
Overview
Amorphic Data Pipelines enable you to orchestrate and visualize complex analytical processes by combining various components including ETL jobs, machine learning model inference tasks, notifications, and AWS AI services like Textract, Translate, Comprehend, and Medical Comprehend.
The Data Pipelines feature provides comprehensive management, execution, and monitoring capabilities for all pipeline components. It allows you to create dependency chains (Directed Acyclic Graphs) between different types of tasks, enabling sophisticated analytical workflows.
The Data Pipelines interface provides intuitive options to view existing pipelines, create new ones, and filter pipelines based on criteria such as name, creator, and creation time.

Creating Data Pipelines
To create a pipeline node, import a pre-configured Amorphic module. The following attributes are required for node creation:
| Attribute | Description |
|---|---|
| Module Type | A pre-configured building block that supports various task types including ETL Jobs, ML model inference, notifications, AWS AI services, S3 sync, and File Load Validation. |
| Resource | Available resources based on the selected module type. For example, selecting ETL Job module type displays all accessible ETL jobs. |
| Node Name | A unique identifier for easy reference and management. |
| Input Configurations | Parameters that can be utilized within the job execution. |
Pipeline Execution Properties
Pipeline execution properties are key-value pairs that can be defined during pipeline creation or modification. These properties are accessible during execution and can be used to dynamically adjust pipeline behavior.
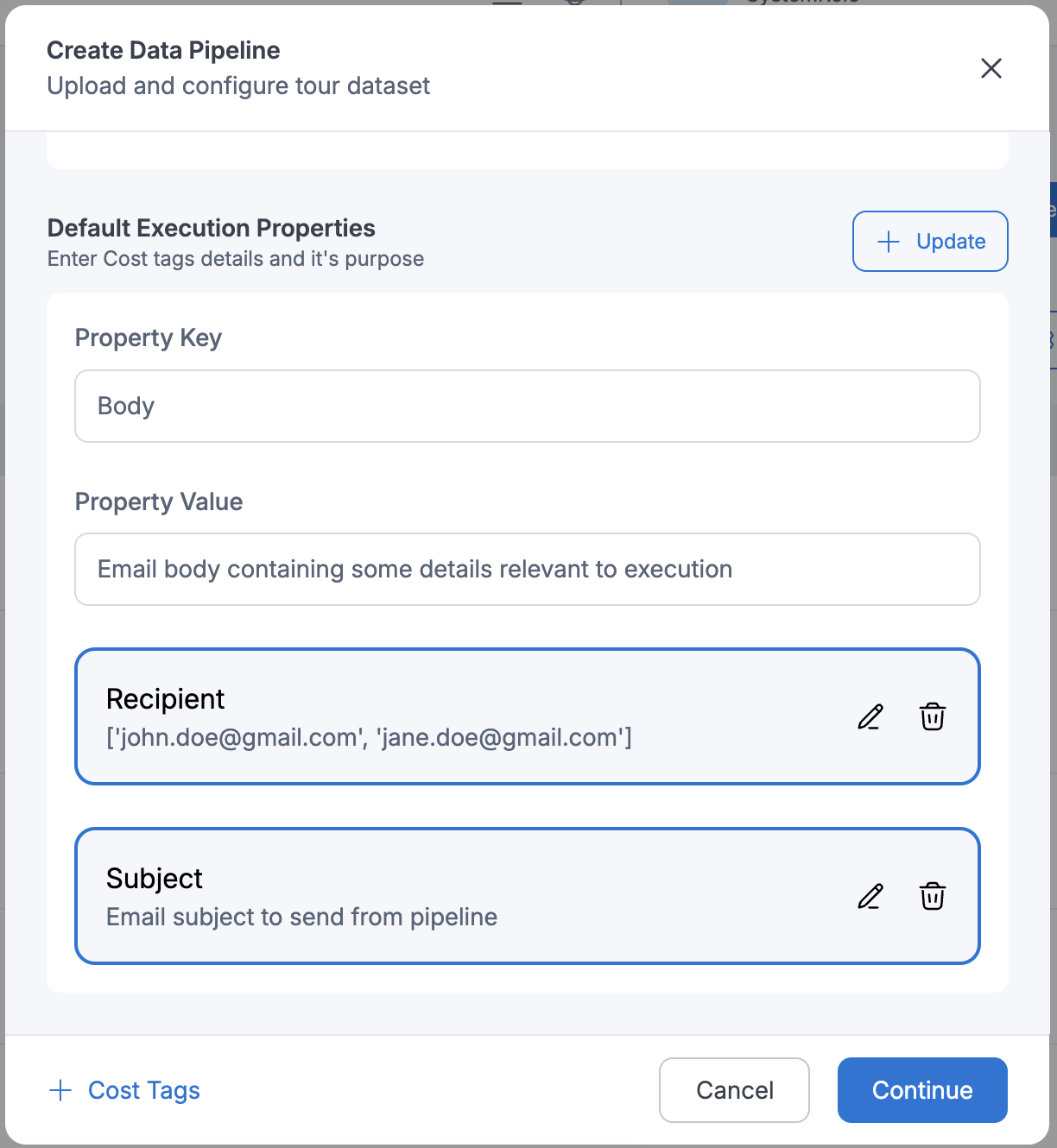
Retrieving pipeline execution properties:
import sys
import boto3
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from awsglue.context import GlueContext
from pyspark.context import SparkContext
glue_client = boto3.client("glue")
args = getResolvedOptions(sys.argv, ['JOB_NAME','WORKFLOW_NAME', 'WORKFLOW_RUN_ID'])
workflow_name = args['WORKFLOW_NAME']
workflow_run_id = args['WORKFLOW_RUN_ID']
workflow_params = glue_client.get_workflow_run_properties(Name=workflow_name,
RunId=workflow_run_id)["RunProperties"]
email_to = workflow_params['email_to']
email_body = workflow_params['email_body']
email_subject = workflow_params['email_subject']
file_name_ml_model_inference = workflow_params['file_name_ml_model_inference']
Modifying pipeline execution properties:
import sys
import boto3
from awsglue.transforms import *
from awsglue.utils import getResolvedOptions
from awsglue.context import GlueContext
from pyspark.context import SparkContext
glue_client = boto3.client("glue")
args = getResolvedOptions(sys.argv, ['JOB_NAME','WORKFLOW_NAME', 'WORKFLOW_RUN_ID'])
workflow_name = args['WORKFLOW_NAME']
workflow_run_id = args['WORKFLOW_RUN_ID']
workflow_params = glue_client.get_workflow_run_properties(Name=workflow_name,
RunId=workflow_run_id)["RunProperties"]
workflow_params['email_subject'] = 'Coupon: Grab and go!'
glue_client.put_workflow_run_properties(Name=workflow_name, RunId=workflow_run_id, RunProperties=workflow_params)
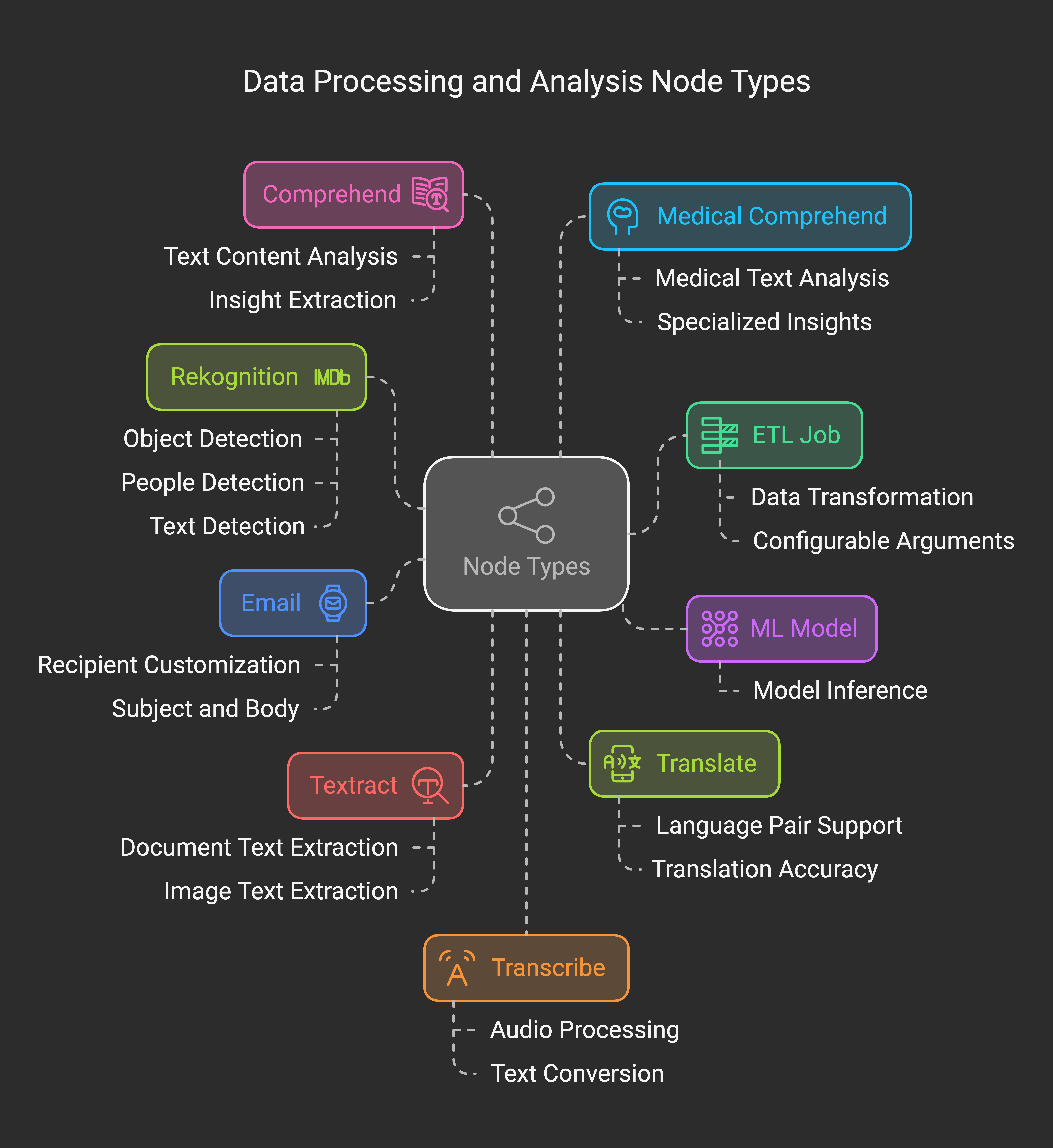
Pipeline Nodes
In Amorphic, nodes are the building blocks of data pipelines, constructed using pre-defined modules. Each node represents a specific task type and can be configured, monitored, and managed independently. Nodes can be connected to form complex pipelines with defined dependencies.
| Node Type | Description |
|---|---|
| ETL Job | Executes data transformation jobs with configurable arguments |
| ML Model | Runs machine learning model inference tasks |
| Sends notifications with customizable recipient, subject, and body | |
| Textract | Extracts text from documents and images |
| Rekognition | Analyzes images and videos for object, people, and text detection |
| Translate | Performs language translation |
| Comprehend | Extracts insights from text content |
| Medical Comprehend | Processes medical text for specialized insights |
| Transcribe | Converts audio to text |
| Medical Transcribe | Specialized audio-to-text conversion for medical content |
| Pipeline | Enables nested pipeline execution |
| Sync to S3 | Manages data synchronization with S3 storage |
| File Load Validation | Performs data validation before ingestion |
Pipeline Execution
Data pipelines can be executed immediately or scheduled for future execution. The scheduling feature allows for automated pipeline runs at specified intervals, with the flexibility to enable or disable schedules as needed.
To stop an active pipeline execution, use the Stop Execution option available in the pipeline's context menu (three dots).

Conditional Node Execution
Amorphic supports conditional node execution based on the success or failure of predecessor nodes. This powerful feature enables complex use cases such as error handling and branching logic within pipelines.
Example scenario:

In this example:
- The "SendPromotionalEmails" ETL job executes only after successful completion of "ReadCustomerDetails"
- If "ReadCustomerDetails" fails, the "FailureAlertGenerator" node sends notification emails

Complex ETL example:

Execution rules:
- node_one: Executes at pipeline start
- node_two: Executes when node_one succeeds
- node_three: Executes when node_two succeeds
- node_four: Executes when node_six succeeds AND node_two succeeds AND node_three fails
- node_five: Executes at pipeline start
- node_six: Executes when node_five fails AND node_one succeeds
Existing pipelines maintain their functionality without requiring modifications. Users can edit pipeline configurations and update node triggers as needed.
Example Use Case
Consider a document processing pipeline with the following sequential tasks:
- Text extraction from images (Textract node)
- Text analysis and data extraction (Comprehend node)
- Completion notification (Email node)
The pipeline ensures sequential execution, where each node depends on the successful completion of its predecessor, maintaining data processing integrity.
Execution Logs
Amorphic provides comprehensive logging for ETL Job and Datasource nodes. Access logs through the execution details tab using the following options:
Preview Logs
User can preview logs for the specified time frames to analyze the execution status and details of the node execution. By default, the logs are displayed from the execution start time to the current time(if the execution is still running) or the end time of the execution.

Generate Logs
In case, there are a large number of logs, user can trigger logs generation for the specified time frames to analyze the execution status and details of the node execution. The logs will be generated in the background and the user can download the logs from the execution details tab once available.

Download Logs
User can download the logs from the execution details tab once available. If a user triggers logs generation for a different time frame, the existing logs will be replaced with the new logs.

Pipeline execution logs are retained for 90 days. Attempts to access older execution logs will result in an error.