_connector')
sf_connector.configure_connection(
name='prod_snowflake',
sf_url='https://account.snowflakecomputing.com',
sf_user='username',
sf_password='password',
sf_database='PROD_DB',
sf_warehouse='COMPUTE_WH',
sf_role='DATA_ENGINEER',
sf_schema='BRONZE'
)
test_connection(name, method)
Purpose: Test Snowflake connection using specified method (JDBC or native).
Parameters:
name: Connection name to testmethod: Connection method ('jdbc' or 'native', default: 'jdbc')
Returns: Boolean indicating connection success
Example:
is_connected = sf_connector.test_connection('prod_snowflake', method='jdbc')
execute_query(connection_name, query)
Purpose: Execute SQL query in Snowflake and return results as DataFrame.
Parameters:
connection_name: Name of configured connectionquery: Snowflake SQL query string
Returns: DataFrame with query results
Example:
df_result = sf_connector.execute_query('prod_snowflake',
"SELECT * FROM BRONZE.CUSTOMERS WHERE STATUS = 'ACTIVE'")
write_dataframe(df, connection_name, table_name, schema_name, mode)
Purpose: Write DataFrame to Snowflake table with optimized bulk loading.
Parameters:
df: DataFrame to writeconnection_name: Name of configured connectiontable_name: Target table nameschema_name: Snowflake schema namemode: Write mode ('append', 'overwrite', 'merge')
Returns: Boolean indicating success
Example:
success = sf_connector.write_dataframe(
df=customers_df,
connection_name='prod_snowflake',
table_name='CUSTOMERS_STAGING',
schema_name='BRONZE',
mode='overwrite'
)
execute_ddl(connection_name, ddl_statement)
Purpose: Execute DDL statements in Snowflake (CREATE, ALTER, DROP, etc.).
Parameters:
connection_name: Name of configured connectionddl_statement: DDL SQL statement
Returns: Boolean indicating success
Example:
success = sf_connector.execute_ddl('prod_snowflake',
"CREATE OR REPLACE TABLE BRONZE.TEMP_TABLE AS SELECT * FROM BRONZE.CUSTOMERS")
Data Transformations
Data Formatter
Purpose: Advanced data formatting operations (dates, times, numerics, strings) with data quality rule enforcement.
Access: data_formatter = transformer.get_utility('data_formatter')
Use Cases:
- Standardizing date/time formats across sources
- Enforcing data quality rules and constraints
- Formatting numeric values with precision control
- Handling NULL values with default replacements
- Data cleansing and normalization
Key Methods:
apply_data_quality_rules(df, quality_rules)
Purpose: Apply data quality rules to DataFrame columns with validation and default value handling.
Parameters:
df: Input DataFramequality_rules: Dictionary mapping column names to quality rules:not_null: Boolean to enforce non-null valuesdefault_value: Default value for NULLsmin_value: Minimum value for numeric columnsmax_value: Maximum value for numeric columnspattern: Regex pattern for string validation
Returns: DataFrame with quality rules applied
Example:
data_formatter = transformer.get_utility('data_formatter')
df_formatted = data_formatter.apply_data_quality_rules(df_upserts, {
'customer_id': {'not_null': True, 'default_value': 'UNKNOWN'},
'amount': {'not_null': True, 'default_value': 0.0, 'min_value': 0},
'email': {'pattern': r'^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$'}
})
format_date_columns(df, columns, format)
Purpose: Format date columns to standard format with pattern matching.
Parameters:
df: Input DataFramecolumns: List of date column namesformat: Source date format pattern (e.g., 'yyyyMMdd', 'MM/dd/yyyy', 'yyyy-MM-dd')
Returns: DataFrame with formatted date columns
Example:
df_formatted = data_formatter.format_date_columns(
df,
['order_date', 'ship_date'],
'yyyyMMdd'
)
format_time_columns(df, columns)
Purpose: Format time columns to standard time format.
Parameters:
df: Input DataFramecolumns: List of time column names
Returns: DataFrame with formatted time columns
Example:
df_formatted = data_formatter.format_time_columns(df, ['order_time', 'process_time'])
format_numeric_columns(df, columns, precision, scale)
Purpose: Format numeric columns with specified precision and scale.
Parameters:
df: Input DataFramecolumns: List of numeric column namesprecision: Total number of digitsscale: Number of decimal places
Returns: DataFrame with formatted numeric columns
Example:
df_formatted = data_formatter.format_numeric_columns(
df,
['amount', 'price'],
precision=10,
scale=2
)
Column Sanitizer
Purpose: Column name sanitization and cleaning for target systems compatibility.
Access: column_sanitizer = transformer.get_utility('column_sanitizer')
Use Cases:
- Preparing column names for Iceberg/Snowflake ingestion
- Removing special characters incompatible with SQL
- Standardizing naming conventions across systems
- Handling reserved keywords in target databases
Note: Column sanitization is also available via the core clean_column_names() method which provides similar functionality.
Data Writers
Iceberg Writer
Purpose: Write data to Iceberg tables with CDC support, merge operations, and partition management.
Access: iceberg_writer = transformer.get_utility('iceberg_writer')
Use Cases:
- Loading data into data lake Bronze/Silver/Gold layers
- Performing CDC merge operations with upserts and deletes
- Incremental data loading with partition management
- Schema evolution and table maintenance
- Optimized writes for large datasets
Key Methods:
merge_cdc_data(df_upserts, df_deletes, table_name, database, primary_key_columns)
Purpose: Merge CDC data into Iceberg table handling both inserts/updates and deletes.
Parameters:
df_upserts: DataFrame with insert/update recordsdf_deletes: DataFrame with delete recordstable_name: Target Iceberg table namedatabase: Database name in Glue catalogprimary_key_columns: List of primary key column names
Returns: Dictionary with merge statistics (rows_written, rows_deleted, etc.)
Example:
iceberg_writer = transformer.get_utility('iceberg_writer')
iceberg_stats = iceberg_writer.merge_cdc_data(
df_upserts=df_quality,
df_deletes=df_deletes,
table_name='customer',
database='gold',
primary_key_columns=['customer_id']
)
append_data(df, table_name, database)
Purpose: Append data to existing Iceberg table.
Parameters:
df: DataFrame to appendtable_name: Target Iceberg table namedatabase: Database name in Glue catalog
Returns: Boolean indicating success
Example:
success = iceberg_writer.append_data(
df=df_new_records,
table_name='customer',
database='gold'
)
overwrite_data(df, table_name, database)
Purpose: Overwrite data in Iceberg table (replaces all existing data).
Parameters:
df: DataFrame to writetable_name: Target Iceberg table namedatabase: Database name in Glue catalog
Returns: Boolean indicating success
Example:
success = iceberg_writer.overwrite_data(
df=df_full_refresh,
table_name='customer',
database='gold'
)
Snowflake Writer
Purpose: Write data to Snowflake tables with optimized bulk loading and merge operations.
Access: snowflake_writer = transformer.get_utility('snowflake_writer')
Use Cases:
- Loading data into Snowflake data warehouse
- Incremental data updates with merge operations
- Bulk data loading with staging tables
- Multi-schema data distribution
- High-performance data ingestion
Key Methods:
write_dataframe(df, table_name, schema_name, connection_config, mode)
Purpose: Write DataFrame to Snowflake table with optimized bulk loading.
Parameters:
df: DataFrame to writetable_name: Target Snowflake table nameschema_name: Snowflake schema nameconnection_config: Snowflake connection configuration dictionarymode: Write mode ('append', 'overwrite', 'error')
Returns: Boolean indicating success
Example:
snowflake_writer = transformer.get_utility('snowflake_writer')
sf_success = snowflake_writer.write_dataframe(
df=df_quality,
table_name='CUSTOMER',
schema_name='GOLD',
connection_config=snowflake_config,
mode='append'
)
merge_data(df, table_name, schema_name, connection_config, merge_keys)
Purpose: Merge data into Snowflake table using specified merge keys.
Parameters:
df: DataFrame to mergetable_name: Target Snowflake table nameschema_name: Snowflake schema nameconnection_config: Snowflake connection configuration dictionarymerge_keys: List of column names for merge matching
Returns: Boolean indicating success
Example:
sf_success = snowflake_writer.merge_data(
df=df_updates,
table_name='CUSTOMER',
schema_name='GOLD',
connection_config=snowflake_config,
merge_keys=['customer_id']
)
Configuration & Monitoring
Configuration Manager
Purpose: Centralized configuration management with validation, type conversion, and multiple source support.
Access: config = transformer.get_utility('config_manager')
Use Cases:
- Loading configuration from AWS Glue job parameters
- Managing environment-specific settings
- Validating configuration before job execution
- Type-safe parameter retrieval with defaults
- Centralized connection configuration management
Key Methods:
load_glue_job_args(required_args, optional_args)
Purpose: Load configuration parameters from AWS Glue job arguments.
Parameters:
required_args: List of required parameter namesoptional_args: List of optional parameter names
Example:
config = transformer.get_utility('config_manager')
config.load_glue_job_args(
required_args=["SF_URL", "SF_USER", "SF_PASSWORD"],
optional_args=["S3_BUCKET", "TABLE_LIST", "DEBUG_MODE"]
)
load_environment_variables(mapping)
Purpose: Load configuration from environment variables with custom naming.
Parameters:
mapping: Dictionary mapping internal names to environment variable names
Example:
config.load_environment_variables({
'db_host': 'DB_HOST',
'db_port': 'DB_PORT',
'api_key': 'API_KEY'
})
load_json_config(path)
Purpose: Load configuration from JSON file.
Parameters:
path: Path to JSON configuration file (local or S3)
Example:
config.load_json_config('s3://my-bucket/config/production.json')
get_param(name, default, type)
Purpose: Get parameter value with type conversion and default fallback.
Parameters:
name: Parameter namedefault: Default value if parameter not foundtype: Type to convert to (int, str, bool, list, dict, etc.)
Returns: Typed parameter value
Example:
batch_size = config.get_param('BATCH_SIZE', 1000, int)
debug_mode = config.get_param('DEBUG_MODE', False, bool)
table_list = config.get_param('TABLE_LIST', [], list)
get_connection_config(connection_type)
Purpose: Get connection configuration for specified connection type.
Parameters:
connection_type: Connection type ('snowflake', 'as400', 'mariadb', etc.)
Returns: Dictionary with connection configuration
Example:
snowflake_config = config.get_connection_config("snowflake")
# Returns: {'sf_url': ..., 'sf_user': ..., etc.}
get_s3_config()
Purpose: Get S3 configuration (bucket, prefix, etc.).
Returns: Dictionary with S3 configuration
Example:
s3_config = config.get_s3_config()
# Returns: {'s3_bucket': ..., 's3_prefix': ..., etc.}
validate_all(type_mapping)
Purpose: Validate all configuration parameters against expected types.
Parameters:
type_mapping: Dictionary mapping parameter names to expected types
Returns: Tuple of (is_valid: bool, errors: list)
Example:
is_valid, errors = config.validate_all({
'BATCH_SIZE': int,
'DEBUG_MODE': bool,
'TABLE_LIST': list
})
if not is_valid:
raise ValueError(f"Configuration errors: {errors}")
Performance Monitor
Purpose: Comprehensive job performance tracking with memory monitoring, operation timing, and detailed reporting.
Access: monitor = transformer.get_utility('performance_monitor') or monitor = transformer.get_performance_monitor()
Use Cases:
- Tracking ETL job execution time
- Identifying performance bottlenecks
- Monitoring memory usage during processing
- Tracking DataFrame operation statistics
- Generating performance reports for optimization
Key Methods:
time_operation(name)
Purpose: Context manager for timing operations with automatic start/stop.
Parameters:
name: Operation name identifier
Example:
monitor = transformer.get_performance_monitor()
with monitor.time_operation("data_processing"):
df_result = transformer.execute_sql_block(complex_query, dataframes)
start_timer(name) / stop_timer(name)
Purpose: Manually start and stop timers for operations.
Parameters:
name: Operation name identifier
Returns: Duration in seconds (for stop_timer)
Example:
monitor.start_timer('data_extraction')
# ... perform operation ...
duration = monitor.stop_timer('data_extraction')
track_dataframe_operation(operation_name, df_before, df_after, operation_type)
Purpose: Track DataFrame operations with before/after statistics.
Parameters:
operation_name: Name of the operationdf_before: DataFrame before operationdf_after: DataFrame after operationoperation_type: Type of operation (e.g., 'JOIN', 'FILTER', 'TRANSFORM')
Example:
monitor.track_dataframe_operation(
"customer_join",
df_before=orders_df,
df_after=joined_df,
operation_type="JOIN"
)
record_data_stats(name, stats)
Purpose: Record custom metrics and statistics.
Parameters:
name: Metric name identifierstats: Dictionary with metric values
Example:
monitor.record_data_stats("final_output", {
"rows_processed": len(df_result),
"tables_updated": 3,
"error_count": 0,
"processing_time_minutes": 15.5
})
generate_summary_report()
Purpose: Generate comprehensive performance summary report.
Returns: Dictionary with summary statistics
Example:
summary = monitor.generate_summary_report()
# Returns: {'total_time': ..., 'operations': ..., 'memory_usage': ..., etc.}
get_operation_breakdown()
Purpose: Get detailed breakdown of all timed operations.
Returns: Dictionary with operation timings
Example:
breakdown = monitor.get_operation_breakdown()
# Returns: {'operation1': duration1, 'operation2': duration2, ...}
get_slowest_operations(top_n)
Purpose: Get list of slowest operations for bottleneck identification.
Parameters:
top_n: Number of slowest operations to return
Returns: List of (operation_name, duration) tuples
Example:
slowest_ops = monitor.get_slowest_operations(top_n=5)
# Returns: [('complex_join', 120.5), ('data_validation', 45.2), ...]
export_metrics(path)
Purpose: Export all metrics to JSON file.
Parameters:
path: File path for metrics export
Returns: Path to exported file
Example:
export_path = monitor.export_metrics('/tmp/job_metrics.json')
finalize_job()
Purpose: Finalize job monitoring and generate comprehensive final report.
Returns: Dictionary with complete job statistics and report
Example:
final_report = monitor.finalize_job()
# Returns comprehensive report with all metrics, timings, and statistics
Complete Usage Patterns
1. Full ETL Pipeline with CDC
from etlToolkit import GlueTransformationsUtil
# Initialize with comprehensive utilities
transformer = GlueTransformationsUtil(spark_session)
# Configuration management
config = transformer.get_utility('config_manager')
config.load_glue_job_args(['S3_BUCKET', 'TABLE_LIST', 'SF_URL', 'SF_USER', 'SF_PASSWORD'])
# Performance monitoring
monitor = transformer.get_performance_monitor()
with monitor.time_operation('full_etl_pipeline'):
# Get configurations
s3_config = config.get_s3_config()
snowflake_config = config.get_connection_config('snowflake')
table_list = config.get_param('TABLE_LIST', [], list)
# Process each table
for table_name in table_list:
with monitor.time_operation(f'process_table_{table_name}'):
# Delta processing
delta_processor = transformer.get_utility('delta_processor')
df_upserts, df_deletes, stats = delta_processor.process_table_batch(
s3_bucket=s3_config['s3_bucket'],
prefix='bronze',
table_name=table_name,
rc_list=['RC1', 'RC2']
)
# Data transformations
df_clean = transformer.clean_column_names(df_upserts)
df_typed = transformer.change_column_types(df_clean, {
'customer_id': 'string',
'order_date': 'date',
'amount': 'double'
})
# Data quality
data_formatter = transformer.get_utility('data_formatter')
df_quality = data_formatter.apply_data_quality_rules(df_typed, {
'customer_id': {'not_null': True, 'default_value': 'UNKNOWN'},
'amount': {'not_null': True, 'default_value': 0.0}
})
# Write to Iceberg
iceberg_writer = transformer.get_utility('iceberg_writer')
iceberg_stats = iceberg_writer.merge_cdc_data(
df_upserts=df_quality,
df_deletes=df_deletes,
table_name=table_name,
database='gold',
primary_key_columns=['customer_id']
)
# Write to Snowflake
snowflake_writer = transformer.get_utility('snowflake_writer')
sf_success = snowflake_writer.write_dataframe(
df=df_quality,
table_name=table_name.upper(),
schema_name='GOLD',
connection_config=snowflake_config,
mode='append'
)
# Record statistics
monitor.record_data_stats(f'{table_name}_processing', {
'upserts': stats['upserts'],
'deletes': stats['deletes'],
'iceberg_success': bool(iceberg_stats),
'snowflake_success': sf_success
})
# Generate final report
final_report = monitor.finalize_job()
2. Pandas Data Processing
from etlToolkit import GlueTransformationsUtil
# Works without Spark session
transformer = GlueTransformationsUtil()
# Check capabilities
if not transformer.is_spark_available():
print("Using Pandas-only mode")
# Read data
df = pd.read_csv('input.csv')
# All core transformations work with Pandas
df_typed = transformer.change_column_types(df, {'date_col': 'date'})
df_clean = transformer.clean_column_names(df_typed)
# Generate unique identifiers
df_with_id = transformer.generate_uid_column(df_clean, 'record_uuid', 'uuid')
# Join operations
lookup_df = pd.read_csv('lookup.csv')
df_final = transformer.perform_join(df_with_id, lookup_df, 'key', join_type='left')
# Union multiple DataFrames
combined_df = transformer.perform_union([df_final, historical_df], union_type='union_distinct')
Supported Data Types & Operations
Data Types
string- Text/varchar datainteger- 32-bit integerslong- 64-bit integersdouble- Double precision floating pointboolean- True/false valuesdate- Date only (YYYY-MM-DD)timestamp- Date and time with timezonedecimal- Fixed precision decimal numbers
Join Types
inner- Returns only matching records from both DataFramesleft- Returns all records from left DataFrame, matched from rightright- Returns all records from right DataFrame, matched from leftouter- Returns all records when there's a match in either DataFrame
Union Types
union- Standard union (may remove duplicates in Spark)union_all- Union all rows (preserves duplicates)union_distinct- Union with explicit duplicate removal
UID Types
uuid- UUID4 format (e.g., '550e8400-e29b-41d4-a716-446655440000')monotonic- Monotonically increasing integerstimestamp_based- Timestamp combined with sequence number
Compatibility & Requirements
AWS Glue Version Support
- AWS Glue 3.0: Fully supported (Python 3.7+)
- AWS Glue 4.0: Fully supported (Python 3.8+) - Recommended
- AWS Glue 5.0: Fully supported (Python 3.9+)
Dependencies
- Required: Python 3.7+, pandas
- Optional: pyspark, awsglue, snowflake-connector-python, requests, psutil
Best Practices
- Initialize once and reuse the transformer instance
- Use performance monitoring for production jobs
- Validate configurations before processing
- Handle errors gracefully with proper logging
- Take advantage of specialized utilities for complex operations
- Use appropriate data types for optimal performance
- Monitor resource usage in distributed environments
- Follow camelCase naming conventions for consistency
How to use
- Attach the library to the required job.
- In the job script, initiate the library as follows:
# Import
from etlToolkit import GlueTransformationsUtil
# Initialize with Spark session - enables all utilities
# spark_session should be initialized to load the corresponding tools and utilities
transformer = GlueTransformationsUtil(spark_session)
# Or Initialize for Python shell jobs
transformer_pythonboot = GlueTransformationsUtil()
User can also use python's helper module in the following way in the script to get a comprehensive user guide.
help(etlToolkit)