ArcGIS Datasource
ArcGIS datasources allow you to connect to ArcGIS Online to discover, catalog, and ingest geospatial data and metadata from various ArcGIS item types.
The datasource enables you to:
- Discover and catalog ArcGIS items from multiple supported types
- Extract comprehensive metadata from ArcGIS items including technical, business and operational metadata
- Ingest actual geospatial data from Feature Services with advanced filtering capabilities
- Apply sophisticated filtering using groups, organizations and many more custom filters
- Track relationships between ArcGIS items and their dependencies
- Support both metadata-only and metadata-and-data ingestion workflows
Supported ArcGIS Item Types
The following ArcGIS item types are supported for discovery and metadata cataloging:
- Hub Site Application - ArcGIS Hub site applications
- Hub Page - Individual pages within ArcGIS Hub sites
- Dashboard - ArcGIS Dashboards for data visualization
- Web Experience - ArcGIS Experience Builder applications
- Web Map - Interactive web maps
- Feature Service - Geospatial data services (supports data ingestion)
Currently, only Feature Service items support actual data ingestion. Other item types support metadata cataloging only.
How to create an ArcGIS Datasource?
In order to create ArcGIS datasource, Users need to whitelist the below domain in the whitelisted domains list.
- .arcgis.com
Users should whitelist other domains/sub-domains based on the requirement.
- Go to Navigation Menu, then click on the Data Workflows tab and then select the Datasources button.
- Click on the + Create Datasource button on the top right corner of the page.
To create a ArcGIS datasource, input the below details shown in the table or you can directly upload the JSON data.
Metadata
| Name | Description |
|---|---|
| Datasource Name | Give the datasource a unique name |
| Description | Add datasource description |
| Keywords | Add keyword tags to connect it with other Amorphic components. |
| Datasource Type | Type of datasource. In this case it is ArcGIS |
Datasource Configuration
| Configuration | Description |
|---|---|
| Endpoint URL | The URL of the ArcGIS online account to connect to. Must be a valid HTTPS URL without trailing slash. |
| Authentication Method | Choose the authentication method: ApiKey or OAuth2 |
| Authentication Configuration | Configuration specific to the selected authentication method (see details below) |
| Connection Accessibility | Choose the connection accessibility: Public (yes) or Private (no). Public accessibility is recommended for ArcGIS Online. |
| Filters | Optional filters to discover specific items. See detailed filter options below. |
For private accessibility to work user need to whitelist these two domains in the whitelisted domains list.
- .pypi.org
- .pythonhosted.org
Authentication Methods
API Key Authentication:
- KeyValue: Your ArcGIS API key or token (required, non-empty string)
OAuth2 Authentication:
- ClientId: OAuth2 client identifier (required, non-empty string)
- ClientSecret: OAuth2 client secret (required, non-empty string)
Authentication credentials are securely stored in AWS Systems Manager Parameter Store and are not visible in the datasource configuration after creation.
Filters
These are optional filters that can be used to filter the items fetched from the ArcGIS online. All filter values must be URL-encoded.
| Filter | Description | Example |
|---|---|---|
| groups | JSON array of group objects. Each group must have either id OR both title and owner. | [{"id": "8a906fdd276f4de8bc3f84409ab04cb5"}, {"title": "My Group", "owner": "username"}] |
| orgid | Organization ID to limit search to specific organization items. | eg. lQySeXwbCg63XWTi |
| bbox | Bounding box in format: xmin,ymin,xmax,ymax to limit geographic search area. | -118,32,-116,34 |
| categories | Comma-separated list of up to 8 organization content categories. | "/Categories/Water", "/Categories/Forest" |
| category_filter | Comma-separated list of up to 3 category terms for matching. | basemap,reference,topographic |
| max_items | Maximum number of items to fetch (1-10000). | 100 |
| filter | JSON object with advanced search criteria. Supported keys: title, tags, typeKeywords, type, owner. | {"type": "\"Feature Service\" OR \"Web Map\"", "owner": "myuser", "tags": "wastewater", "typeKeywords": "ArcGIS Server", "title": "Address Data Exporter"} |
How to create a dataflow to ingest ArcGIS items?
ArcGIS datasource version 2.0 introduces support for CDC (Change Data Capture) and Full-Load-and-CDC process types. These features enable incremental data synchronization, allowing you to track and ingest only changed records from your ArcGIS Feature Services.
If you have an existing datasource with version 1.0, you must either create a new datasource or upgrade your existing datasource to version 2.0 to use CDC process types.
Go to Dataflows tab on the datasource details page and click on the + Add Dataflow button.
Fill in the details as shown in the table below and click on the "Create" button.
Step 1: Dataflow Details
| Details | Description |
|---|---|
| Dataflow Name | Give the dataflow a unique name (must be unique within the datasource) |
| Dataflow Description | Add a description for the dataflow (optional) |
| Ingestion Type | Choose the ingestion type: metadata-only or metadata-and-data |
| Process Type | Choose the process type: Full Load, CDC, or Full-Load-and-CDC. Required for every dataflow; for metadata-only use Full Load. For metadata-and-data, choose Full Load, CDC, or Full-Load-and-CDC. |
| Target Location | Choose the target location for the dataflow: S3, S3 Athena, Redshift, Lakeformation (required for metadata-and-data) |
| Advanced Filters | Advanced regex-based filters to filter items by type and properties (optional, base64 encoded) |
Ingestion Types
Metadata-Only:
- Catalogs item metadata
- Supports all ArcGIS item types
- Target location defaults to DynamoDB
- Faster processing, minimal storage requirements
Metadata-and-Data:
- Catalogs metadata AND ingests actual geospatial data
- Only supports Feature Service items with layers
- Requires target location selection
- Creates datasets for each Feature Service layer
Process Types
CDC and Full-Load-and-CDC process types require ArcGIS datasource version 2.0 or higher. If you have an existing datasource with version 1.0, you must either:
- Create a new datasource (which will default to version 2.0), or
- Upgrade your existing datasource to version 2.0
Full Load:
- Performs a complete data ingestion of all records from the Feature Service layer
- Suitable for initial data load or periodic full refreshes
- No incremental tracking - each run processes all data
- Recommended for one-time or infrequent data synchronization
CDC (Change Data Capture):
- Ingests only changed records since the last ingestion
- Requires ChangeTracking to be enabled on the Feature Service layer
- Uses server generation tracking (ServerGen) to identify changes
- Adds an Op column to track operation type: "I" (Insert), "U" (Update), or "D" (Delete)
- Requires a schedule to be created before starting the dataflow
- Recommended for continuous synchronization of frequently changing data
- Minimum schedule rate: Determined by your ArcGIS Feature Service capabilities
Full-Load-and-CDC:
- Performs a full load on the first run, then switches to CDC mode for subsequent runs
- First run: Ingests all records with Op="I" (Insert)
- Subsequent runs: Only ingests changed records with appropriate Op values
- Requires ChangeTracking to be enabled on the Feature Service layer
- Uses server generation tracking (ServerGen) to identify changes
- Adds an Op column to track operation type
- Requires a schedule to be created before starting the dataflow
- Recommended when you need an initial full load followed by incremental updates
- Minimum schedule rate: Determined by your ArcGIS Feature Service capabilities
For CDC and Full-Load-and-CDC process types, the CDC Tracking Method is set to ServerGen by default in the UI. This method uses ArcGIS server generation tracking to identify changes in the Feature Service. Other methods (e.g. CDCMarker, CustomColumn) may be available via API for advanced use.
How Data Appears in Datasets
The data structure in your datasets varies based on the process type:
Full Load:
- All records are ingested as new records
- No operation tracking column
- Each run appends all records from the Feature Service layer
CDC:
- Only changed records are ingested
- Includes an Op column with values:
- "I" - New records (inserts)
- "U" - Modified records (updates)
- "D" - Deleted records
- For updates and deletes, the record includes all fields from the Feature Service
- Data accumulates incrementally based on changes detected
Full-Load-and-CDC:
- First run: All records with Op="I" (full load)
- Subsequent runs: Only changed records with Op="I", "U", or "D"
- Includes an Op column for all records
- Combines initial full load with ongoing incremental updates
Advanced Filters:
Advanced filters provide additional refinement capabilities beyond basic datasource filters by allowing you to apply regex patterns to filter ArcGIS items based on their type and properties. The intuitive UI interface enables you to create multiple filter configurations for different item types (Hub Site Application, Feature Service, Web Map, etc.) with custom key-value pairs, where you can specify field names and corresponding regex patterns to precisely control which items are discovered and processed during ingestion.
You can use AllItems as an ItemType to apply filters to all item types. This is useful when you want to apply common filtering criteria across all ArcGIS item types.
Advanced filters use a multi-layered filtering approach where different item types have specific criteria applied. For example:
- For Hub Site Applications, if "wastewater" tags are specified in the filters, then only items tagged with "wastewater" will be included in the discovery process.
- For Hub Pages, if a description filter is specified with a regex pattern matching "health", then only items with descriptions containing the word "health" will be included in the discovery process.
- For Feature Services, if tags and title filters are specified (e.g., "census" tags AND titles containing "age" or "technology"), then only items matching both criteria will be included in the discovery process.
The below image demonstrates the advanced filters configuration:
This granular filtering ensures that only the most relevant items matching your specific requirements are discovered and available for selection during the ingestion process.
If user wants to filter only the following items:
- Feature Services that have "population" or "census" in their title
- Hub Site Applications that are owned by specific users
- Web Maps that have certain tags
Then user can configure the advanced filters as follows:
| Item Type | Key | Value | Description |
|---|---|---|---|
| Feature Service | title | .*(?:population|census).* | Matches titles containing "population" OR "census" |
| Hub Site Application | owner | ^(john.doe|jane.smith)$ | Matches items owned by "john.doe" OR "jane.smith" |
| Web Map | tags | .*(?:demographics|survey).* | Matches items tagged with "demographics" OR "survey" |
Additional Examples:
- Filter by access level: Use field
accesswith patternpublicto match items with public access level - Filter by description content: Use field
descriptionwith pattern.*(?:environmental|climate).*to match items with environmental or climate-related keywords in the descriptions
Advanced filters are applied AFTER the basic datasource filters, providing additional refinement of the discovered items. The filters use case-insensitive regex matching.
After filling in the details, click on the "Continue" button to proceed to the next step.
Step 2: Select ArcGIS Items
In this step, you can select the ArcGIS items to ingest. The system will query your ArcGIS online account using the datasource filters and any advanced filters to discover available items.
Selection Process:
- Items are organized by type and displayed with their titles and IDs
- Select items by clicking the checkbox next to each item
- For Feature Service items (metadata-and-data ingestion only):
- Expand the Feature Service to view available layers
- Each layer shows its name and schema information
- Select individual layers for data ingestion
- Layer schema is automatically detected and displayed
CDC Configuration (for CDC and Full-Load-and-CDC process types only):
When using CDC or Full-Load-and-CDC process types, you can configure additional CDC settings for each Feature Service layer:
| Field | Description | Default | Required |
|---|---|---|---|
| Enable Global ID | Include the GlobalID field in the dataset. GlobalID is required for CDC merging in Redshift target location. | Enabled (true) | Optional |
| Enable Editor Tracking | Include editor tracking fields (CreationDate, Creator, EditDate, Editor) in the dataset | Enabled (true) | Optional |
If you selected CDC or Full-Load-and-CDC as the Process Type, ChangeTracking must be enabled on all Feature Service layers you select. The system will validate this requirement during dataset registration. If ChangeTracking is not enabled on any selected layer, the dataflow creation will fail with an error message indicating which Feature Services need ChangeTracking enabled.
To enable ChangeTracking on your ArcGIS Feature Service:
- Open your Feature Service in ArcGIS Online
- Navigate to the Feature Service settings
- Enable the "Keep track of changes to the data (add, update, delete features)" capability
- Save the changes
This requirement ensures that the system can track changes (inserts, updates, deletes) for incremental data synchronization.
After selecting the items and layers, click on the "Continue" button to proceed to the next step.
Step 3: Configure Selected Items
In this step, you can configure the selected items for data ingestion.
For Metadata-Only Ingestion:
- No additional configuration required
- Items will be cataloged with their existing metadata
For Metadata-and-Data Ingestion (Feature Service layers only):
Each selected Feature Service layer requires dataset configuration:
| Field | Description | Required |
|---|---|---|
| Dataset Name | Unique name for the dataset within the domain | Yes |
| Domain | Target domain for the dataset (must have editor access) | Yes |
| Description | Dataset description | Optional |
| Keywords | Tags for dataset discovery and organization | Optional |
- Ingestion Filtering Configuration (API Only)
This is an optional configuration that can be used to filter the data ingested into the dataset.
Ingestion Config:
| Field | Description | Required |
|---|---|---|
| MaxRecords | The maximum number of records to ingest | Optional |
| StartOffset | The offset to start ingesting from | Optional |
| ColumnFilters | Object containing LogicalOperator and Filters for data filtering | Optional |
ColumnFilters Object (inside IngestionConfig):
| Field | Description | Required |
|---|---|---|
| LogicalOperator | The logical operator to use for combining filters (e.g., "AND", "OR") | Optional |
| Filters | Array of Filter Objects (see structure below) | Yes |
Filter Object Structure (inside ColumnFilters.Filters):
| Field | Description | Required |
|---|---|---|
| ColumnName | Name of the column to filter on | Yes |
| Operator | Comparison operator: =, !=, >, <, >=, <=, LIKE, IS NULL, IS NOT NULL | Yes |
| ColumnValue | Value to compare against | Yes |
Example Payload:
A city planning department wants to ingest traffic incident data from their ArcGIS Feature Service layer "Traffic_Incidents". They want to:
- Skip the first 5 records (StartOffset: 5)
- Limit ingestion to maximum 50 records (MaxRecords: 50)
- Filter to only include incidents that are currently active and have a severity level of greater than 10
{
"DataflowType": "arcgis",
"DataflowName": "Traffic_Incidents",
"IngestionType": "metadata-and-data",
"DataflowConfig": {
"IngestionType": "metadata-and-data",
"TargetLocation": "s3athena"
},
"ItemsConfig": {
"ItemType": "Feature Service",
"ItemDetails": {
"ItemId": "Traffic_Incidents",
"LayerId": 0,
"DatasetConfig": {
"DatasetName": "Traffic_Incidents",
"Description": "Traffic Incidents",
"Domain": "traffic",
"Keywords": ["Traffic", "Incidents"]
},
"IngestionConfig": {
"MaxRecords": 50,
"StartOffset": 5,
"ColumnFilters": {
"LogicalOperator": "AND",
"Filters": [
{ "ColumnName": "status", "Operator": "=", "ColumnValue": "active" },
{ "ColumnName": "severity", "Operator": ">", "ColumnValue": "10" }
]
}
}
}
}
}
Use the "Bulk Configure" feature to configure multiple datasets simultaneously:
- Dataset Prefix/Suffix: Apply common naming patterns
- Domain: Set the same domain for all datasets
- Description: Apply common description template
- Keywords: Add common tags to all datasets
This feature significantly speeds up configuration when working with multiple Feature Service layers.
After configuring the items, click on the "Create Dataflow" button to create the dataflow. The dataflow creation will start in the background and you can see the status of the dataflow on the dataflows tab.
How to start a dataflow to ingest ArcGIS items?
Once the dataflow is created, you can see details of the dataflow on the dataflows tab.
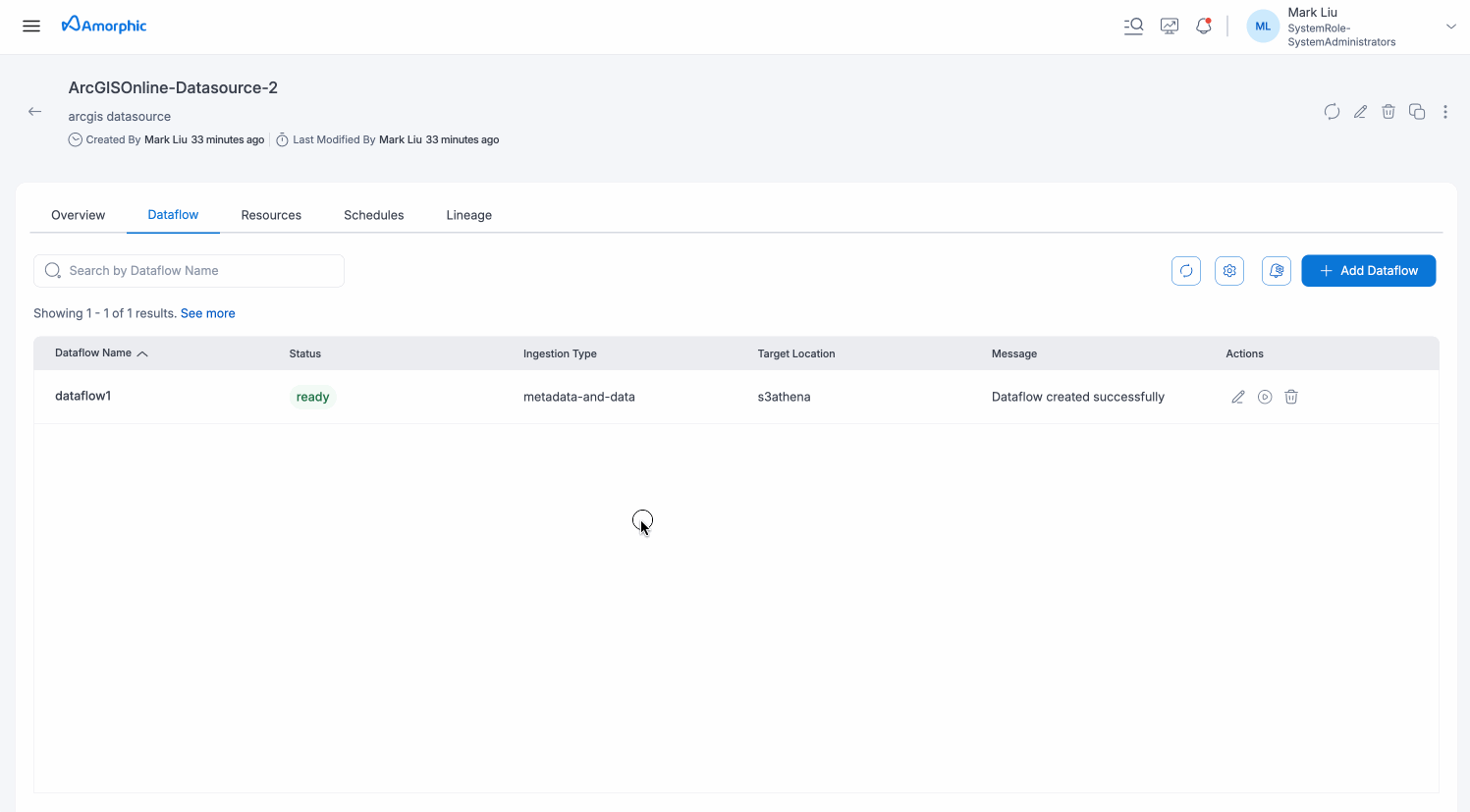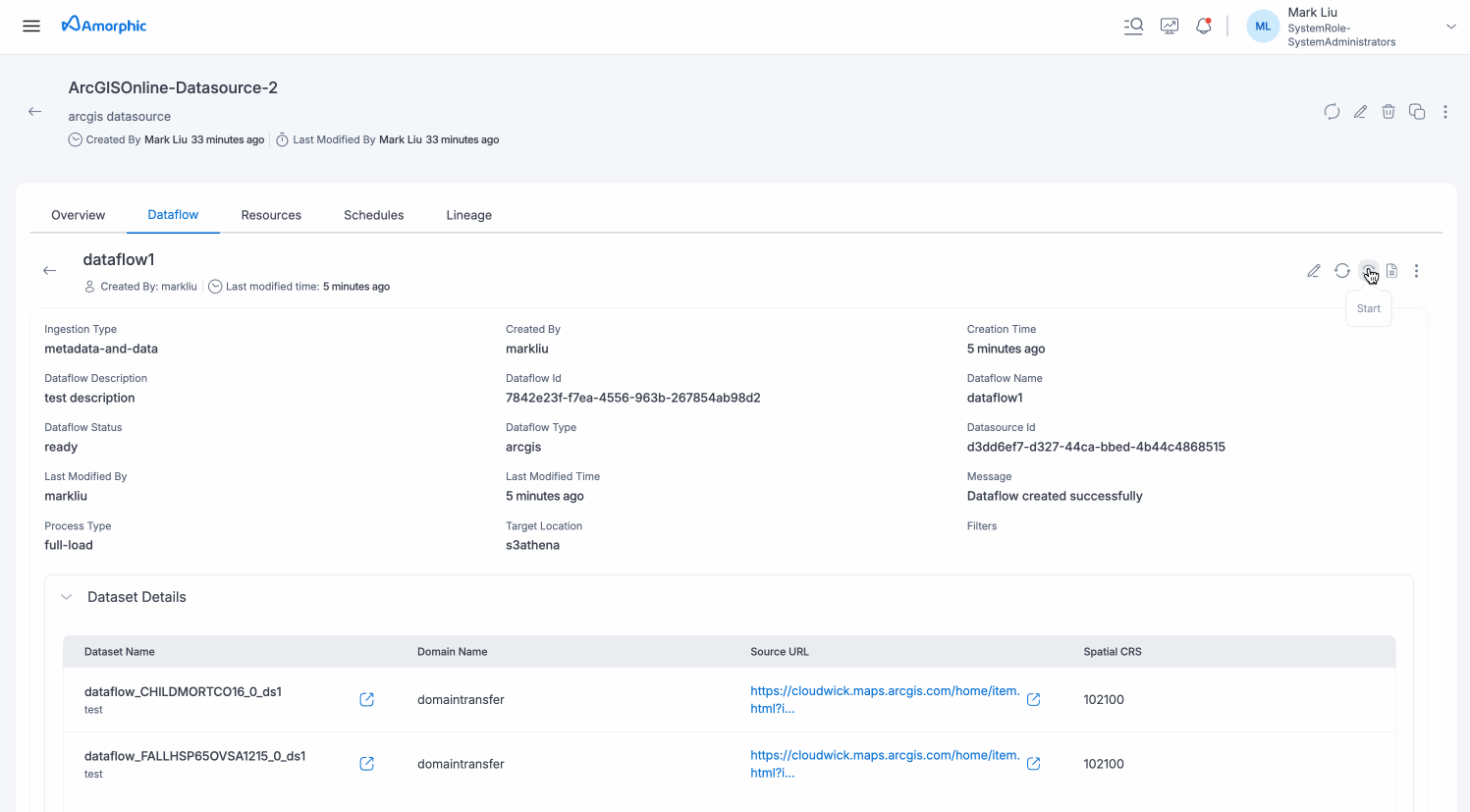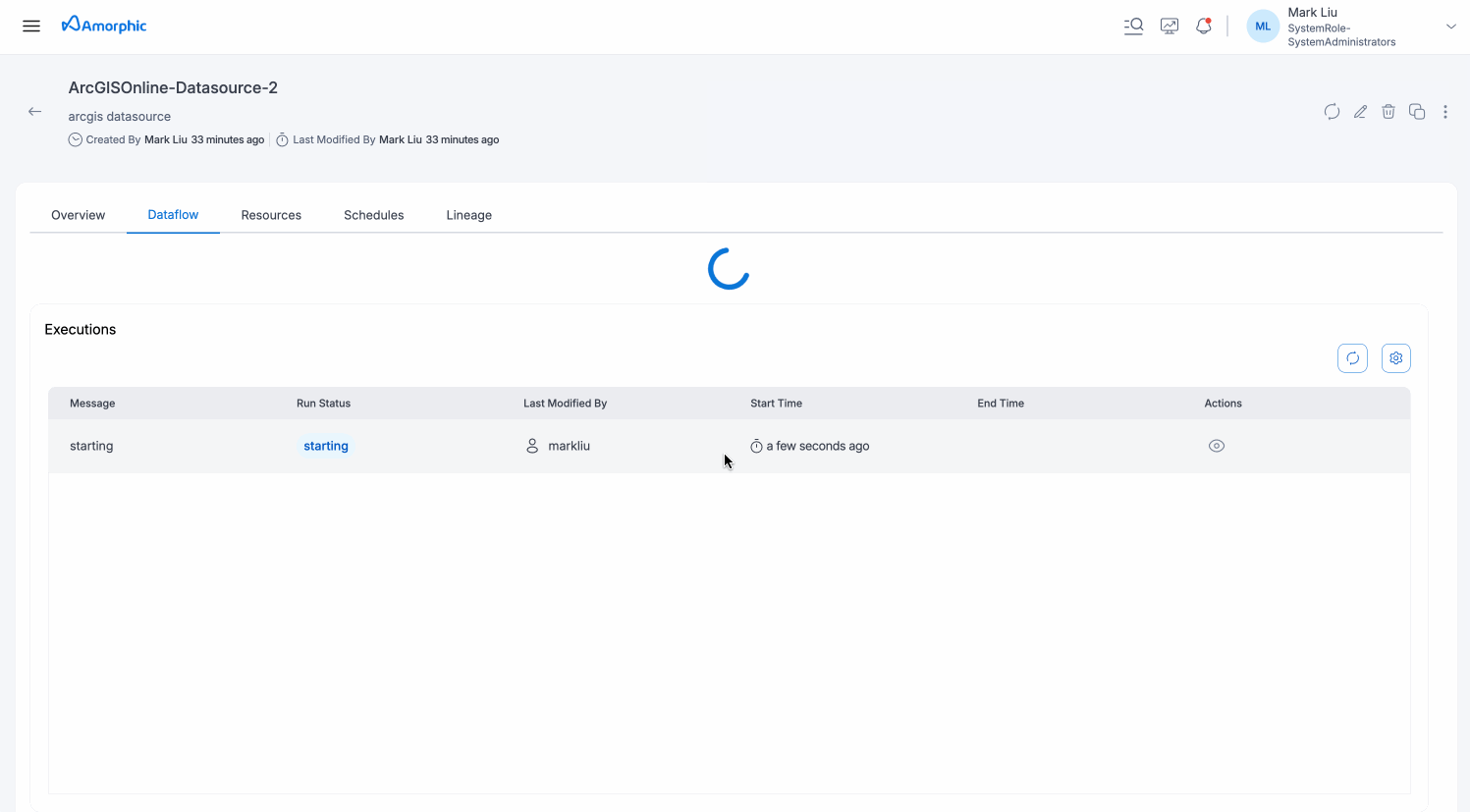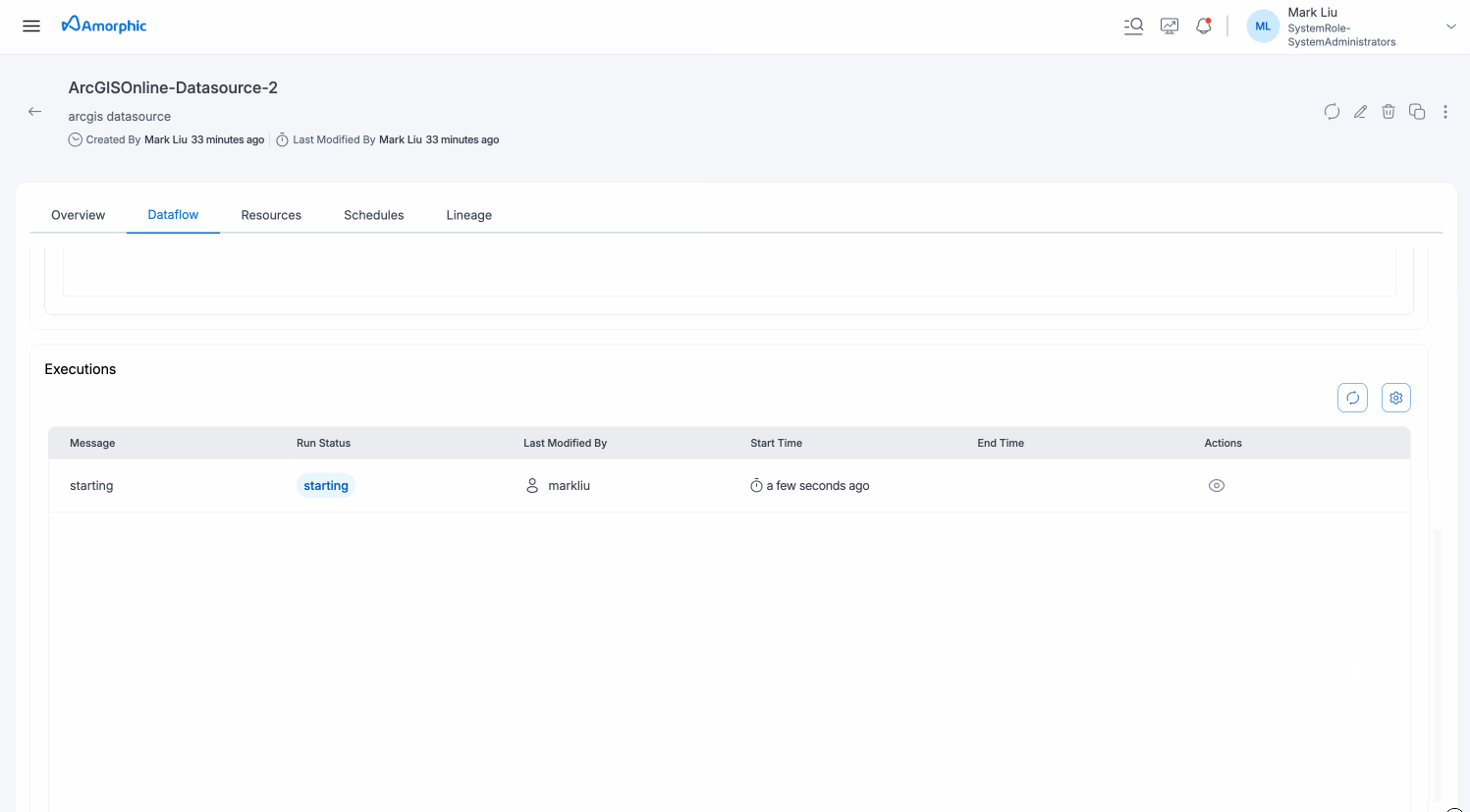
- Navigate to the dataflows tab on the datasource details page
- Click the "Start" button in the actions column for the desired dataflow
- The dataflow will begin execution in the background
For CDC and Full-Load-and-CDC process types:
- You must create a schedule first before starting the dataflow
- The schedule must use job type arcgis-incremental
- The dataflow may show a cdc-scheduled status until the first run is triggered
Monitoring Dataflow Execution
Dataflow Details Page:
- Click on the dataflow name to view detailed information
- Shows basic dataflow configuration and status
- Displays registered datasets in Dataset Details section(for metadata-and-data ingestion)
- Click dataset names to navigate to dataset details
Logs:
Monitor and troubleshoot dataflow executions by downloading detailed logs. To access logs:
- Navigate to the dataflow details page
- Click the three-dot menu icon (⋮) in the top right corner
- Select "View Logs" to see available log options
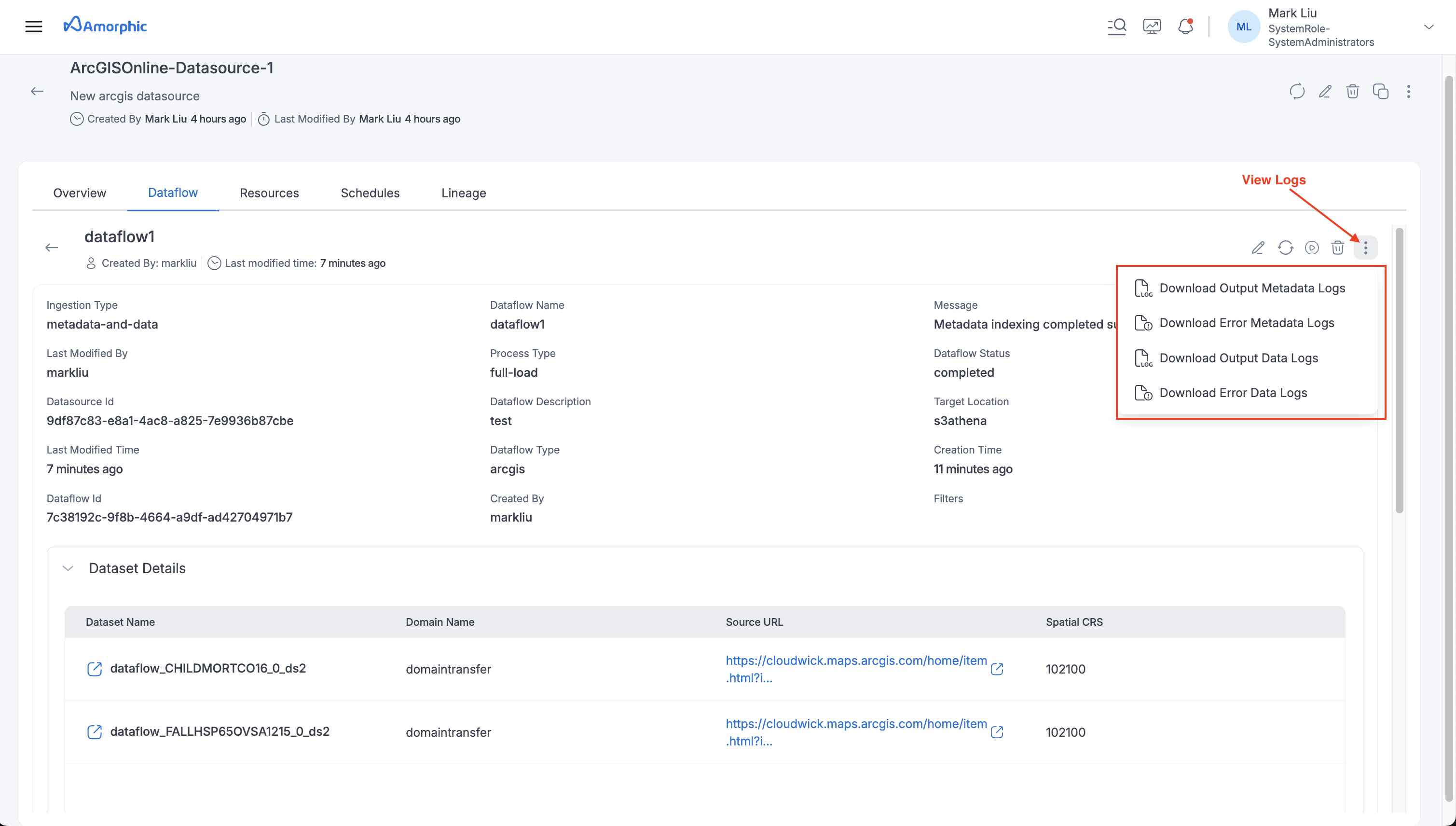
Available Log Types:
For Metadata-Only Ingestion:
- Output Metadata Logs: Contains metadata extraction details, item discovery information, and processing status
- Error Metadata Logs: Captures any errors or warnings encountered during metadata cataloging
For Metadata-and-Data Ingestion:
- Output Metadata Logs: Contains metadata extraction details and item discovery information
- Error Metadata Logs: Captures metadata-related errors or warnings
- Output Data Logs: Contains data ingestion details, record counts, and dataset creation information
- Error Data Logs: Captures data ingestion errors, schema validation issues, and transformation failures
Logs are useful for debugging failed executions, monitoring ingestion progress, and understanding data quality issues. Check Error Logs first when troubleshooting failed dataflows.
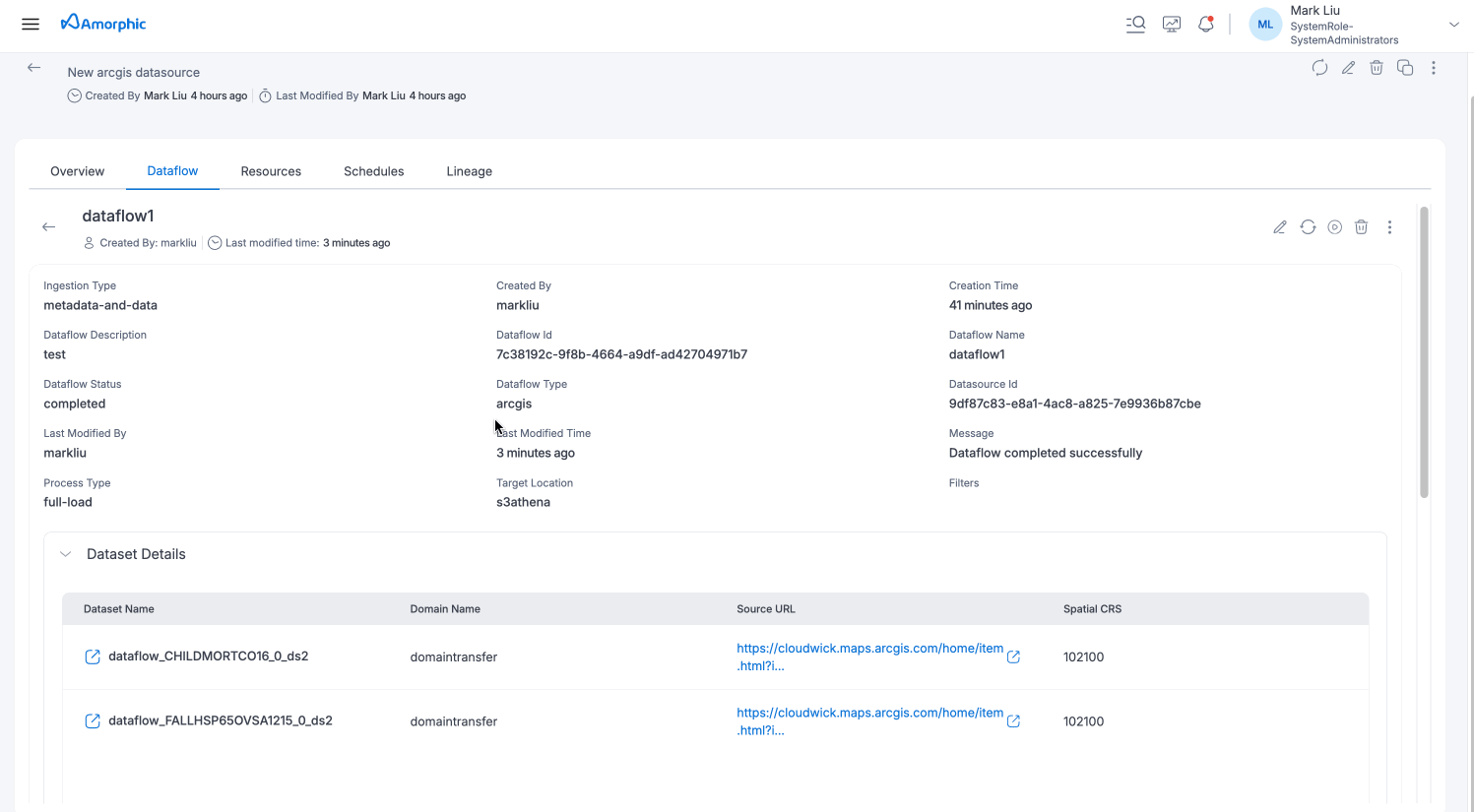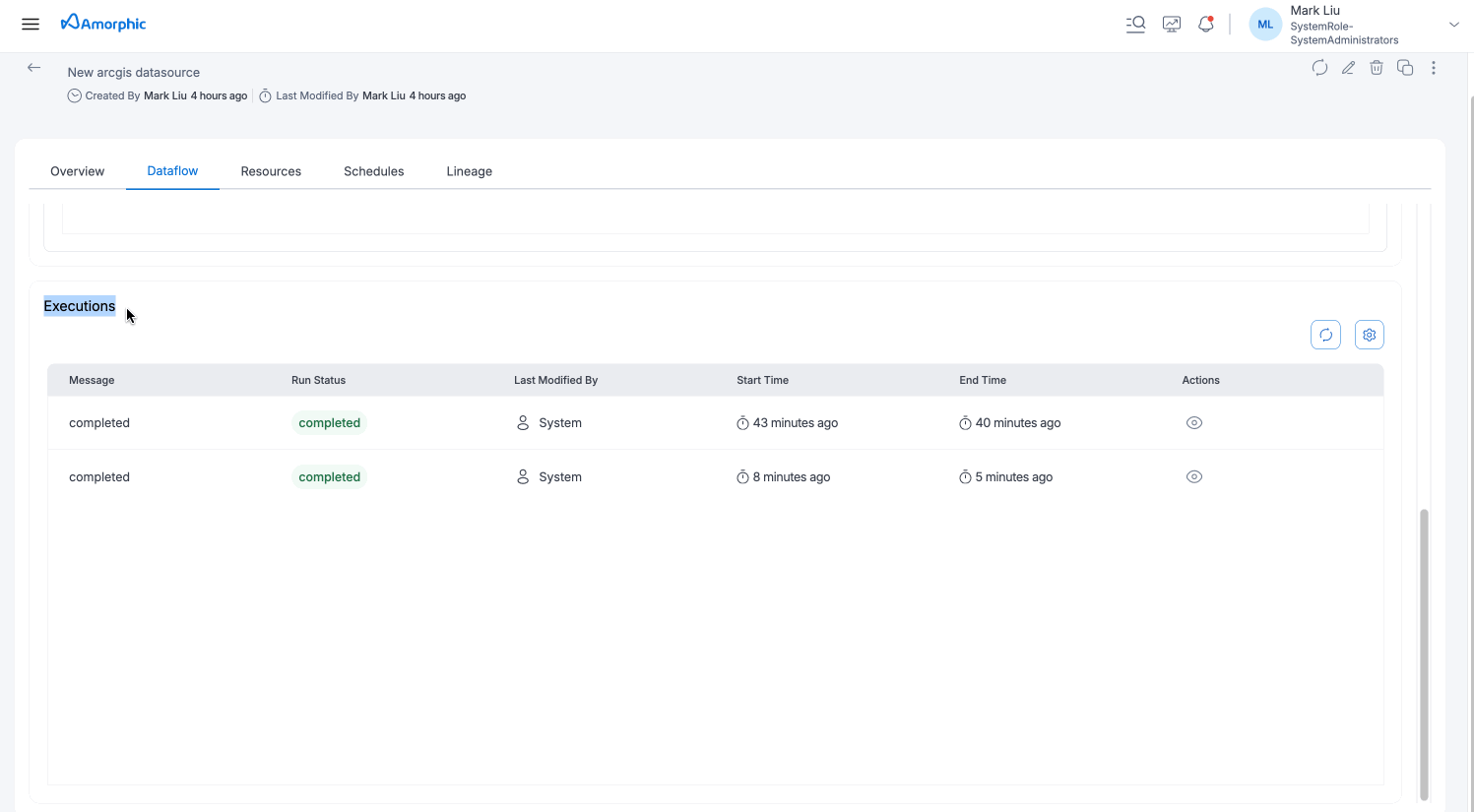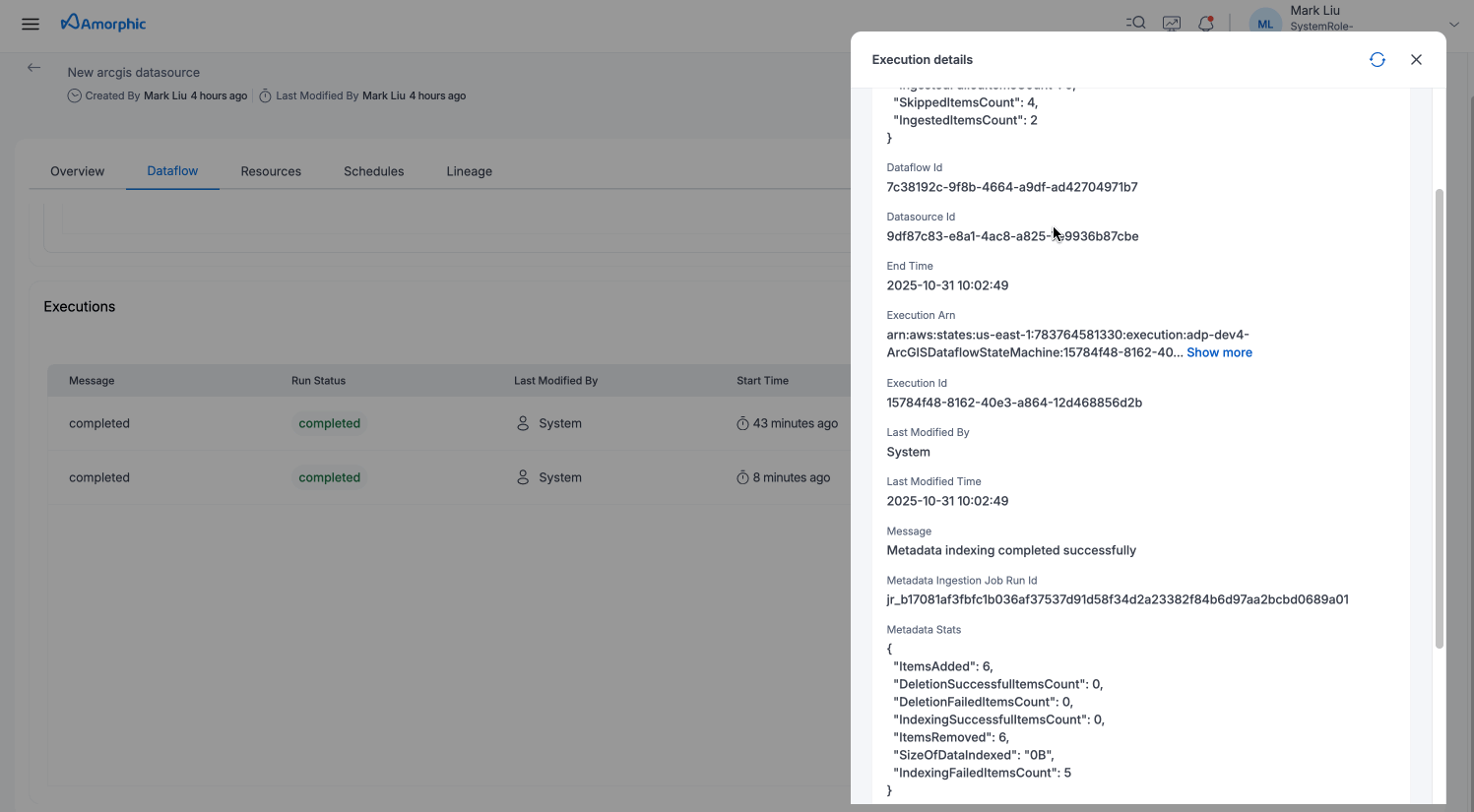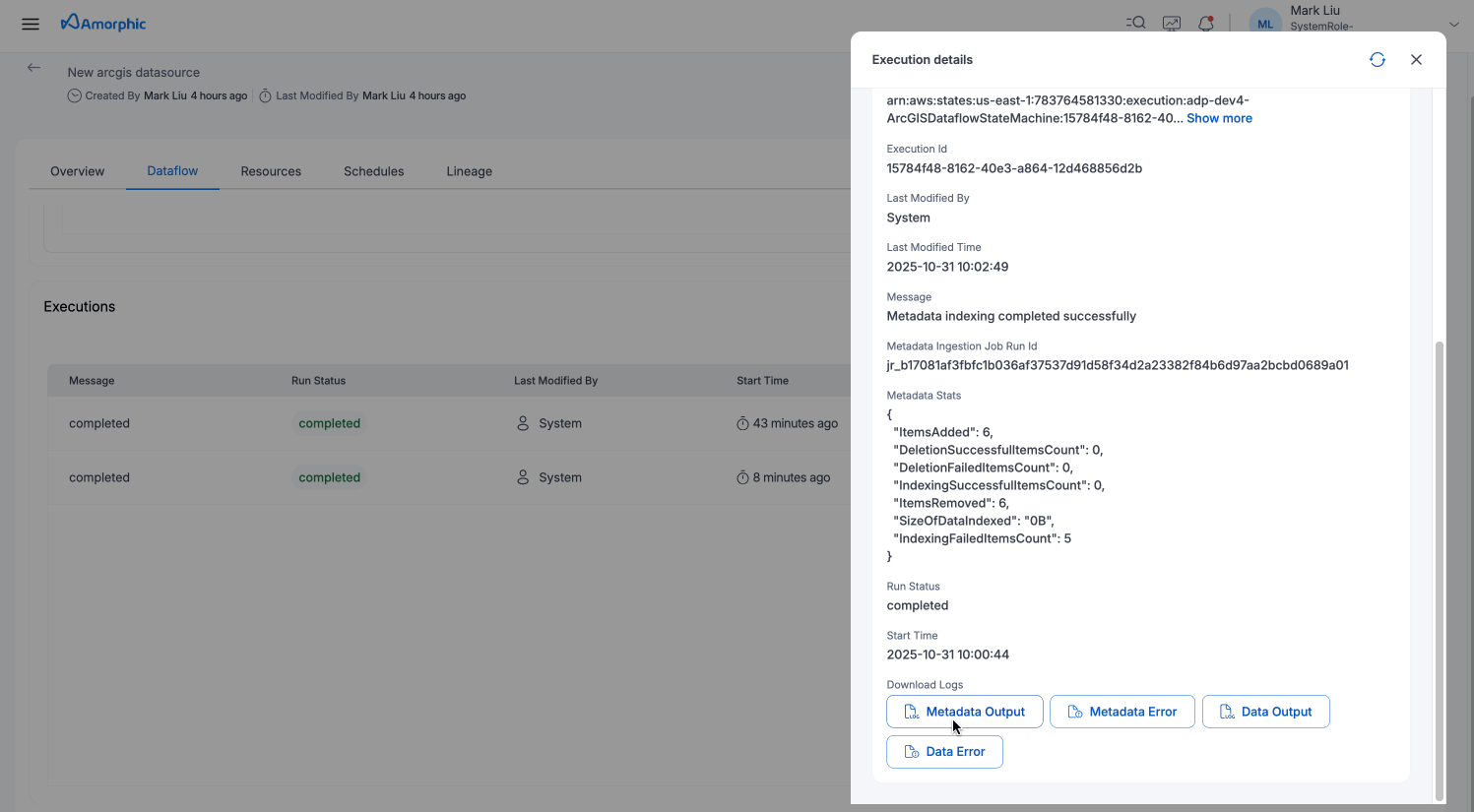
Executions:
This section shows the execution history and status for each dataflow run. User can monitor progress and view the latest message for each execution. User can click on the eye icon to view the detailed information and metrics for each execution and also download the logs for each execution.
How to schedule a dataflow to ingest ArcGIS items?
To schedule a dataflow to ingest ArcGIS items, you can go to the dataflow details page and click on the "Schedule" tab then click on the "Create Schedule" button.
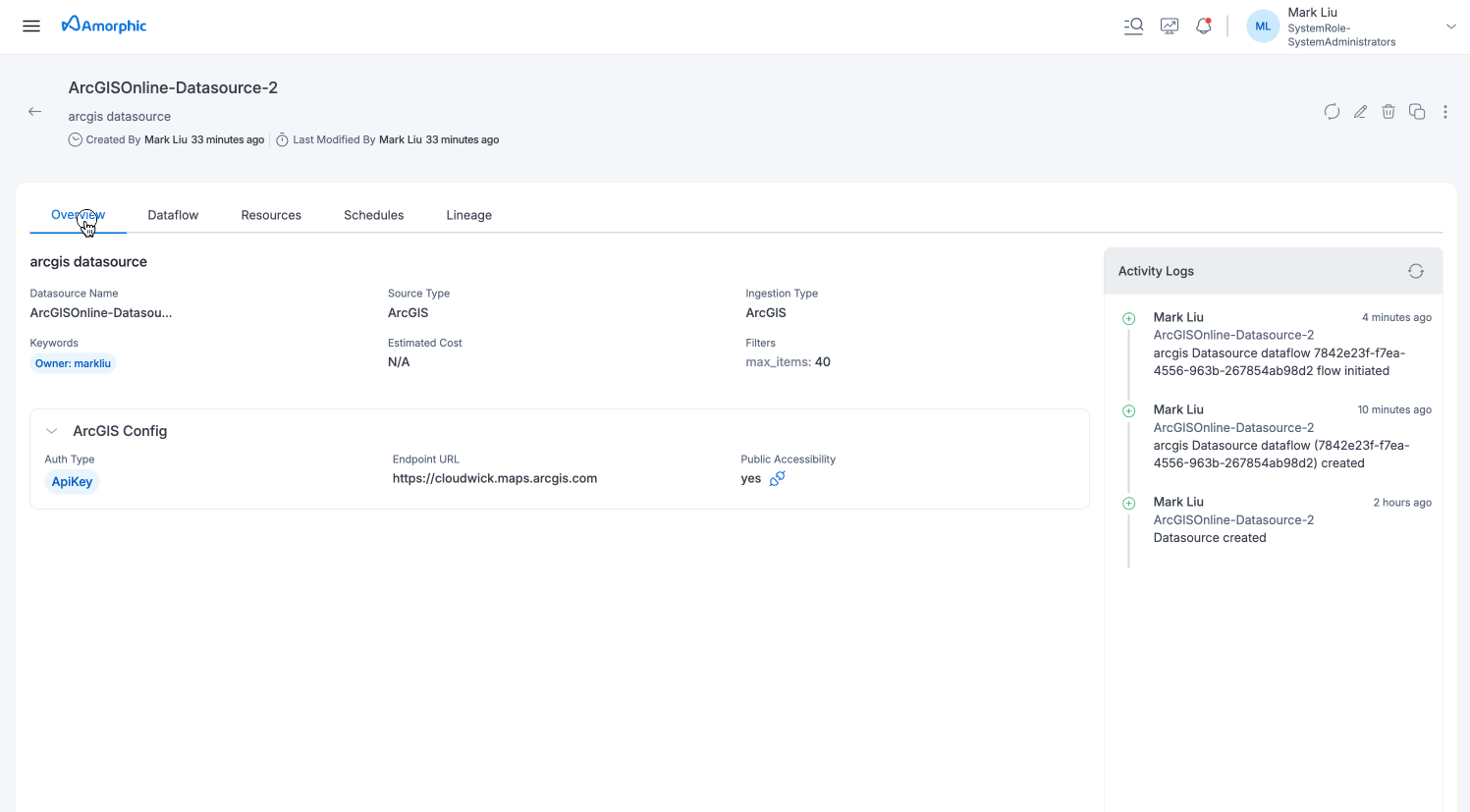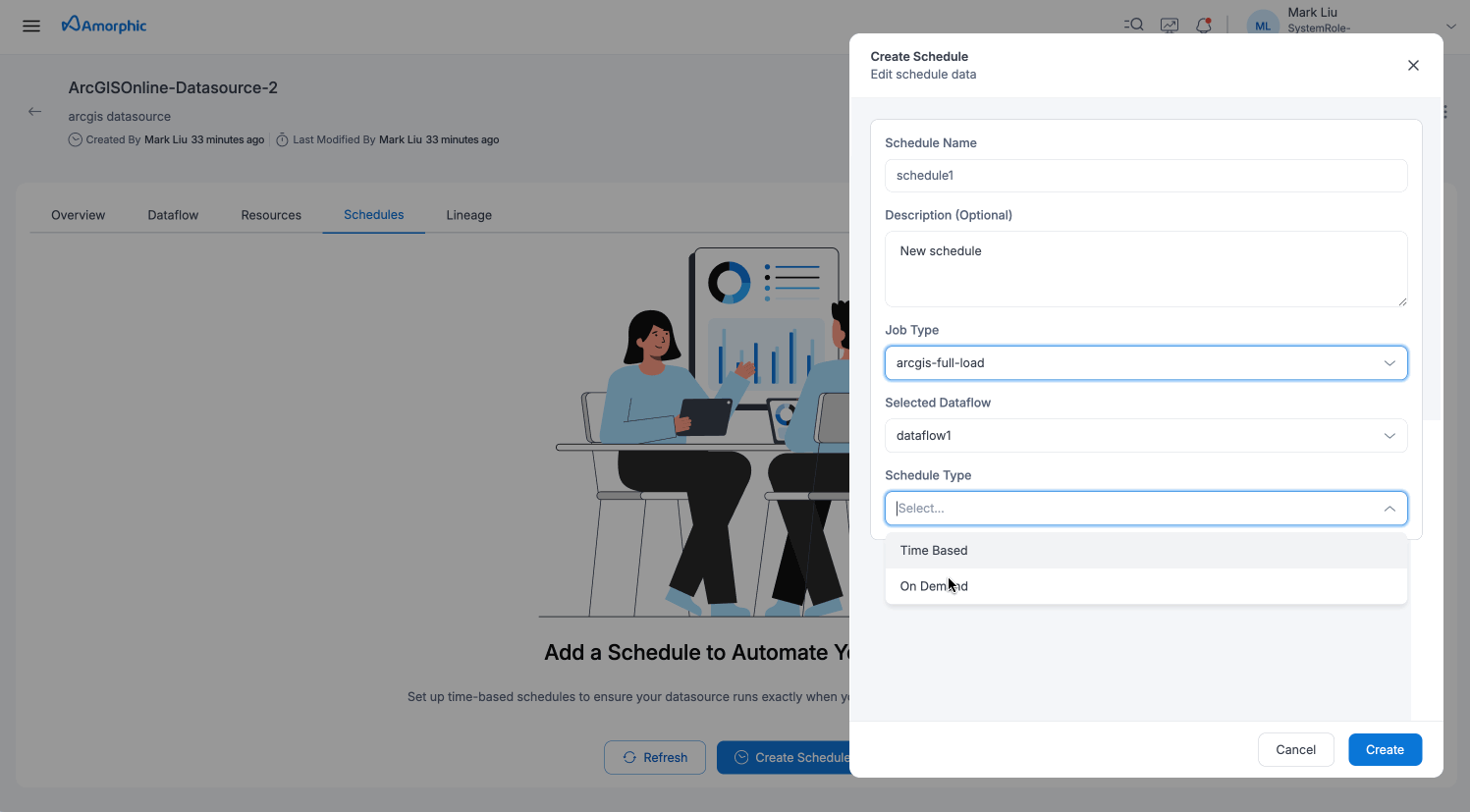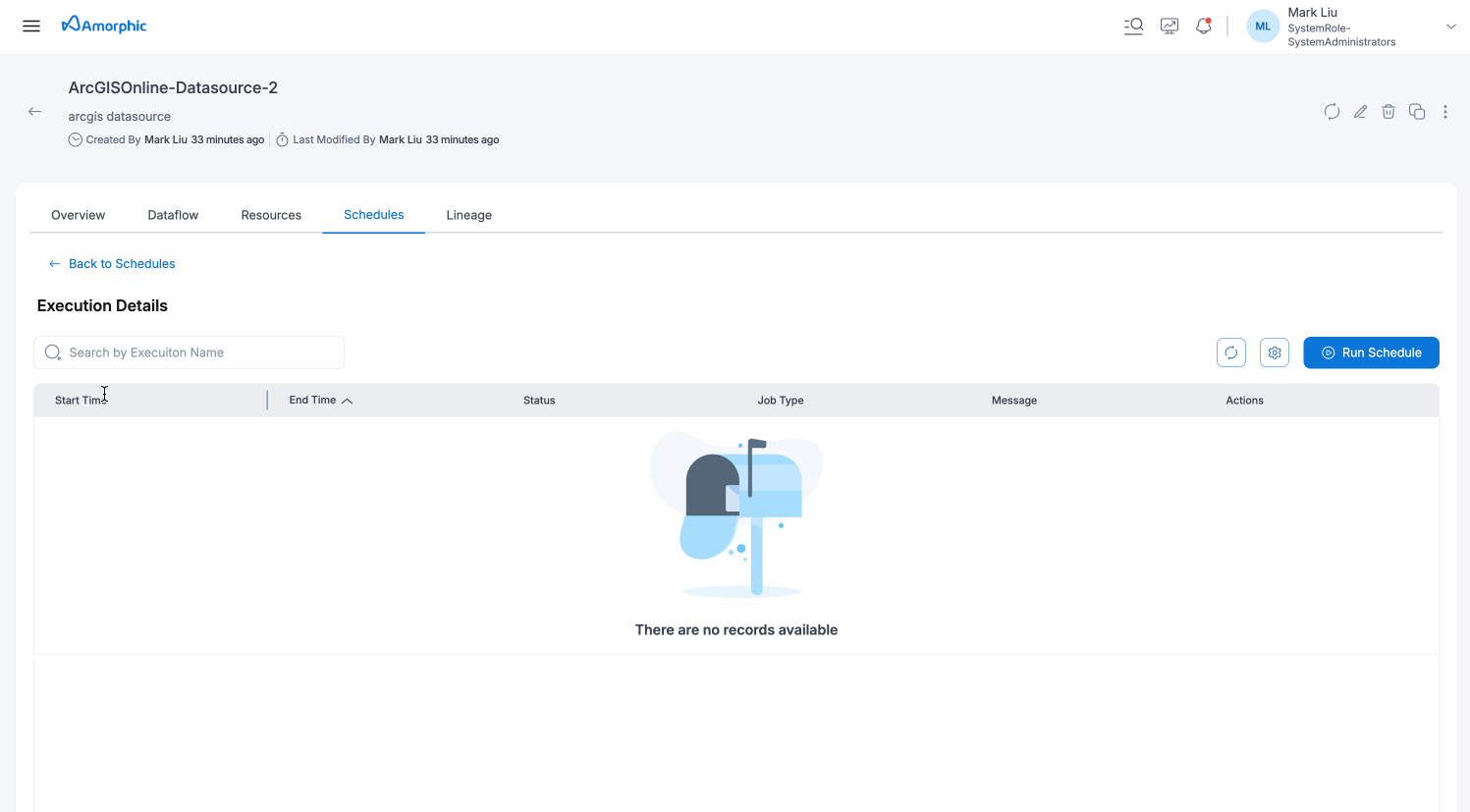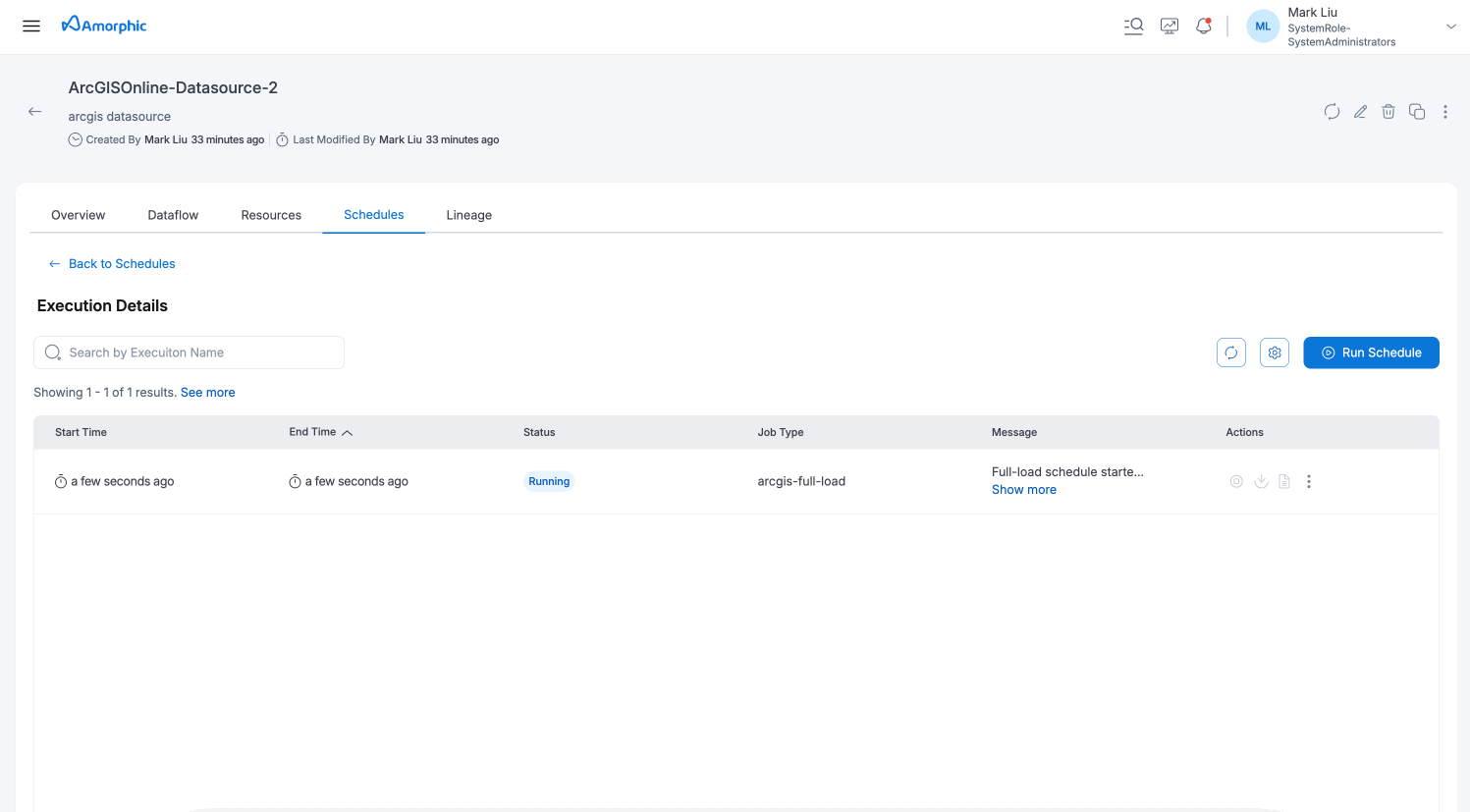
Fill in the details as shown in the table below and click on the "Schedule" button.
| Details | Description |
|---|---|
| Schedule Name | Give the schedule a unique name |
| Description | Add a description for the schedule |
| Job Type | Choose the job type based on the dataflow's Process Type: - arcgis-full-load for Full Load process type - arcgis-incremental for CDC or Full-Load-and-CDC process types |
| Select Dataflow | Choose the dataflow to schedule |
| Schedule Type | Choose the schedule type: Time Based or On-Demand |
| Schedule Expression | The schedule expression for the cron schedule required for time based schedules |
CDC and Full-Load-and-CDC process types require a schedule to be created before the dataflow can be started. The schedule must be created manually, and the dataflow will not start until a schedule exists.
For these process types:
- The schedule must use job type arcgis-incremental
- The minimum schedule rate depends on your ArcGIS Feature Service capabilities
- The first run is triggered when you start the dataflow or click Run Schedule; subsequent runs are triggered automatically by the schedule
Once the schedule is created, you can see the schedule details on the schedules tab. Click on the schedule name to view the schedule details and click on the "Run Schedule" button to run the schedule immediately.
Deletion of ArcGIS Dataflows
When an ArcGIS dataflow is deleted, only the metadata (catalog assets) are removed. The actual data and datasets remain in the system and are not automatically deleted.
If you need to remove the actual datasets created from an ArcGIS dataflow, you must delete them separately from the Datasets section.
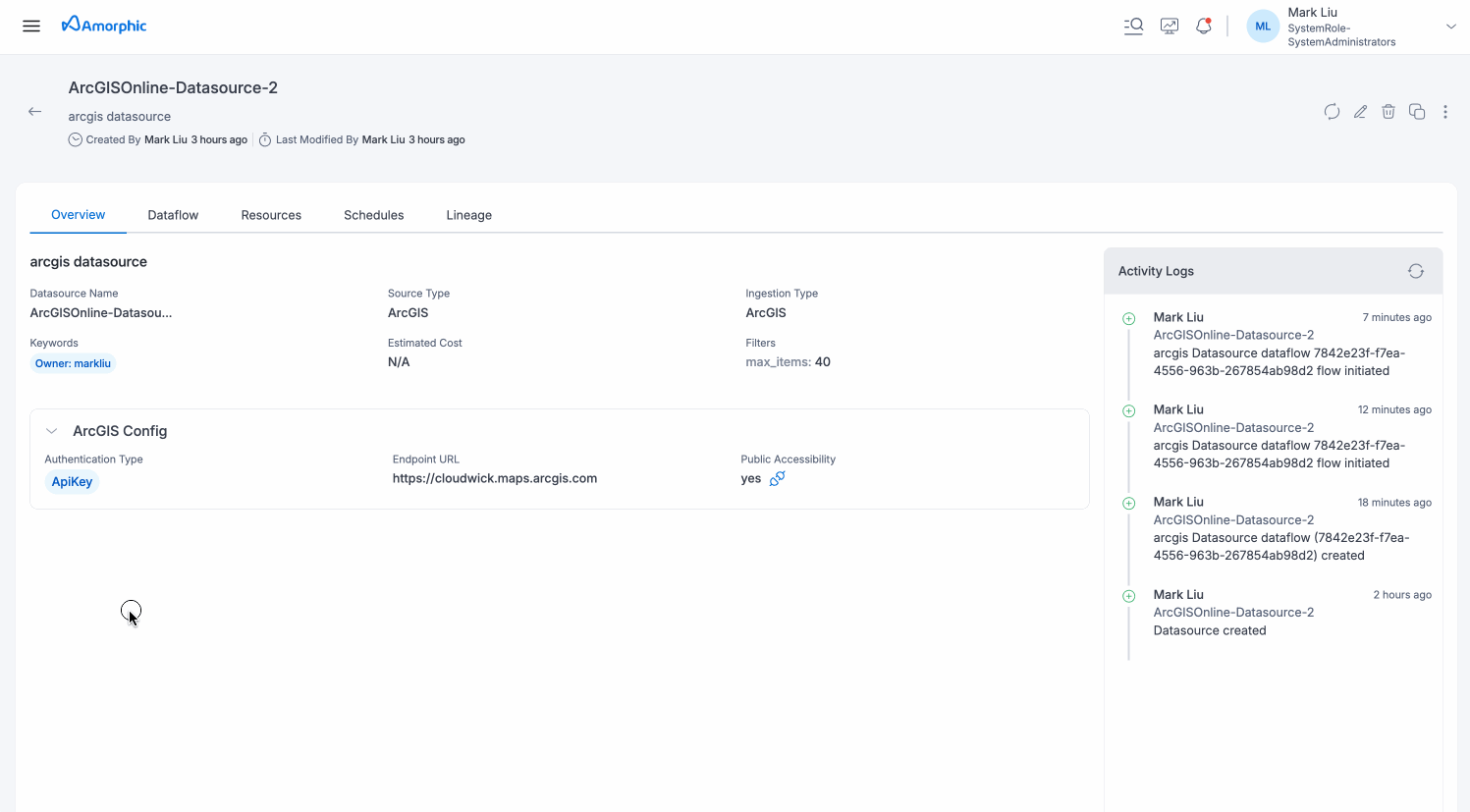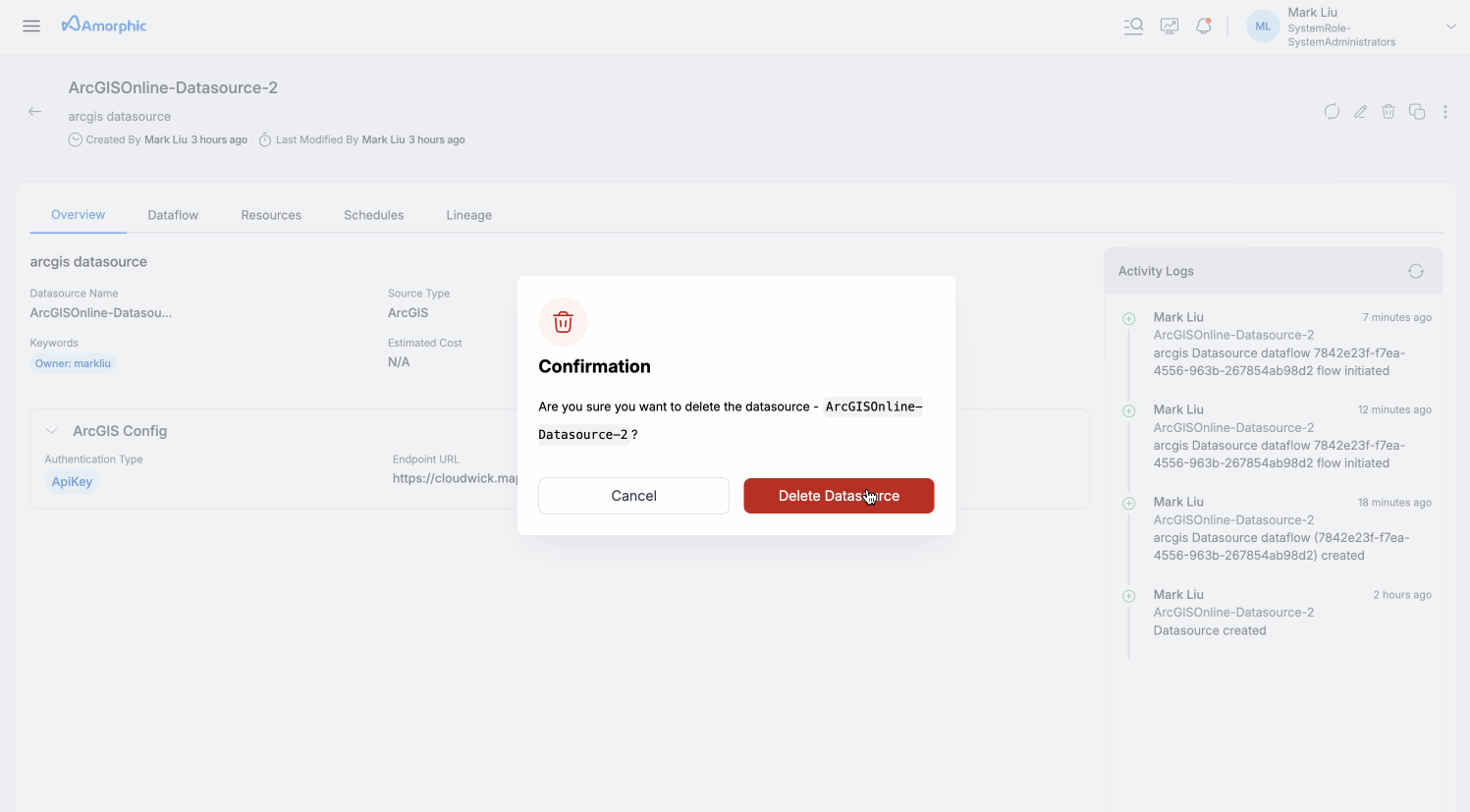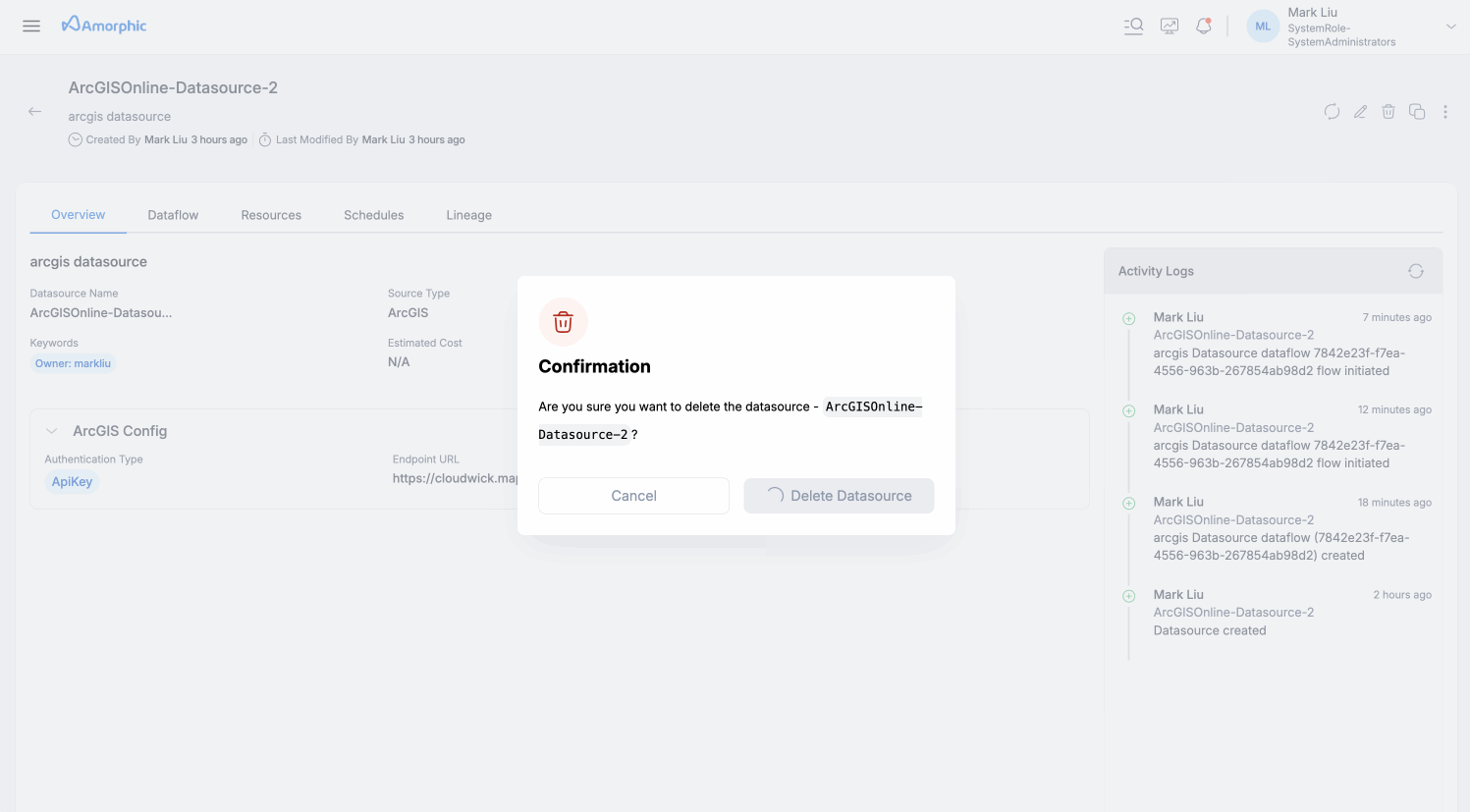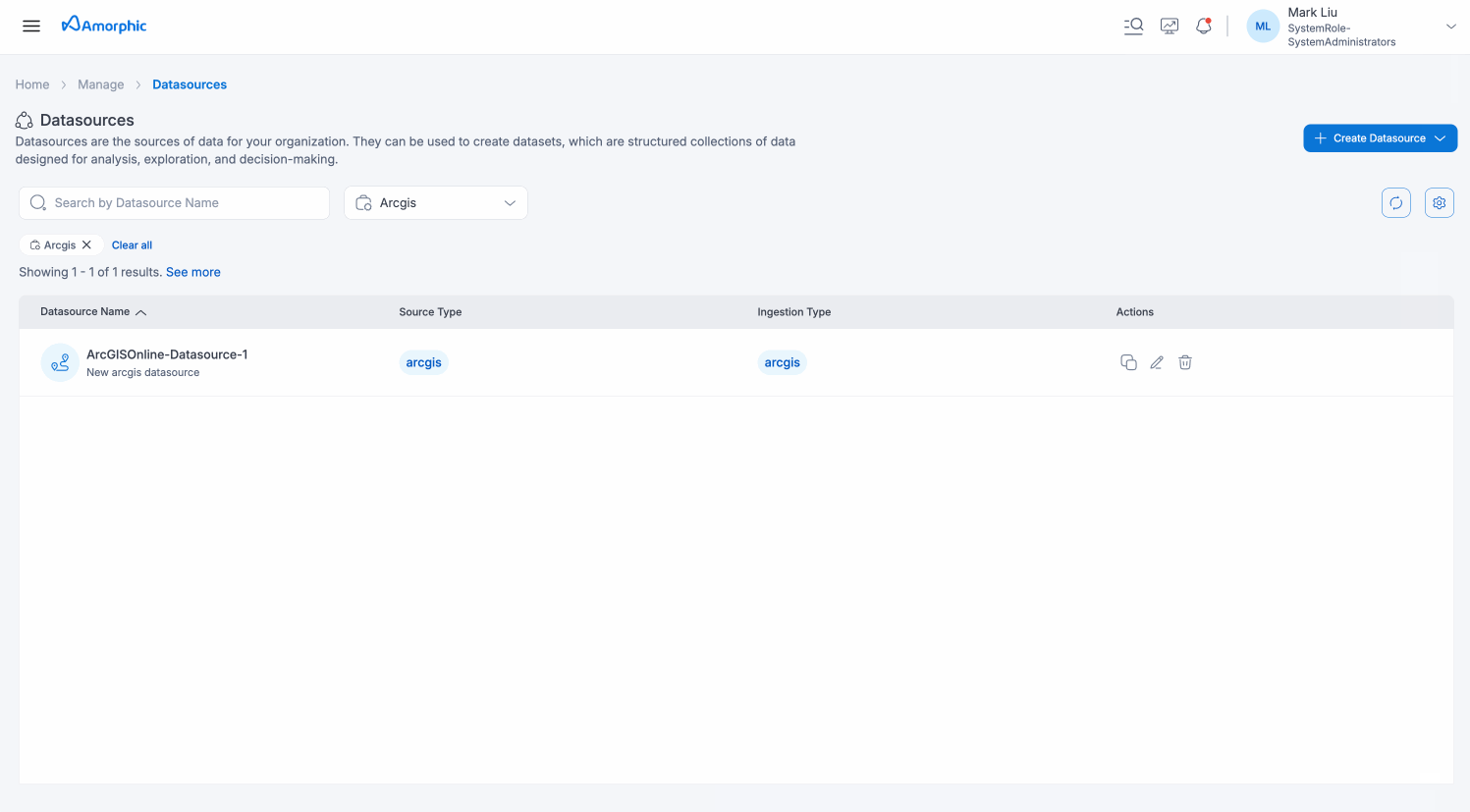
How to delete an ArcGIS datasource?
To delete an ArcGIS datasource, you can go to the datasource details page and click on the "Trash" button. Click on the "Delete Datasource" button to confirm the deletion of the datasource.