
ETL Jobs
Jobs are orchestration of tasks that are executed in a sequence to perform a specific operation. They allow user the creation freedom to analyze, transform, and load data from various sources to a target destination. ETL Jobs enable users to efficiently handle and process large volumes of data, ensuring that it is clean, consistent, and ready for analysis.
ETL Jobs in Amorphic
ETL jobs in Amorphic are essential processes in data management and analytics that involve extracting data from various sources, transforming it into a suitable format, and loading it into a target system, such as a data warehouse or data lake. ETL jobs enable users to efficiently handle and process large volumes of data, ensuring that it is clean, consistent, and ready for analysis. These jobs can be scheduled to run at specific intervals or triggered manually. Users can create, edit, and manage ETL jobs from the Amorphic portal.
For instance, user might want to create a flow of operations which fetch data from Amorphic datasets and perform certain ETL operations on it, beforing writing it into a target dataset. These jobs provide users with the flexibility and ease needed to handle their data efficiently and gain valuable insights. Below is a detailed look at each component of ETL jobs:
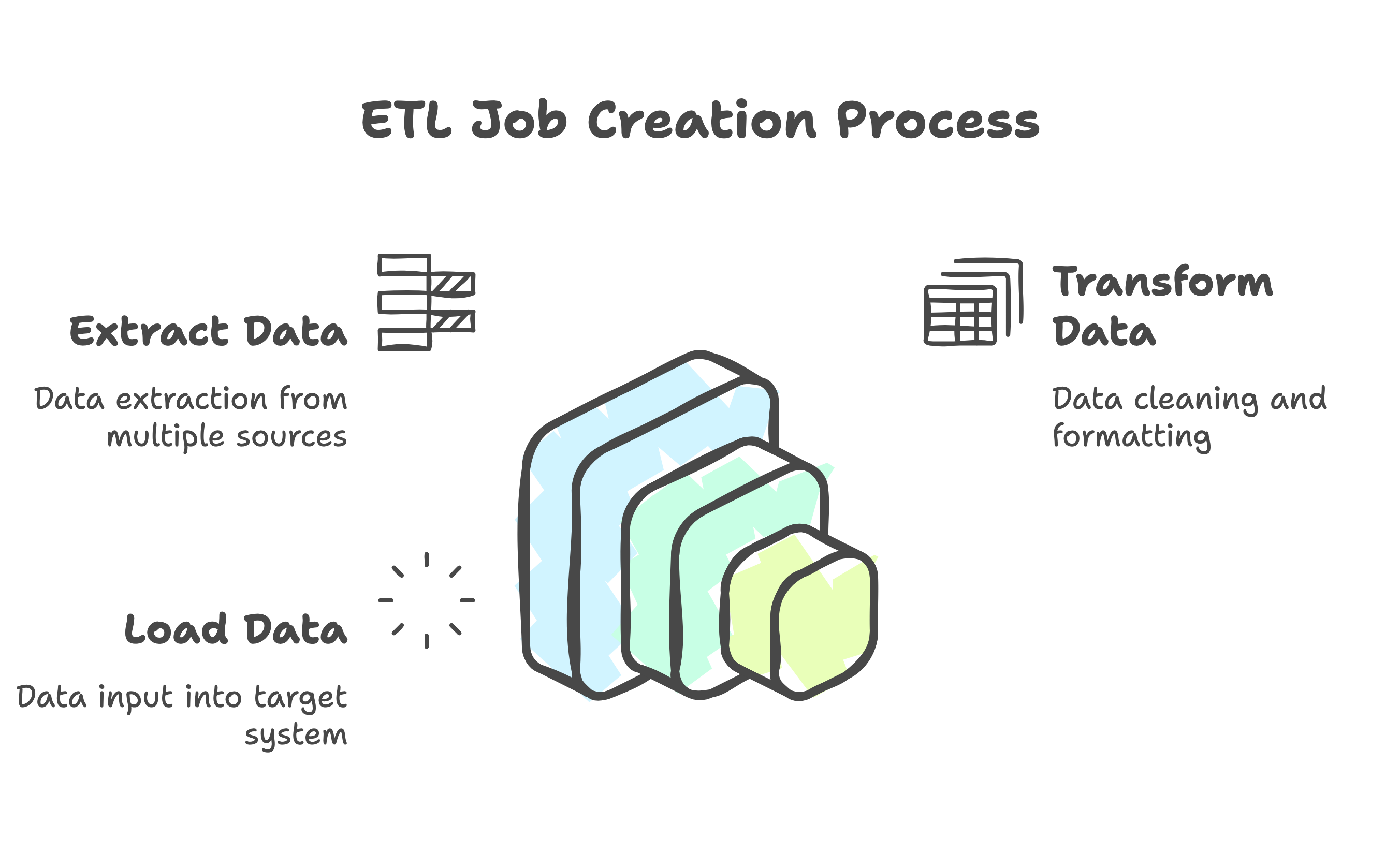
Job Operations
From the aforementioned job details page, user gets a liberty to perform various operations on the job. Amorphic ETL Jobs provides the following operations:
- Create Job: Create a ETL job
- View Job Details: View details of a existing job
- Update Job: Update an existing job
- Run Job: Execute a ETL job
- Job Executions: View all the executions of a job
- Job Logs: View and download the logs of a job
Create Job
- Click on
+ Create Job - Provide the required details in the fields present(Details shown in the table below).

For creation of a ETL job, user is required to provide some of the following fields:
| Attribute | Description |
|---|---|
| Name | The name by which the user wants to create the job. The name must be unique across the Amorphic platform. |
| Description | A brief description about the job to be created. |
| Job Type | Choose the job registration type:
|
| Bookmark | Specify whether to enable/disable/pause a job bookmark. If job bookmark is enabled, then add a parameter "transformation_ctx" to user's Glue dynamic frame so glue can store the state information. |
| Max Concurrent Runs | The maximum number of concurrent runs allowed for the job. |
| Max Retries | The specified number will be the maximum number of times the job will be retried if it fails. |
| Max Capacity OR Worker Type/ Number of Workers | For PythonShell Jobs: Max capacity is the number of AWS Glue data processing units that can be allocated when the job runs OR For Spark Jobs, following are required:
|
| Timeout | Maximum time that a job can run can consume resources before it is terminated. [Default timeout = 48 hrs] |
| Notify Delay after | After a job run starts, the number of minutes to wait before sending a job run delay notification. |
| Datasets Write Access | User can select datasets with the write access required for the job. |
| Datasets Read Access | User can select datasets with the read access required for the job, including datasets of type View |
| Datasets Read-Only File-Level Access | Users can select datasets with read-only file-level access, allowing them to retrieve specific files stored within the dataset that are required for the job. |
| Domains Write Access | User can select domains with the write access required for the job. User will have write access to all the datasets (existing and newly created if any) under the selected domains. |
| Domains Read Access | User can select domains with the read access required for the job. User will have read access to all the datasets (existing and newly created if any) under the selected domains. |
| Parameters Access | User accessible parameters from the Parameters Store will be displayed. User can use these parameters in the script. |
| Shared Libraries | User accessible shared Libraries will be displayed. User can use these libraries in the script for dependency management |
| Job Parameter | User can specify arguments that job execution script consumes, as well as arguments that AWS Glue consumes. However, adding/modifying following arguments are restricted to user for an ETL job: ["--extra-py-files", "--extra-jars", "--conf", "--TempDir", "--class", "--job-language", "--workflow_json_path", "--job-bookmark-option"].
|
| Network Configuration | There are five types of network configurations i.e. Public, App-Public-1, App-Private-1, App-Public-2 and App-Private-2.
|
| Keywords | Keywords for the job. Keywords are indexed and searchable within the application. User can use these to flag related jobs with the same/meaningful keywords so that you can easily find them later |
| Glue Version | Based on the selected Job Type, user may select respective Glue Version to use while provisioning/updating a job. For Spark jobs, Glue Version(s) 3.0 & 4.0 are supported. Glue version is not applicable for Python Shell jobs. |
| Python Version | Based on the selected Job Type and Glue Version, user may select respective Python Version to use while provisioning/updating a job. While creating a Spark job, Python Version can only be 3, for all Glue Versions (3.0, 4.0). For Python Shell jobs, Python Version can be 3 or 3.9. |
| Data Lineage | Based on selected Job Type and Glue Version, user may select if lineage of data on executing a job is required to be seen or not. Data lineage is currently supported for Spark jobs with Glue version 3. |
| Tags | Select the tags and access type in order to read the data from tag based access controlled datasets. |
- For system parameters, only read access will be granted when included in the Parameter Access.
- For all other parameters, both read and update permissions will be allowed when added to the Parameter Access.
- Owner access to external LF-targeted datasets cannot be granted.
- Read-only access to Lake Formation datasets can be provided. We can grant Lake Formation read-only access for jobs, but users with data filters applied to the same datasets will not be able to execute the job.
- Read-only file-level access can be provided only for datasets with S3 as the target location.
- All Spark jobs created from version 3.0 onward will have continuous logging enabled to comply with NIST requirements.
Use Case: Creating a simple job
For instance, a user wishes to create a test job that finds the highest-paying job and its salary. To achieve this, follow the following steps:
- Create a new tester job using the job type Spark
- Set the network configuration to public
- Enable bookmarking for the job, if desired
- Specify the maximum capacity or worker type for the job, or leave it blank to use the default values
- Attach any necessary libraries with custom packages
- Run the job
View Job Details
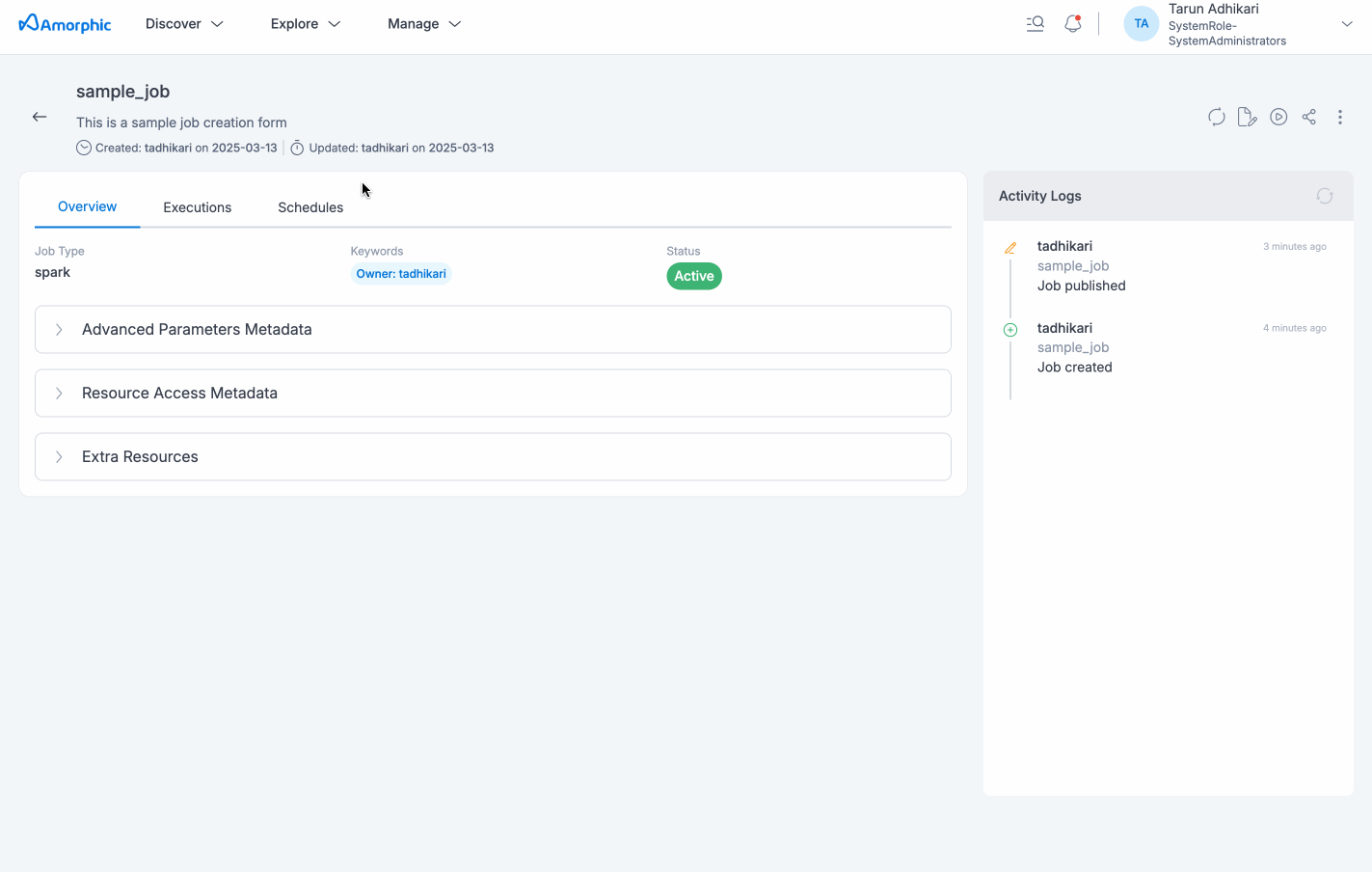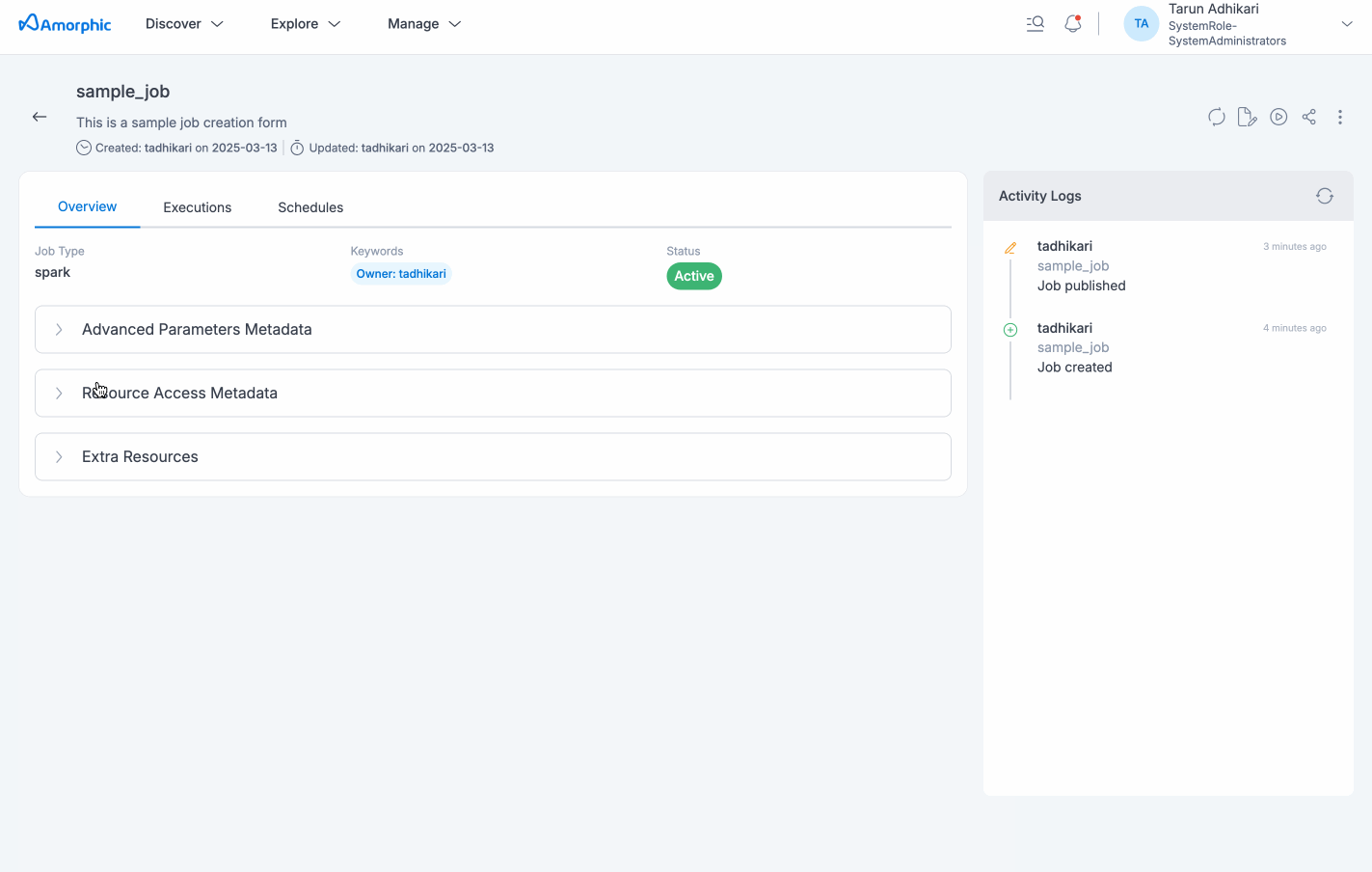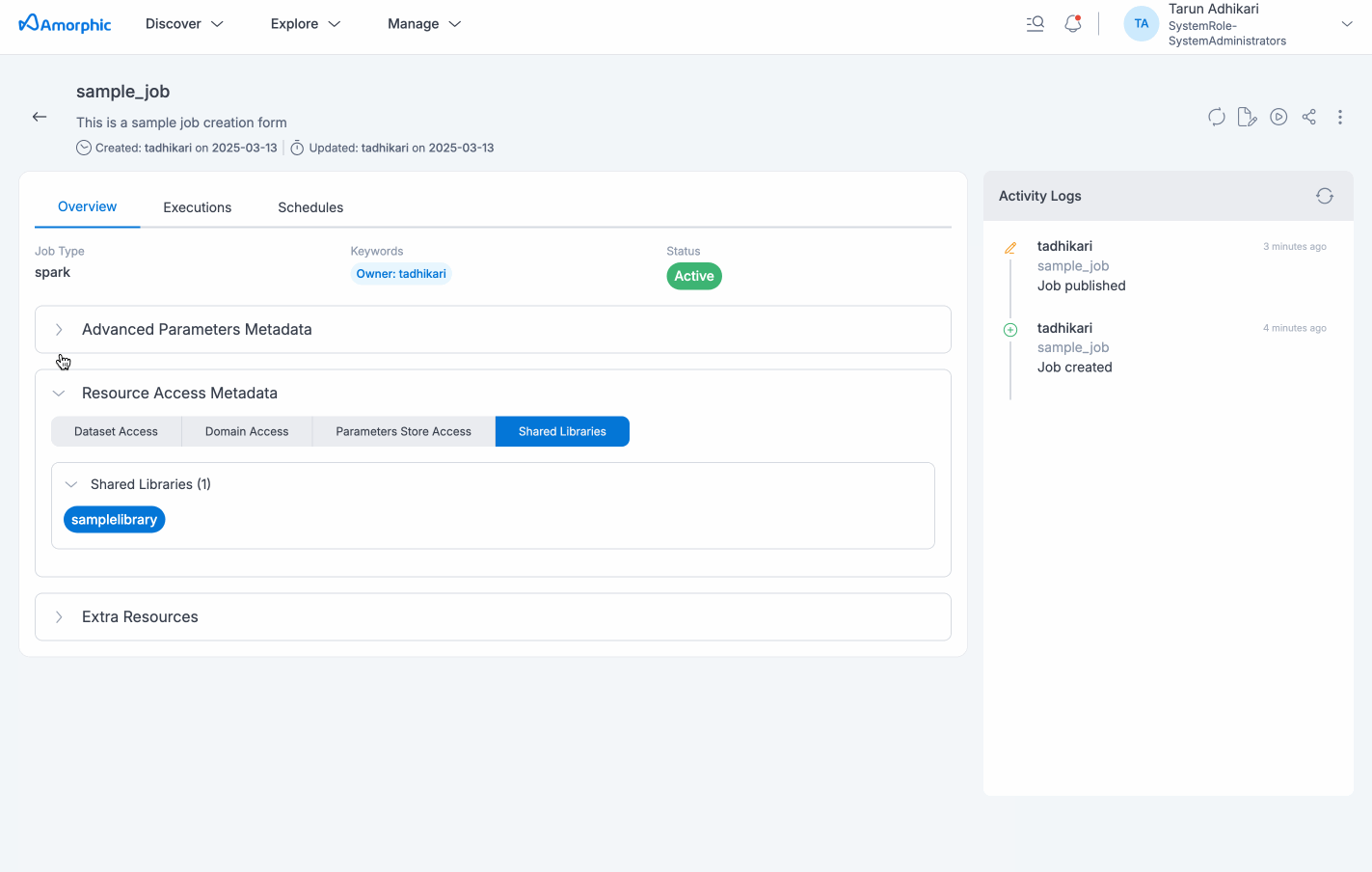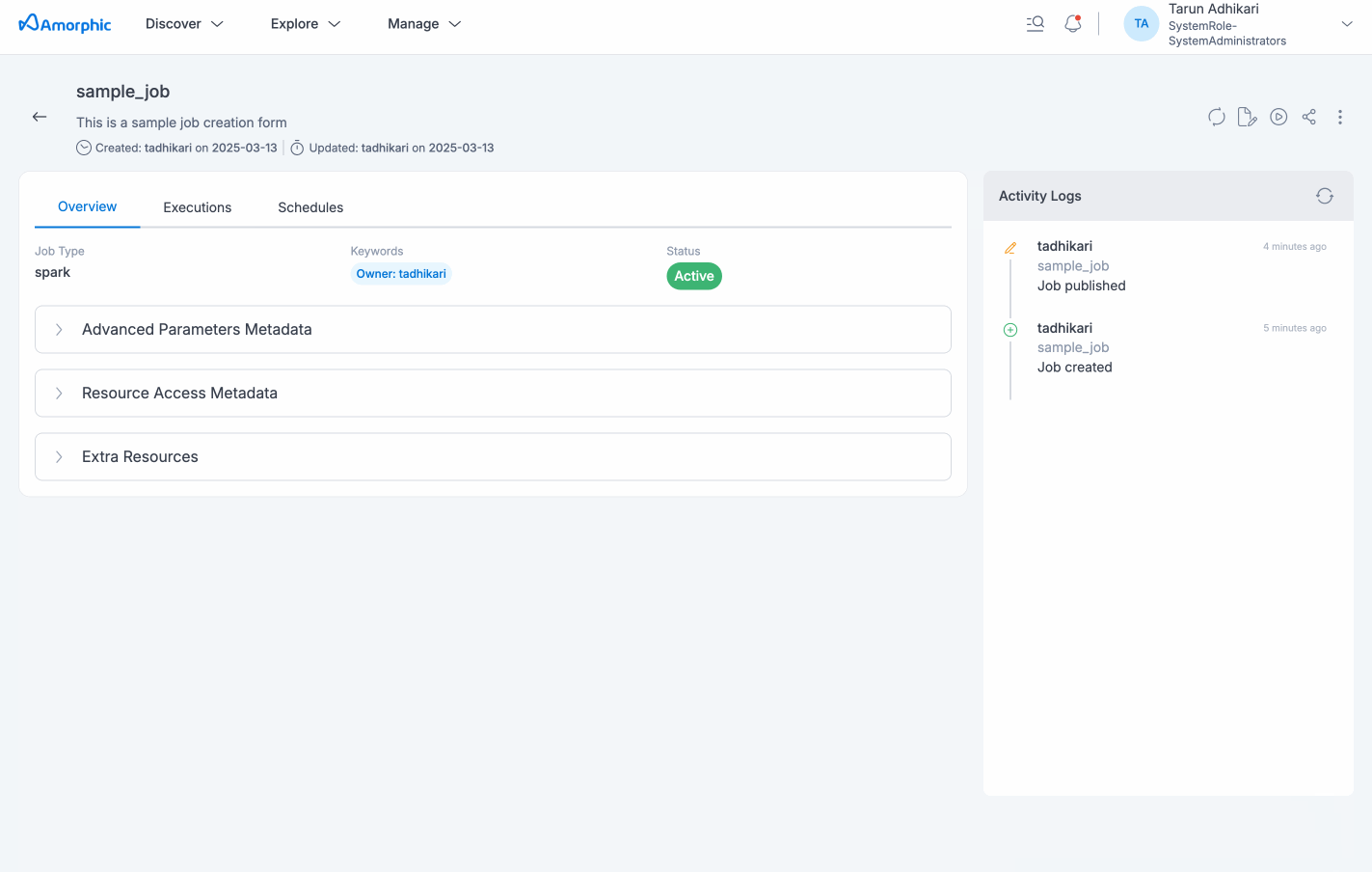
Job details page will display all the details specified and also with the default values for the unspecified fields (if applicable) for the selected job. User would be able to view resources of Amorphic being consumed by the job, like datasets, parameters, shared libraries, etc. All associated metadata like job name, type, job executions metadata, any associated Schedules, different kind of resource access, etc. will be displayed in the details page.
Update Job
Job details can be edited using the Edit button and changes will be reflected in the details page immediately.
Based on the access level of the job, user can perform this update action:
Owner: Based on the access to the attached resources( like datasets, parameters, etc), user can update the job i.e. if access to all underlying resources is present, then the job can be updated.
Read-only: Users with read-only access are not allowed to update the job.
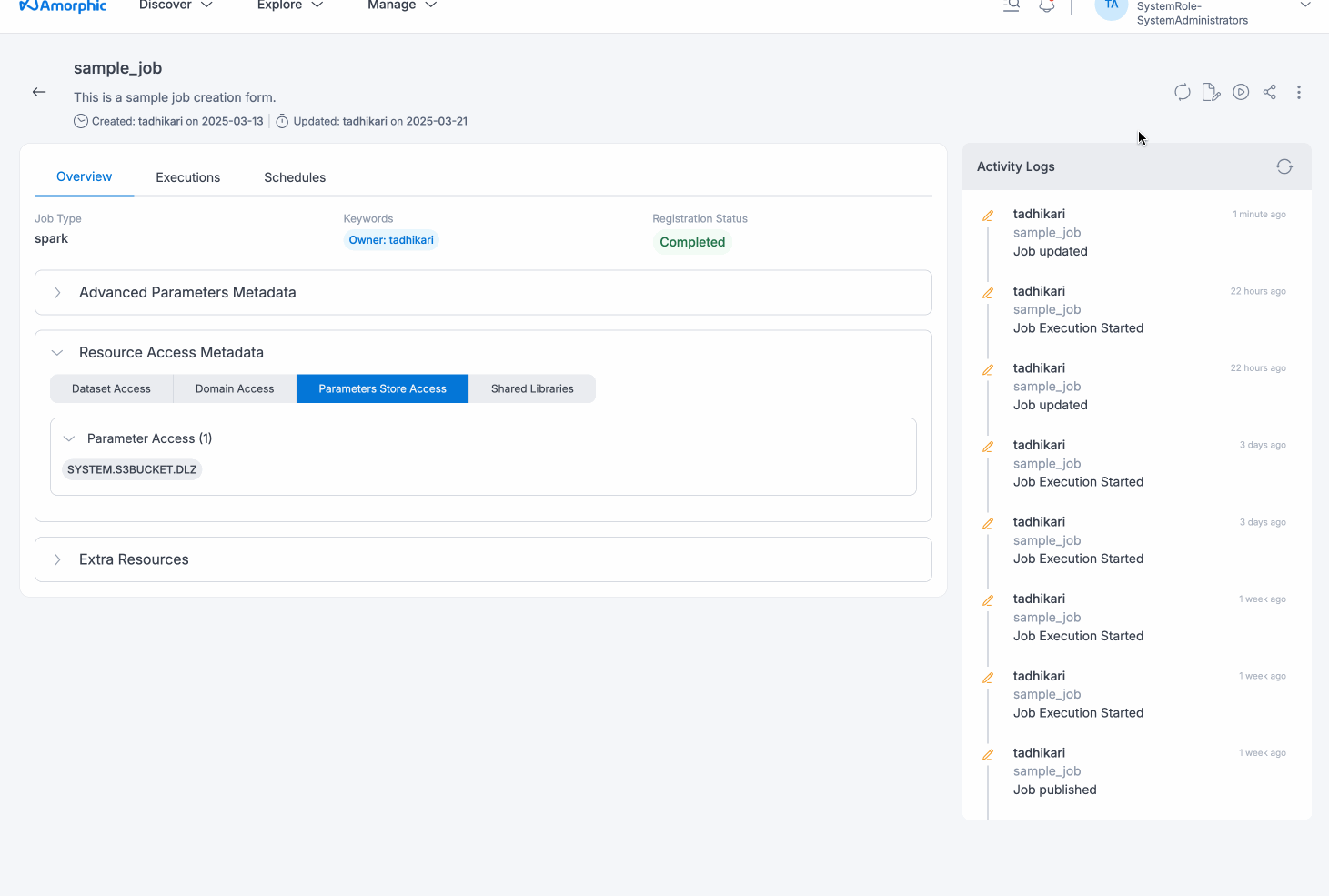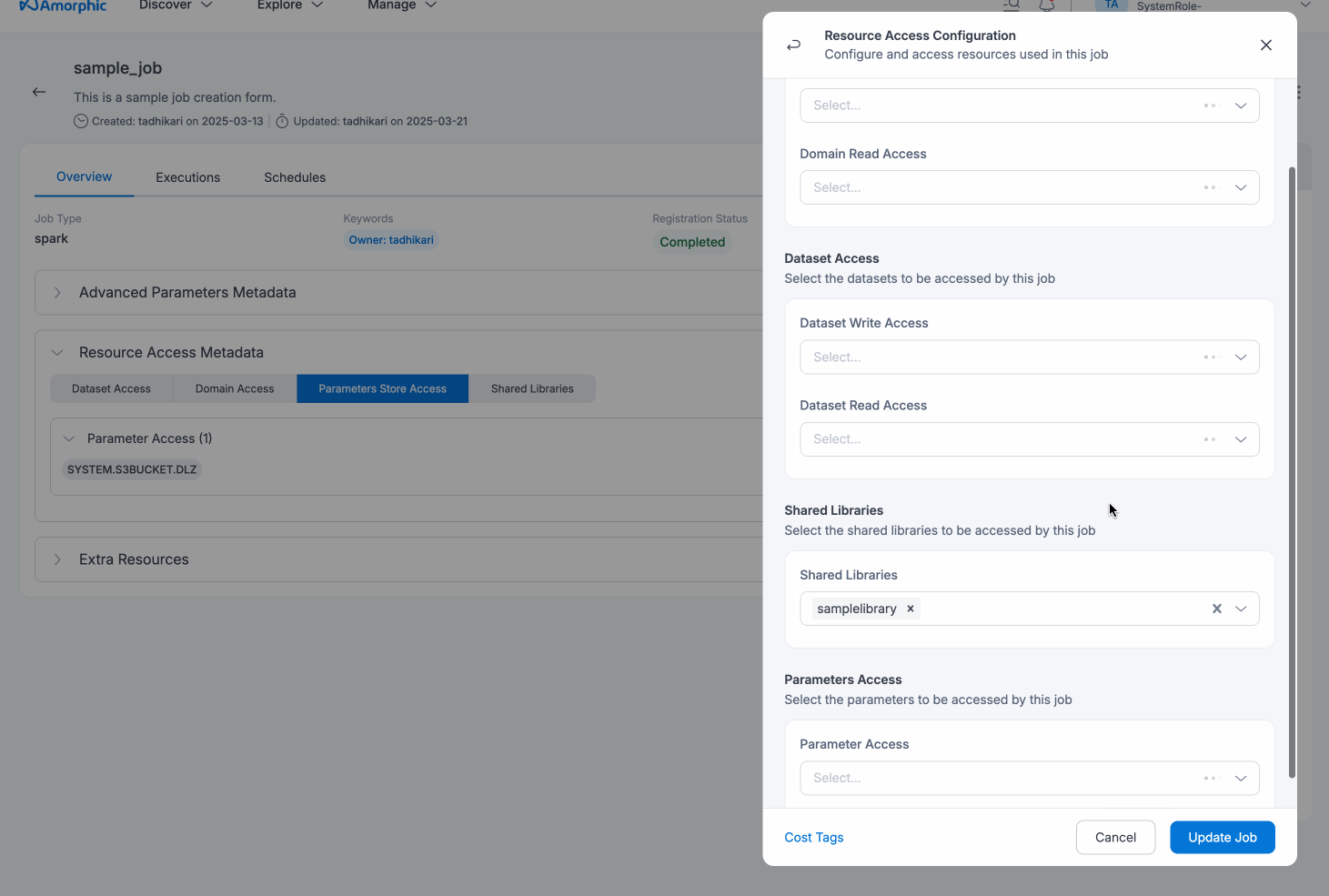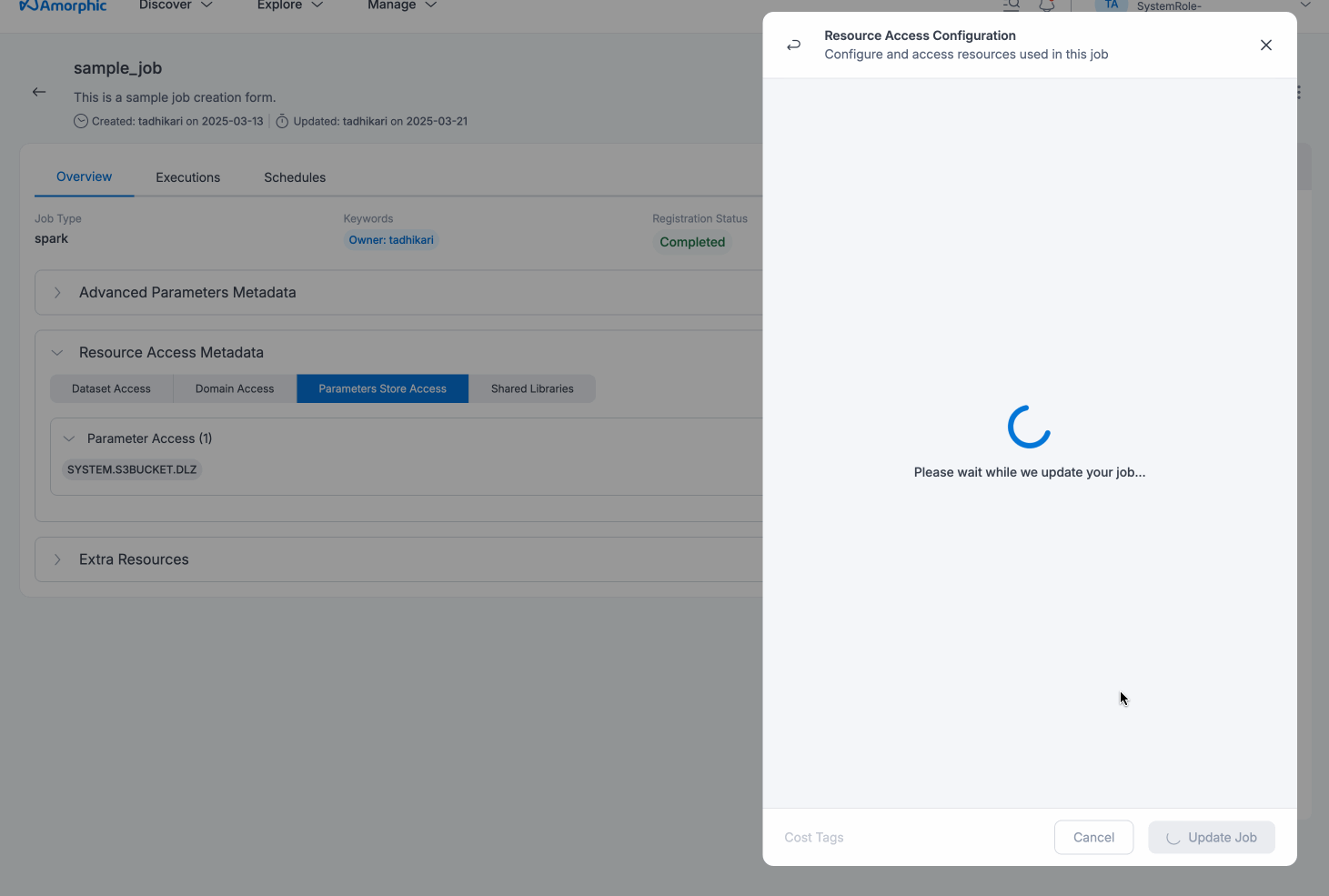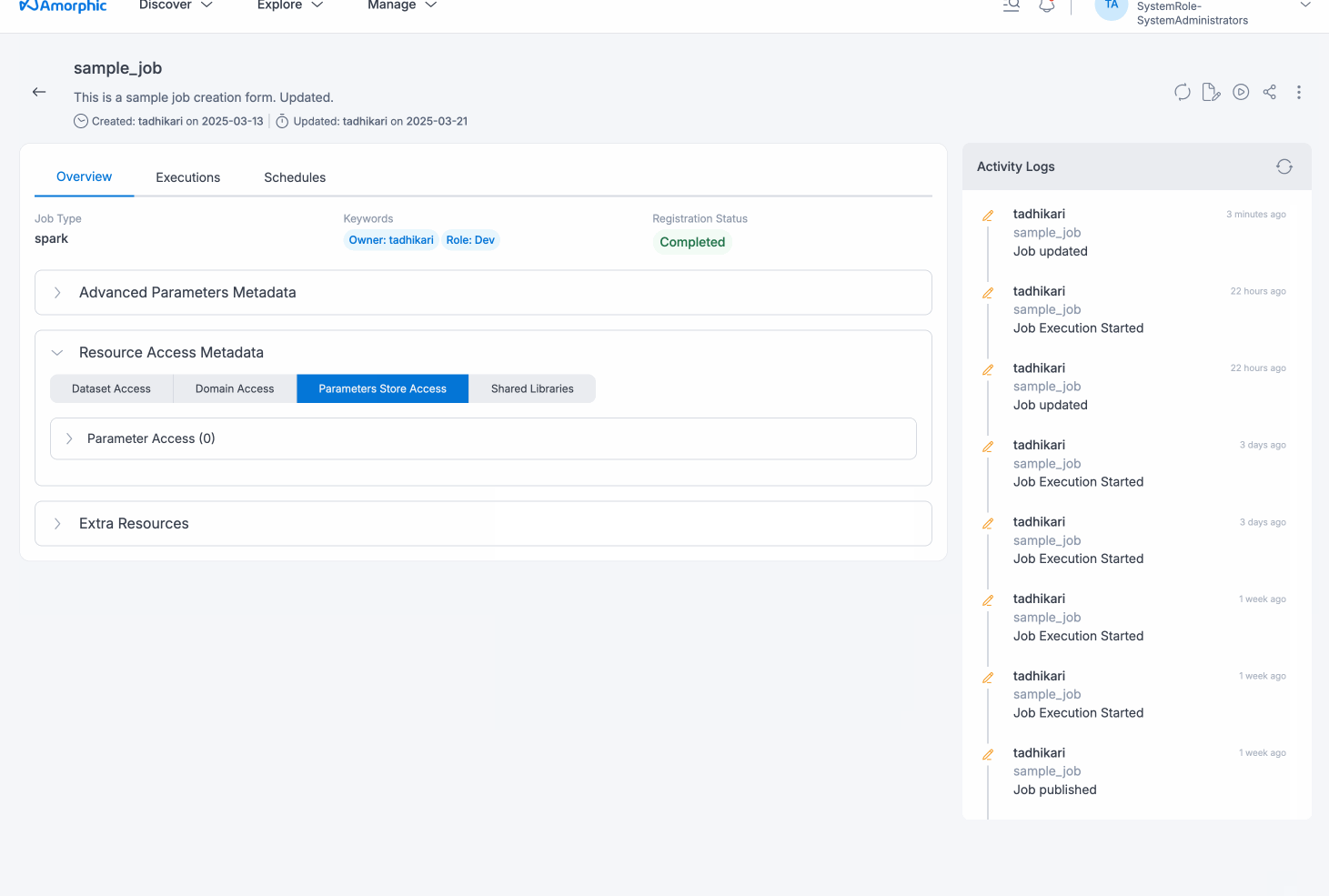
Edit Script
Job script can be edited/updated anytime using the Edit Script button. Once the script is loaded in the script editor, Turn off the read mode
and edit the script accordingly. Click on 'Save & Exit' button to save the final changes.
Only job owners can freely perform all actions on scripts. Read-only users can only view the script;granted that access to all attached resources is present; but cannot edit it.
The following visuals depicts the script editor:
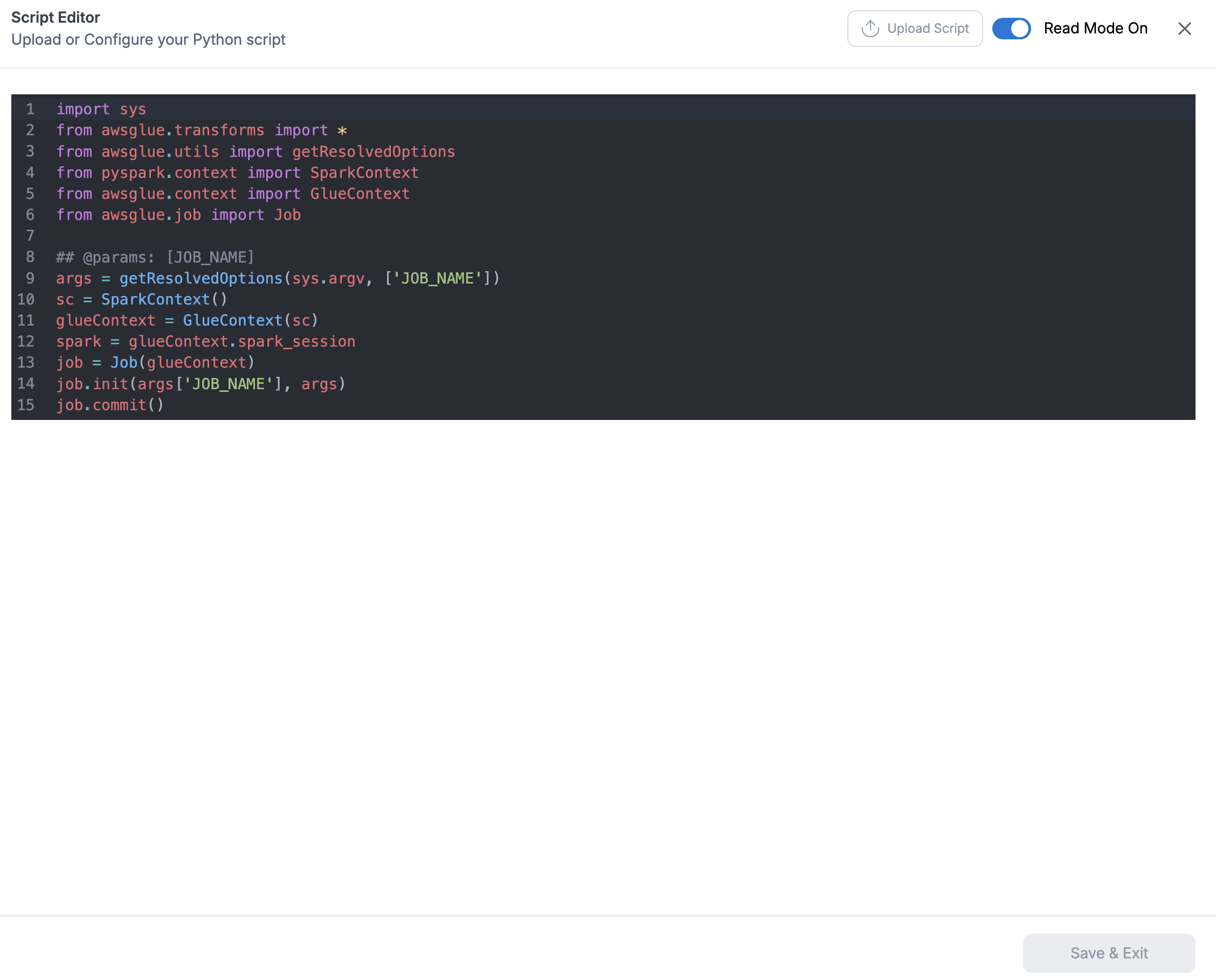
User can also load the script from a python file using the Load Script (upload) button on the top right side of the script editor.
Writing to a Dataset using Jobs
User can write a file to a dataset using jobs. Only required pre-requisite being the job has a write access on the dataset.
For instance,
If user wants to follow the Landing Zone(LZ) process and write to the LZ bucket with validations then follow the below file name conventions:
<Domain>/<DatasetName>/<partitions_if_any>/upload_date=<epoch>/<UserId>/<FileType>/<FileName>
ex: TEST/ETL_Dataset/part=abc/upload_date=123123123/apollo/csv/test_file.csv
If user want to write directly to DLZ bucket and skip the LZ process then user should set Skip LZ (Validation) Process to True for the destination dataset and follow the below file name convention:
<Domain>/<DatasetName>/<partitions_if_any>/upload_date=<epoch>/<UserId>_<DatasetId>_<epoch>_<FileNameWithExtension>
ex: TEST/ETL_Dataset/part=abc/upload_date=123123123/apollo_1234-4567-8910abcd11_123123123_test_file.csv
Manage External Libraries
Users can upload external libraries to ETL job using the Manage External Libraries option from the three dots on the top right side of the details page. These external libraries allow end user to utilize their own custom modules in ETL jobs to perform specific tasks.Uploaded library file(s) will be displayed in the details page immediately.
To upload an external library, users can click the + sign on the top right; next Select files to upload and then Upload Selected Files button after selecting the files to upload one or more library file(s). The following example shows how to upload external libraries to an ETL job:
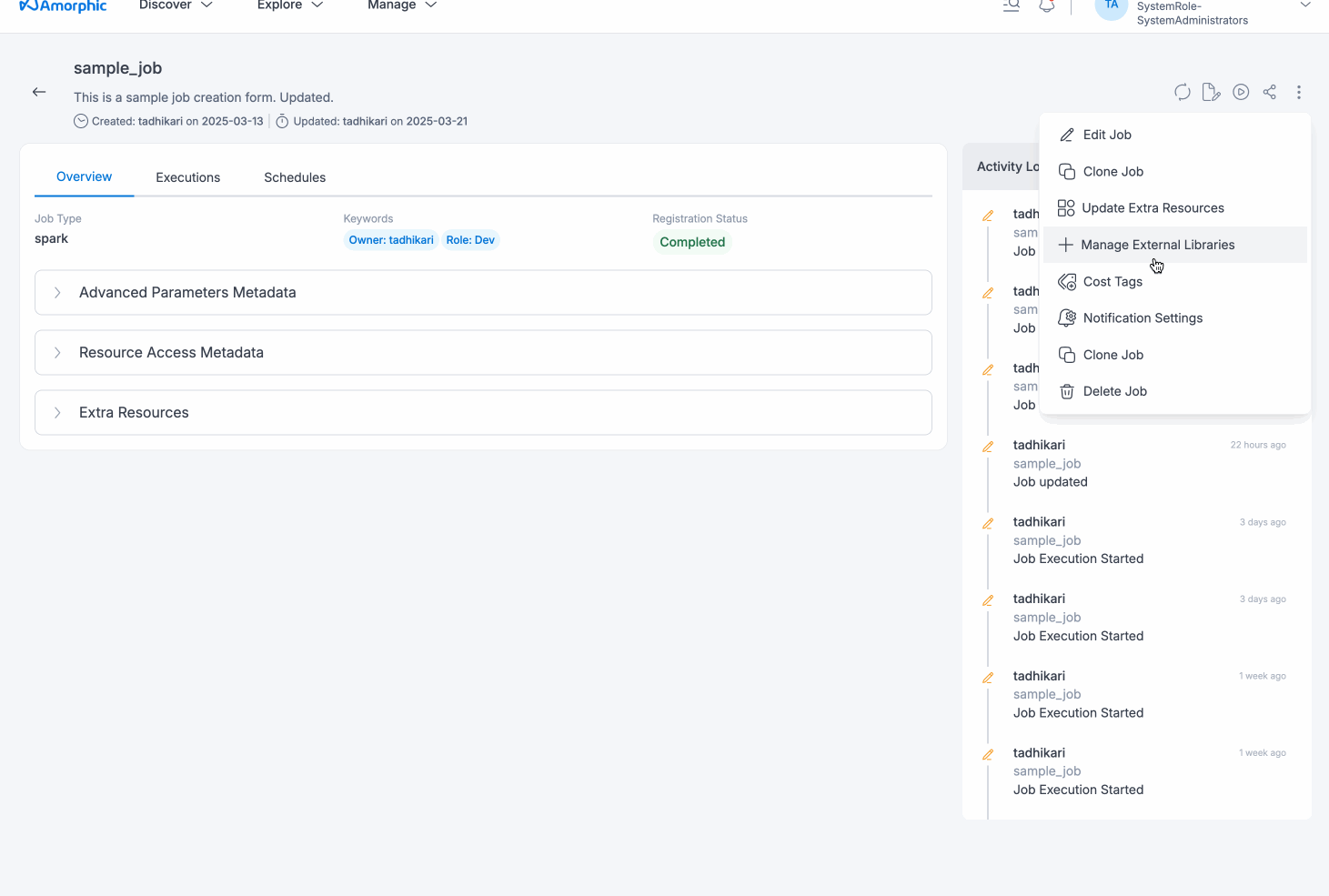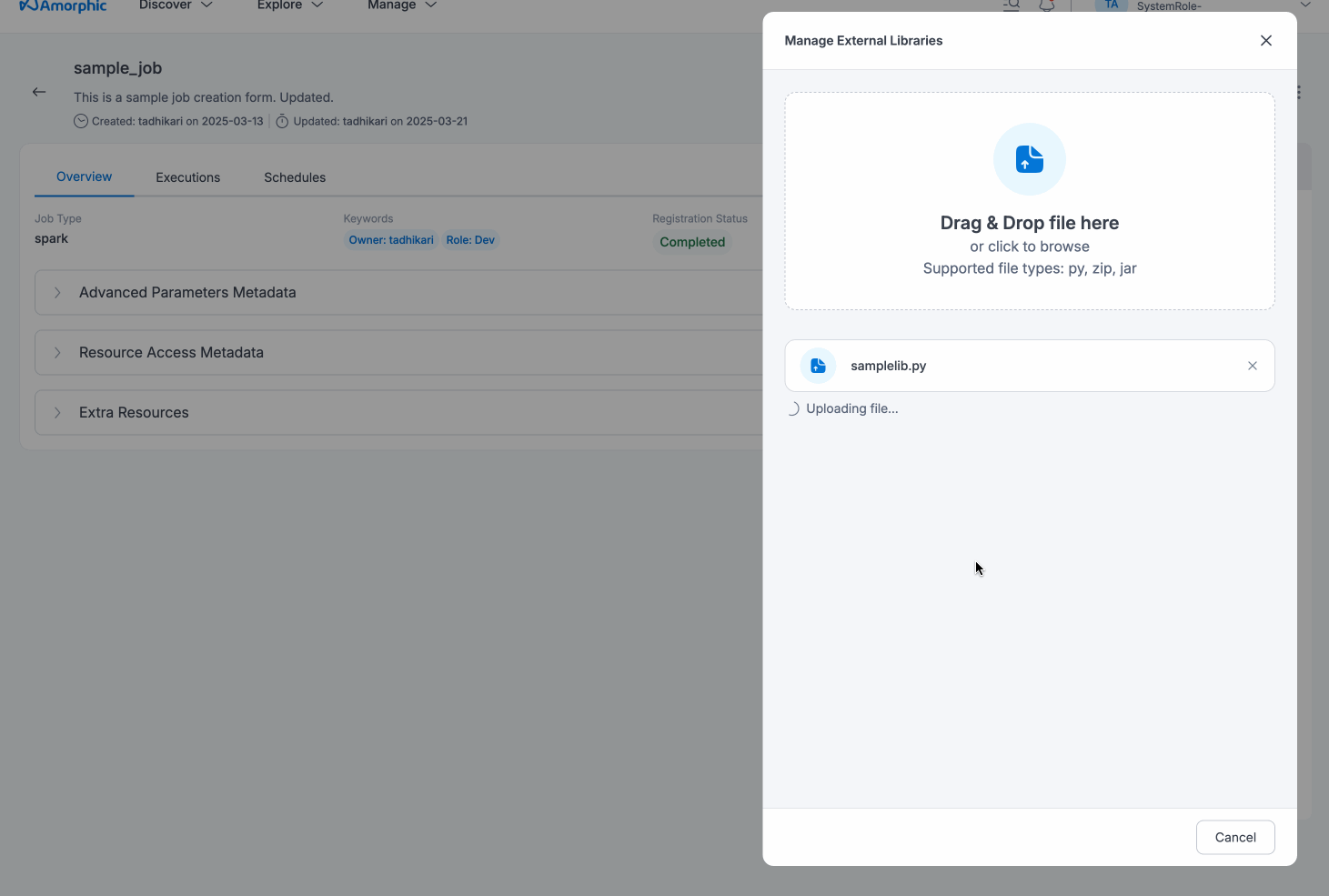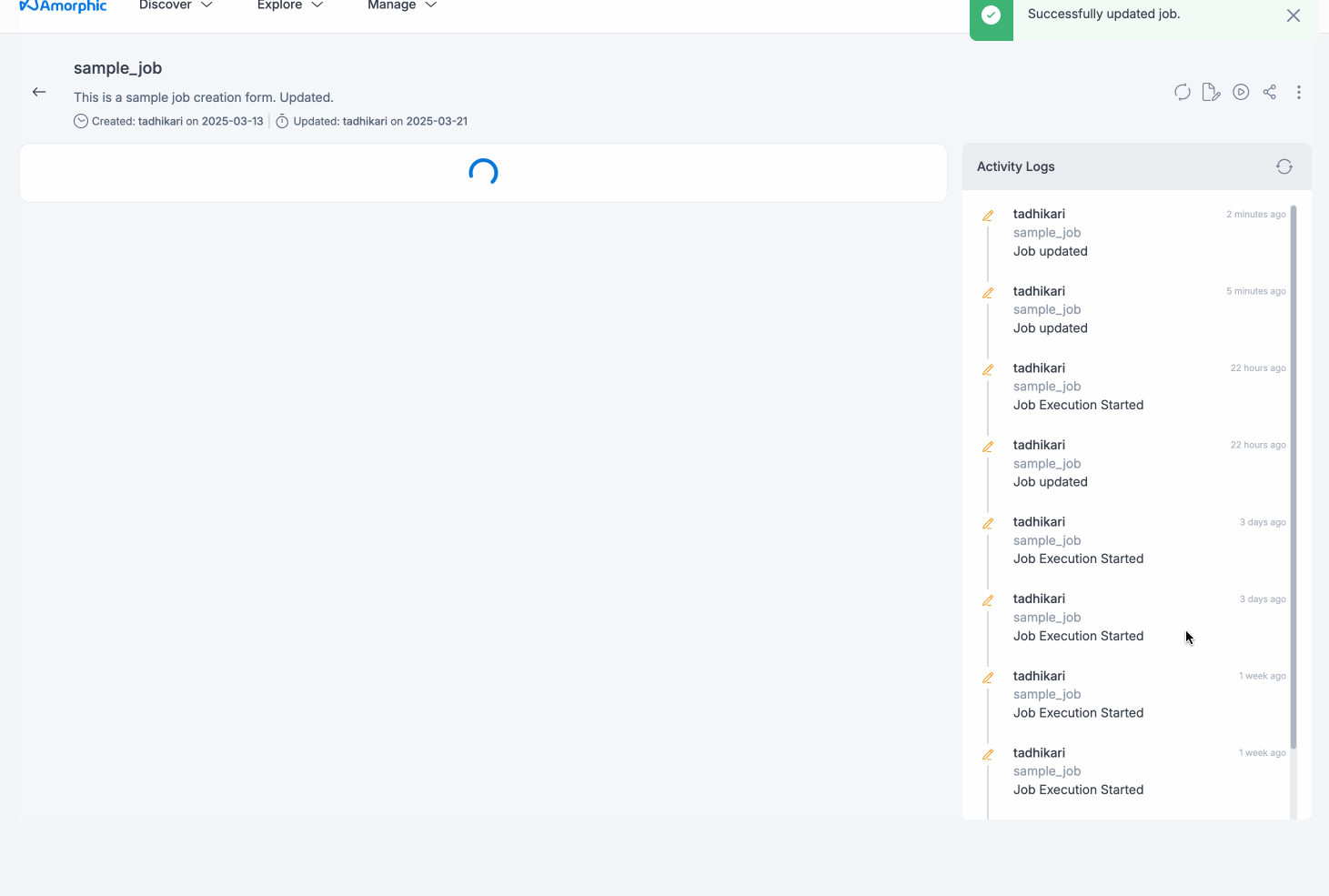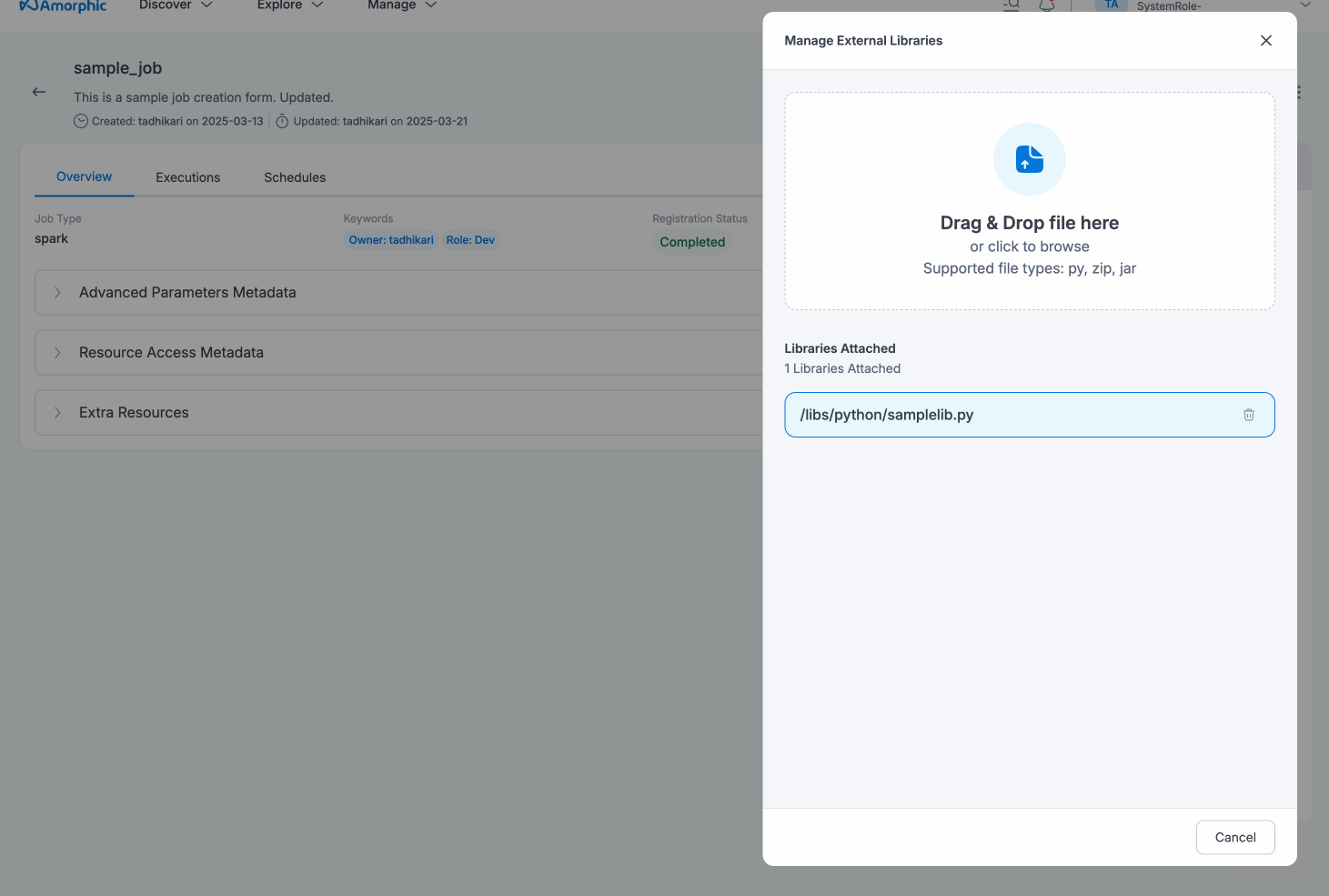
Users can remove the external libraries from the ETL job by selecting the libraries and clicking on the Remove selected libraries button in Manage External Libraries. User
can also download the external libraries by clicking on the download button displayed on the right of each uploaded library path.
Update Extra Resource Access
To provide access of resources under Amorphic, such as datasets, parameters, shared libraries, etc to a job in large number, use the documentation on How to provide large number of resources access to an ETL Entity in Amorphic
In light of upcoming end of support for PythonShell(Python version 3) end of support and Spark(Glue version 0.9, 1.0 and 2.0) end of life for stable version of Amorphic 3.0, users are recommended to migrate any existing old jobs to newer supported versions. These updates will go live on 1st April, 2026.
- For users of Spark jobs(of Glue version 0.9, 1.0 and 2.0), update the jobs to newer versions(available versions are 3.0, 4.0 and 5.0 which are supported) to avoid any issues in future.
How to upgrade:
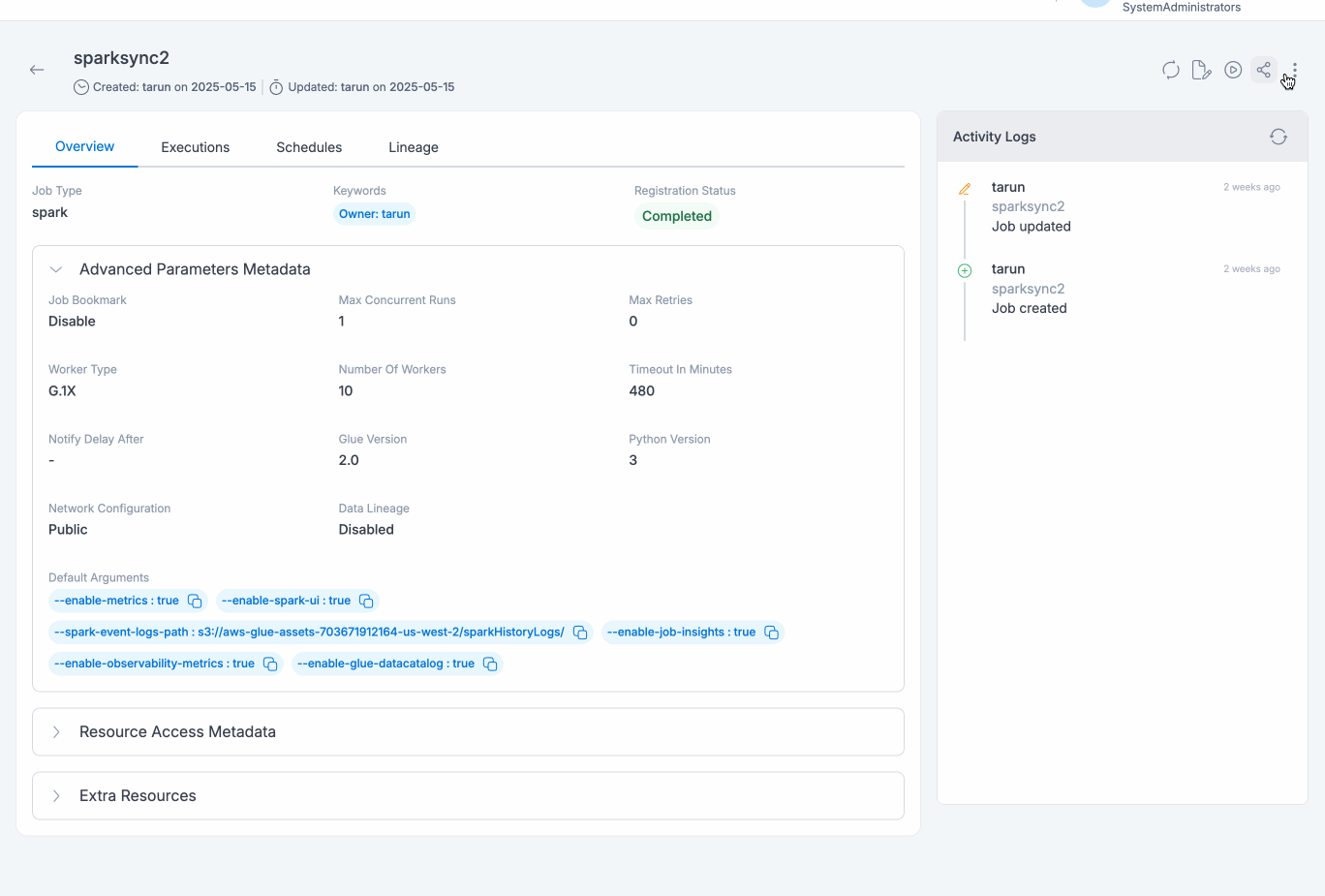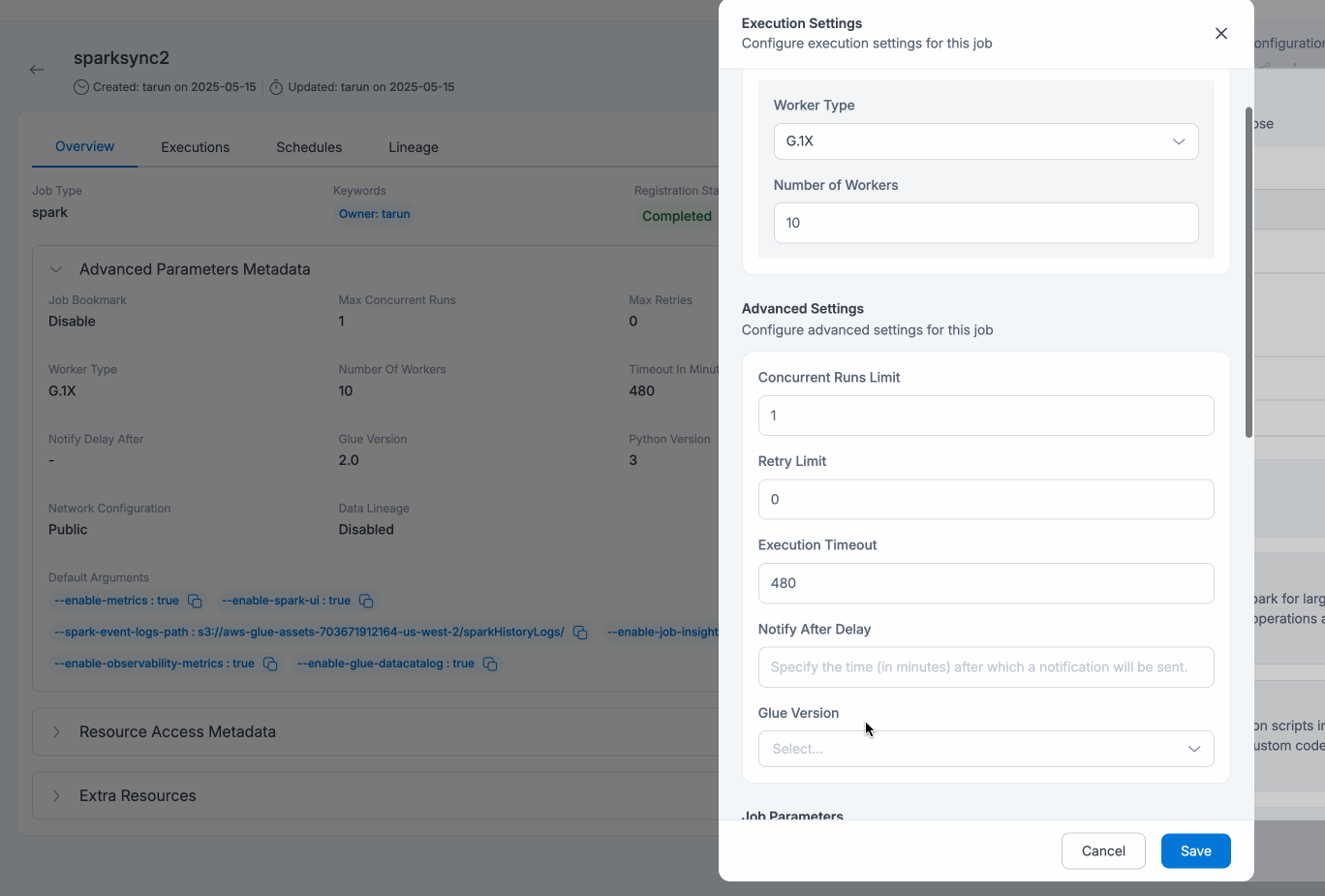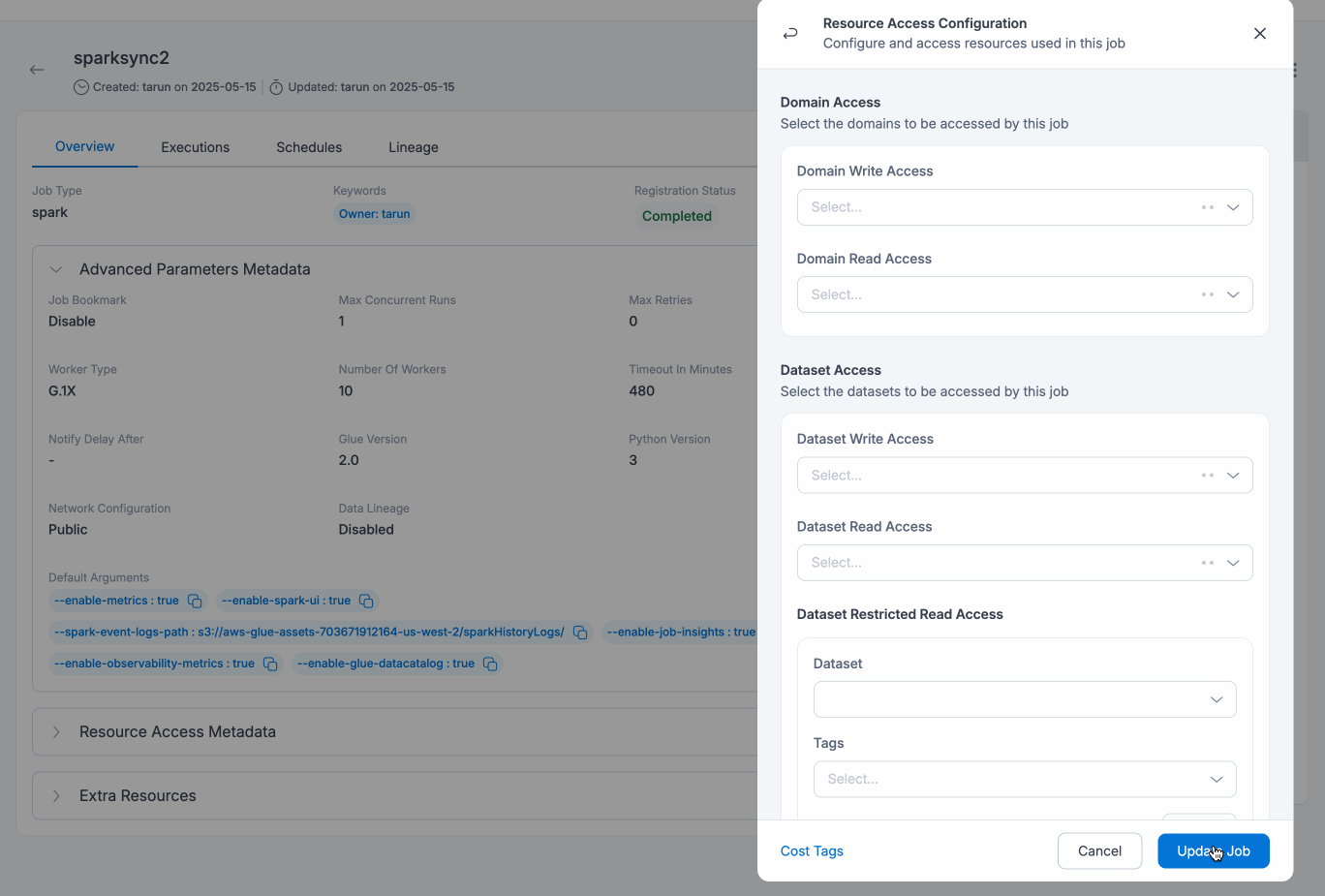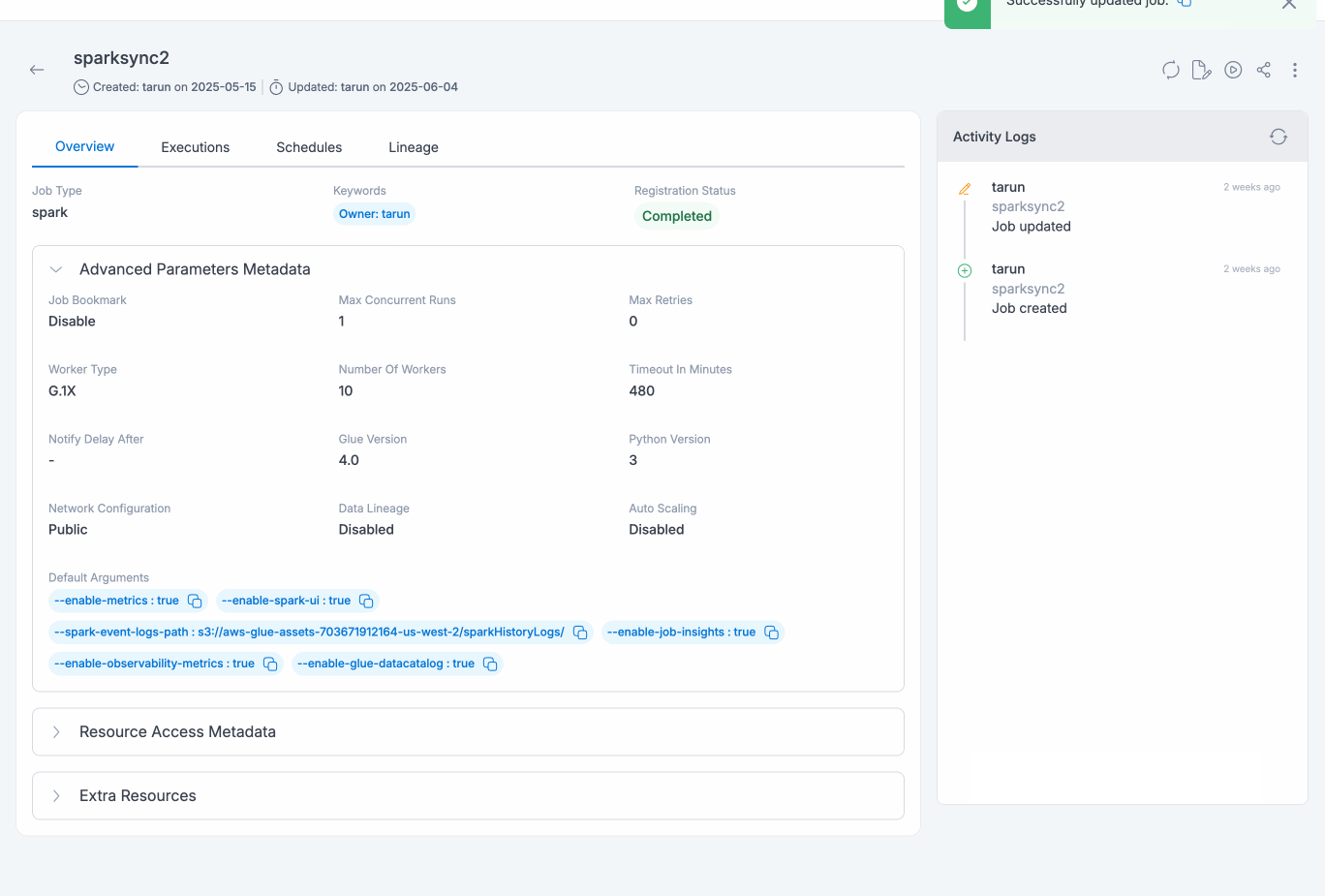
- For users of PythonShell jobs(of Python version 3), recommendation is the same to upgrade the respective jobs to version 3.6(Jobs will still run for version 3 but no security or maintenance updates would be provided)
How to upgrade:
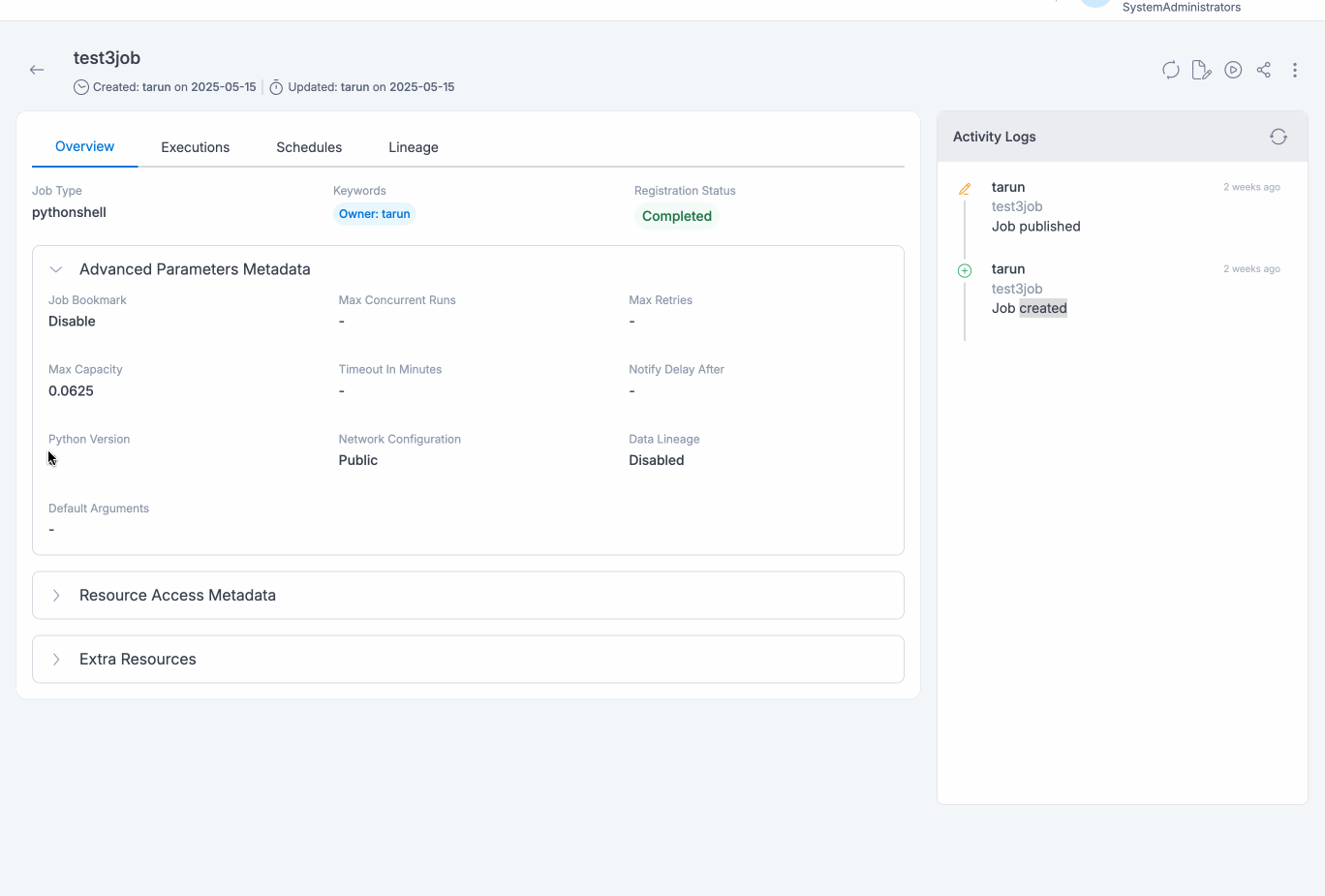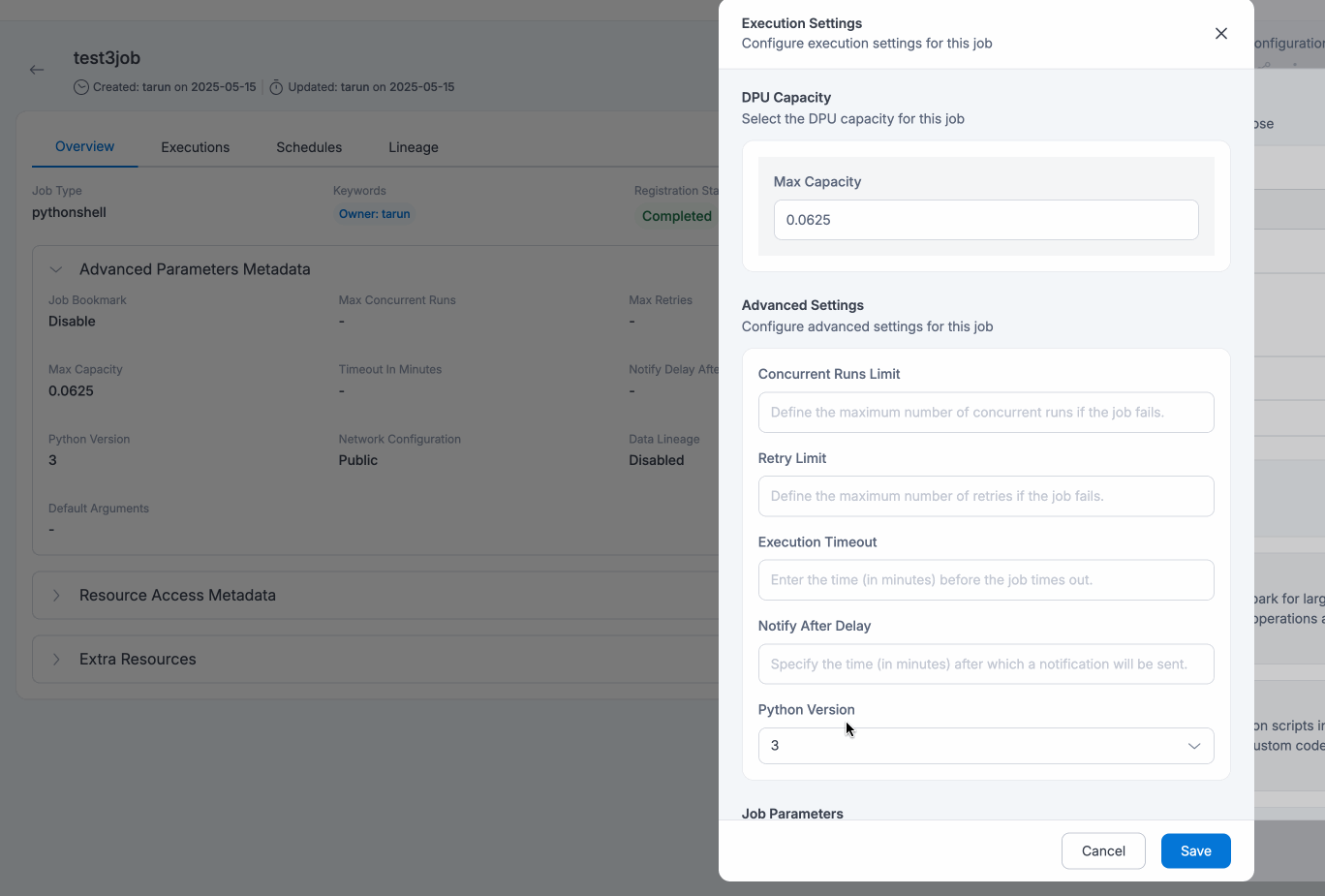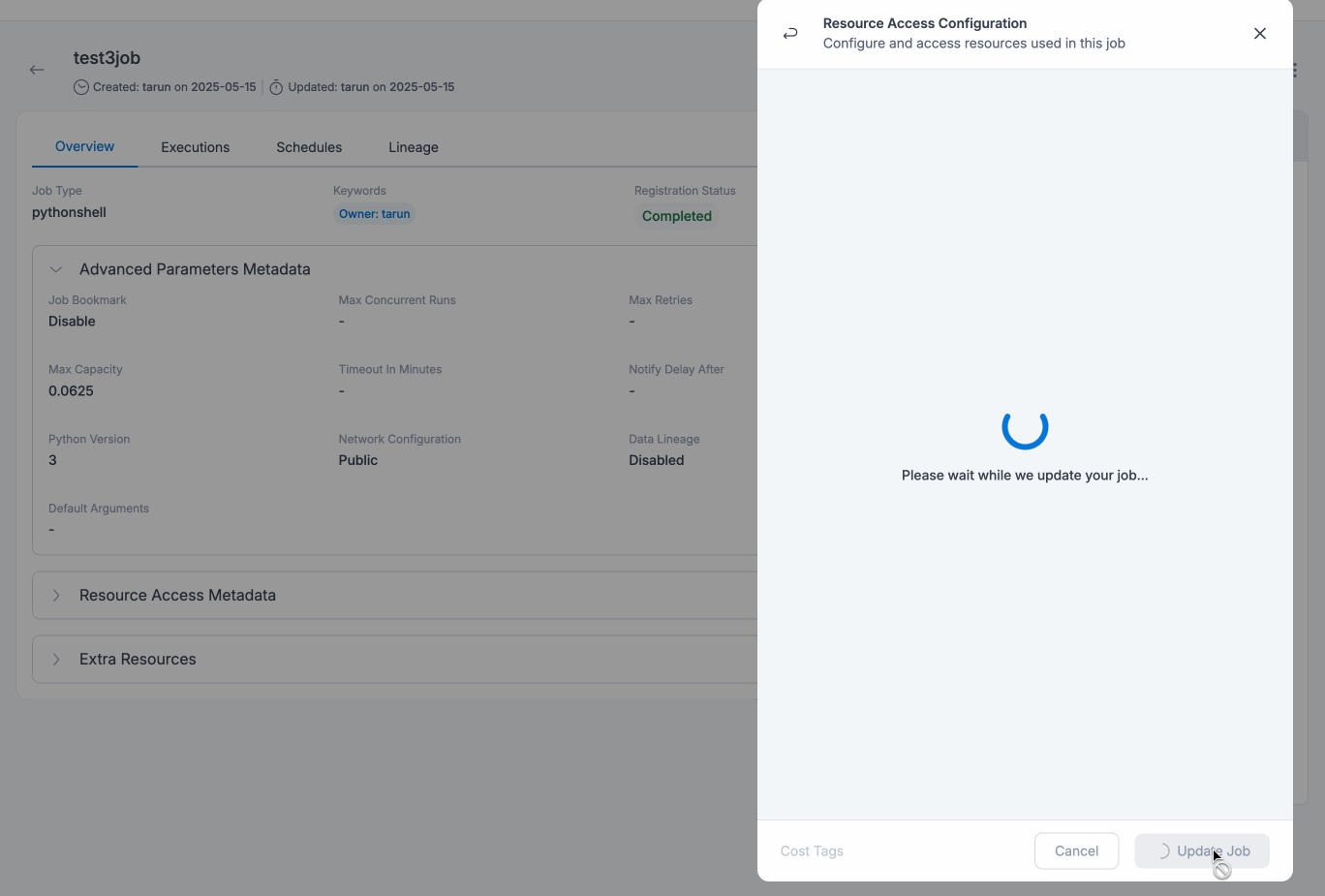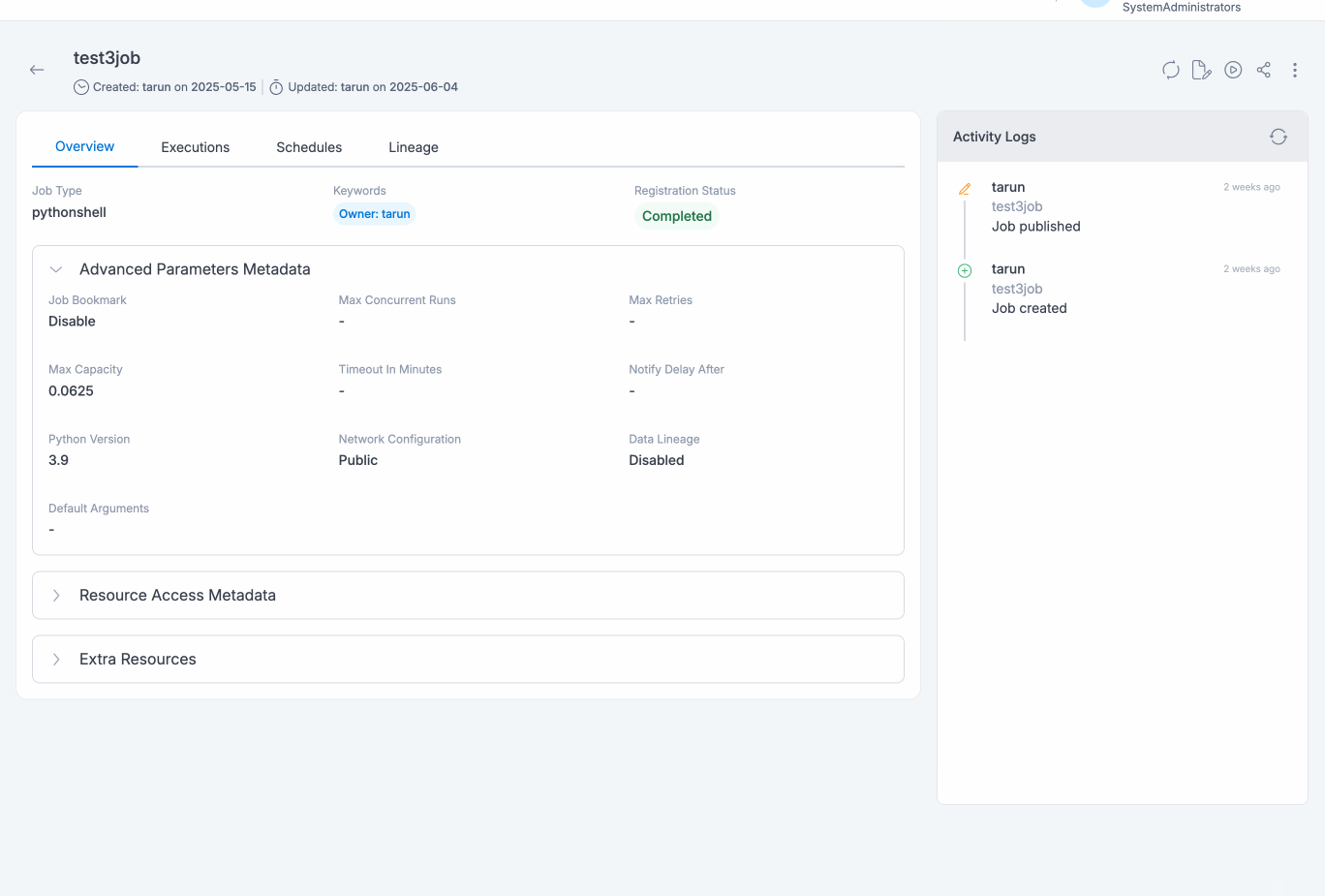
Run Job
To execute the Job, click on the Run Job (play icon) button on the top right side of the page. Once a job run is executed, refresh the execution status tab using the Refresh button and check the status.
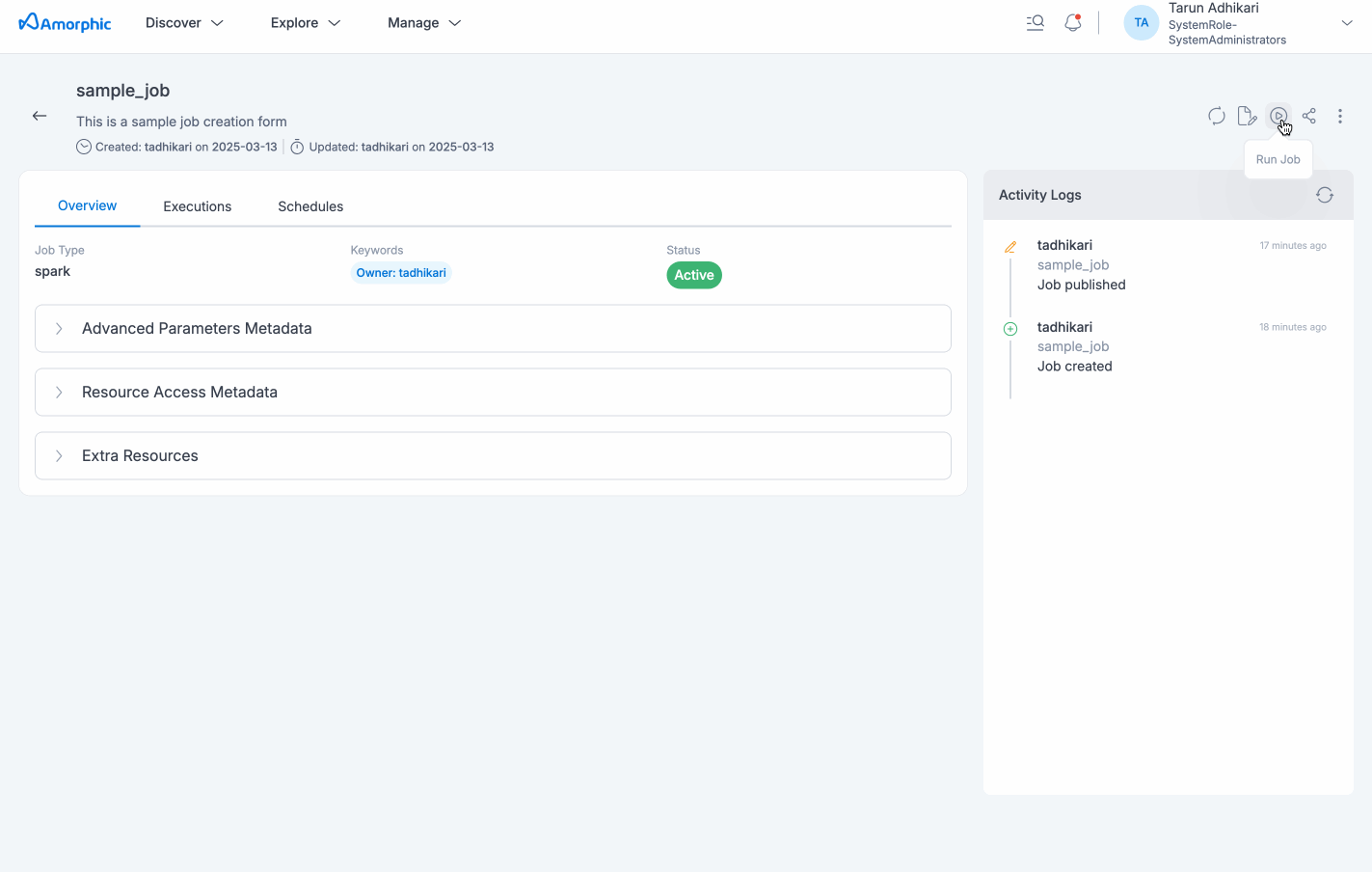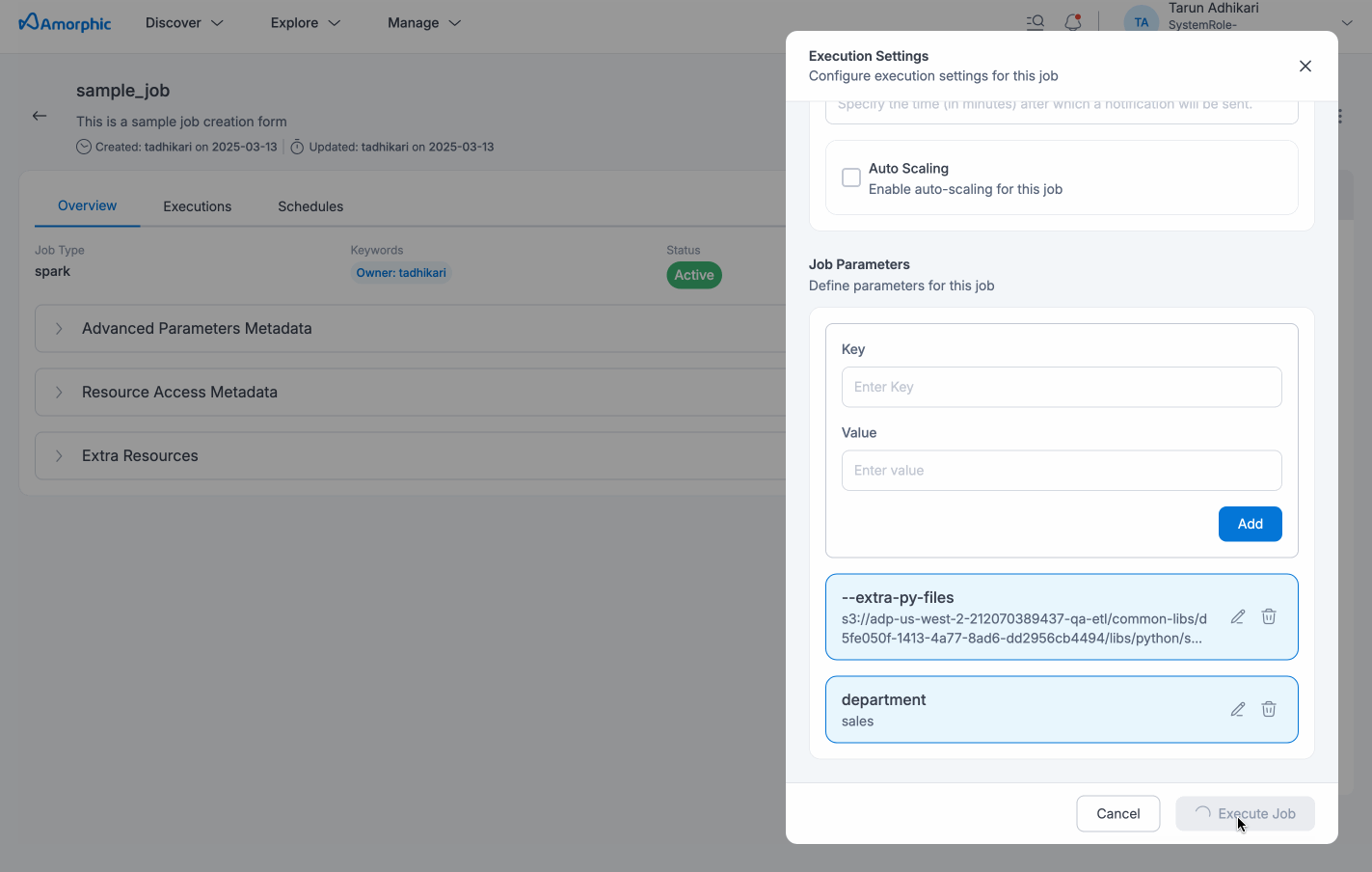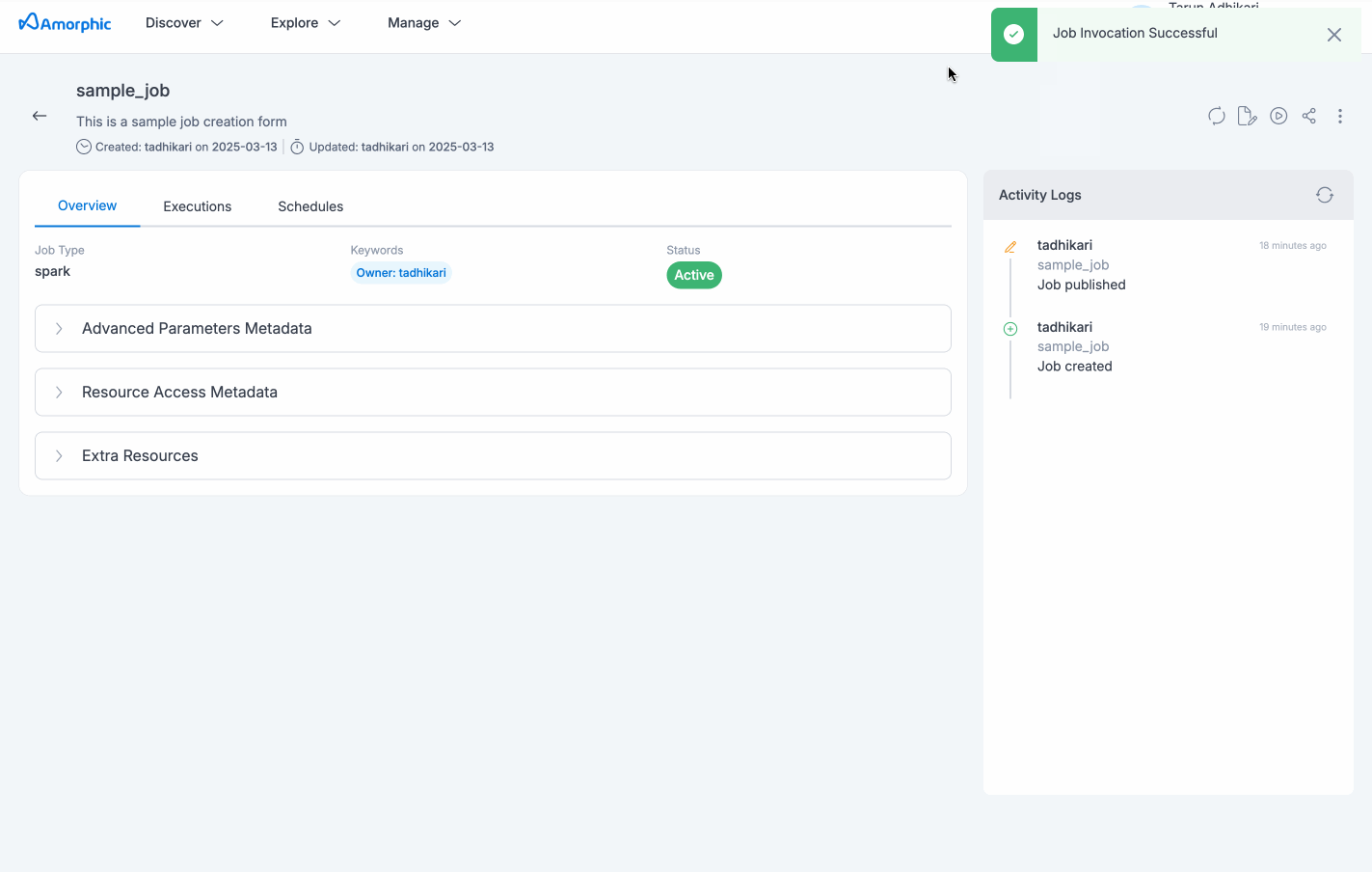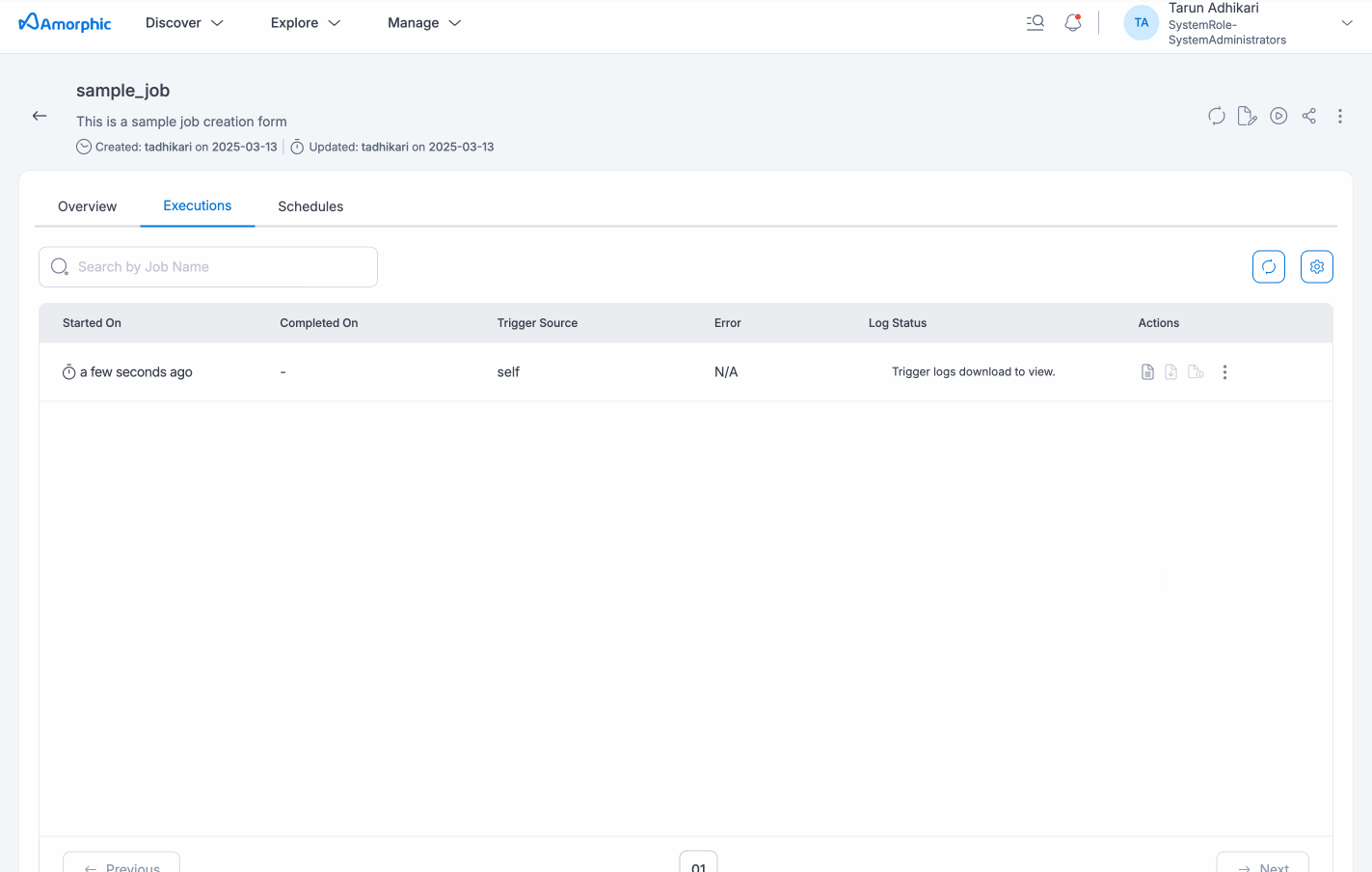
Based on the access level of the job, user can perform this trigger action:
Owner: Based on the access to the attached resources( like datasets, parameters, etc), user can trigger the job i.e. if access to all underlying resources is present, then the job can be triggered.
Read-only: Users with read-only access can view the job execution details but cannot trigger the job.
Once the job execution is completed, Email notification will be sent based on the notification setting and job execution status.
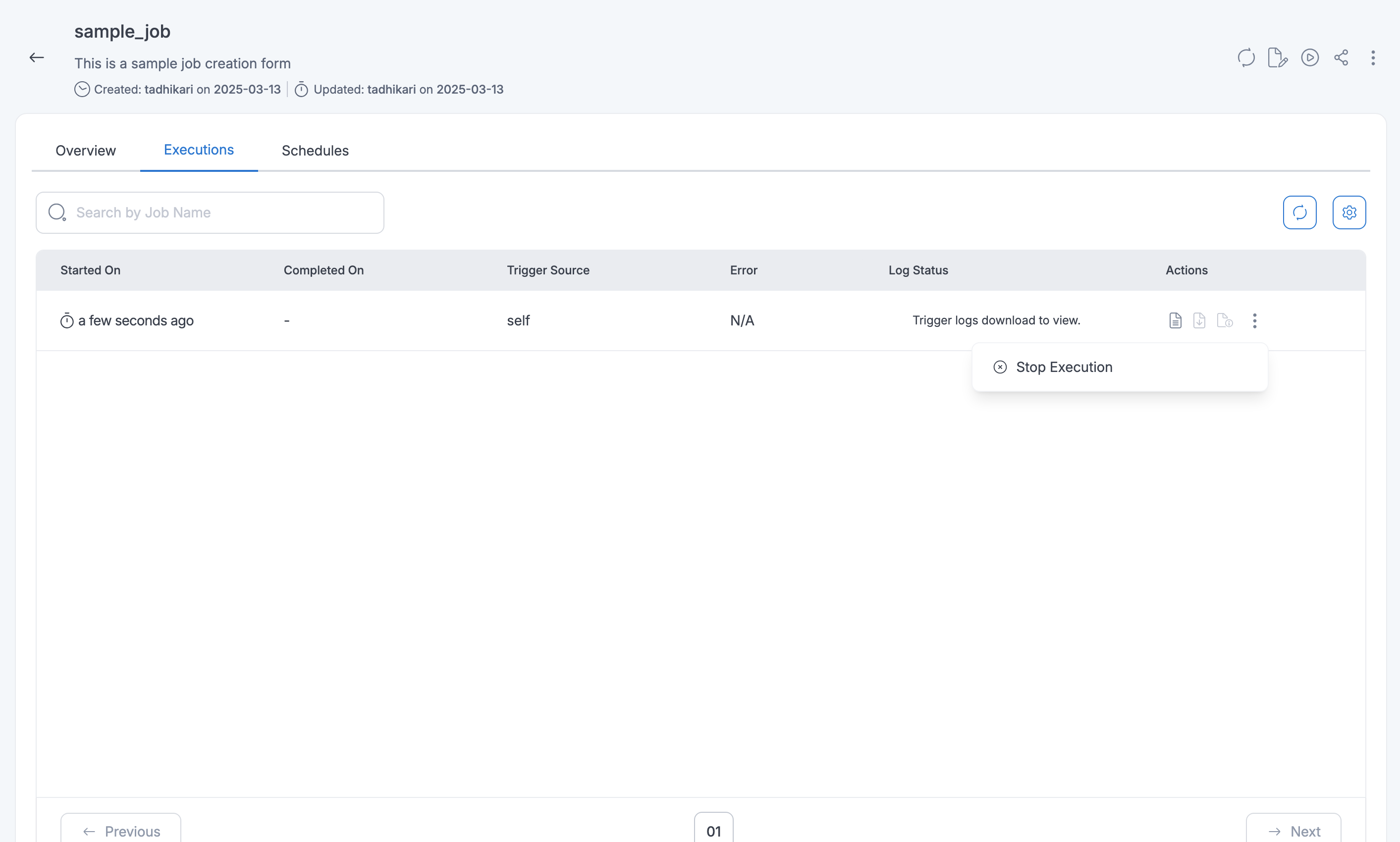
User can stop/cancel the job execution if the execution is in running state.
The following picture depicts how to stop the job execution:
User might see the below error if the job is executed immediately after creating it.
Failed to execute with exception "Role should be given assume role permissions for Glue Service"
In such scenarios, user is recommended to reattempt execution again.
Job executions
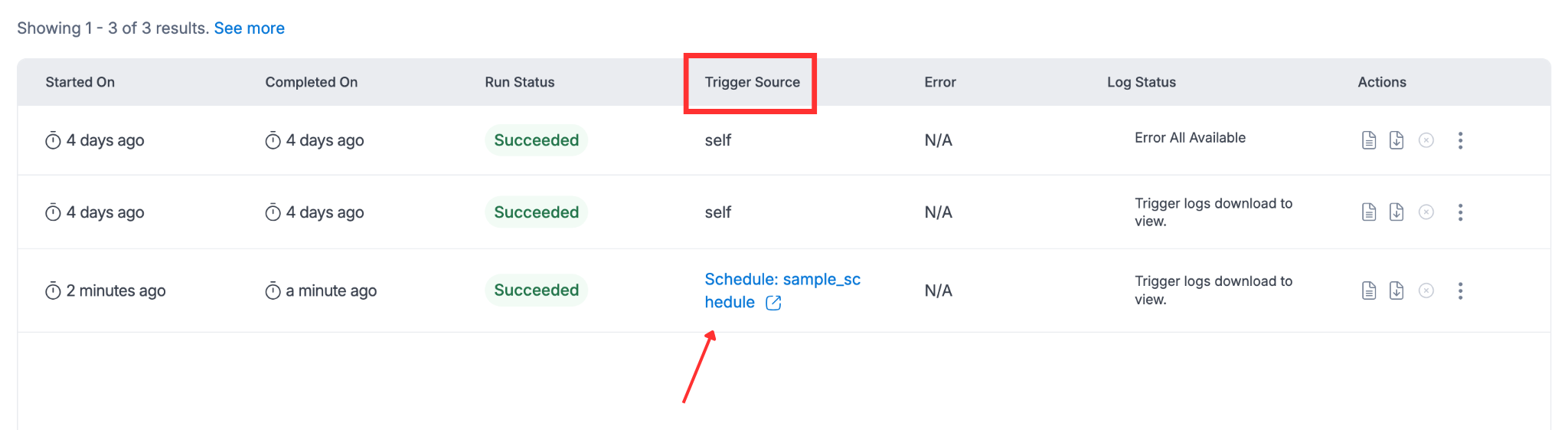
User can filter through & find all the executions in the Execution tab. The job executions also contain executions that have been triggered via job schedules, nodes in workflows, and workflow schedules. Also, if the Job has Max Retries value then the job will display all the executions including the retry attempts.
User can also check the corresponding Trigger Source for the execution entry on the same page.
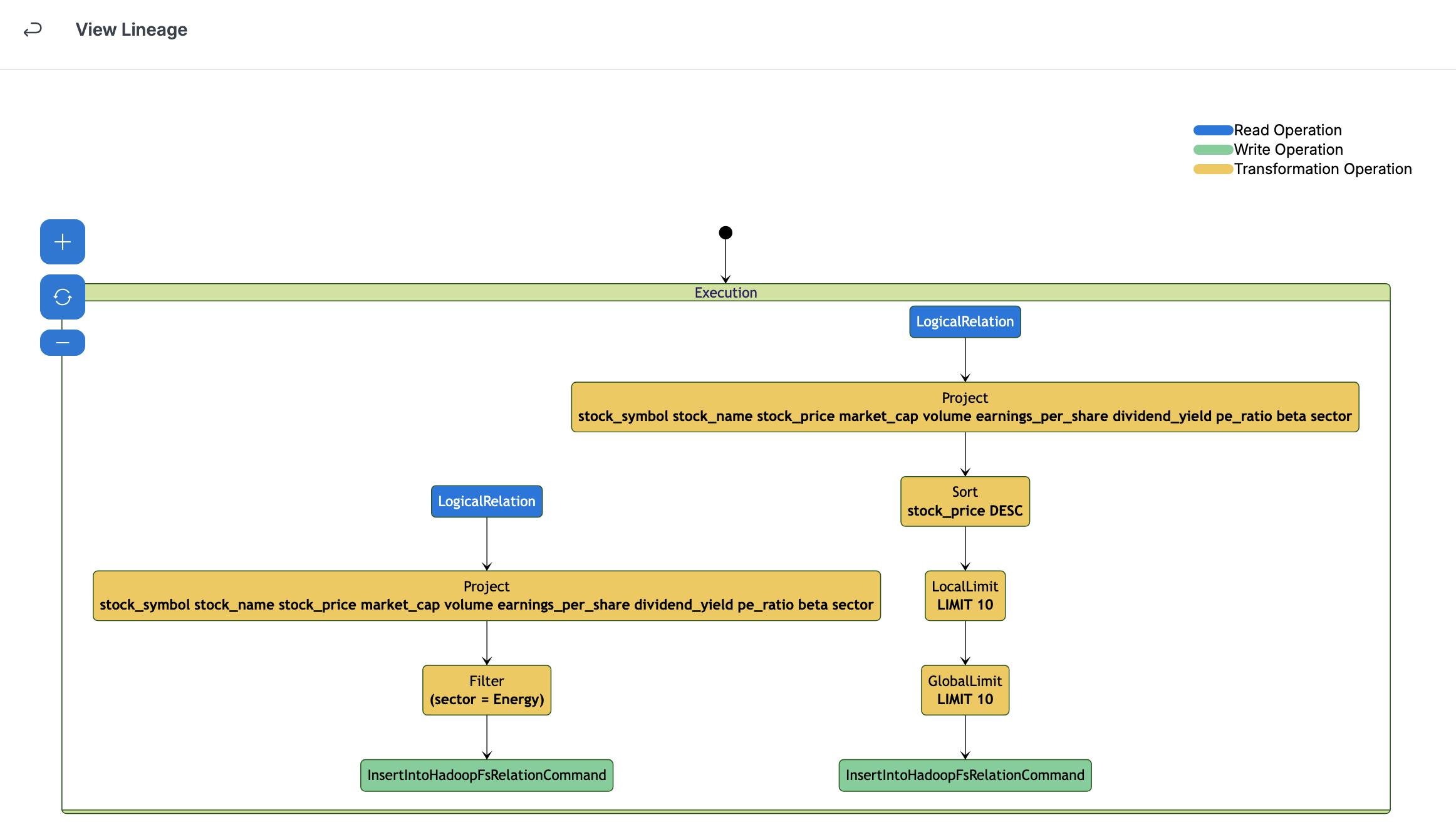
If Data Lineage is enabled, the generated data lineage, if available, can also be viewed here.
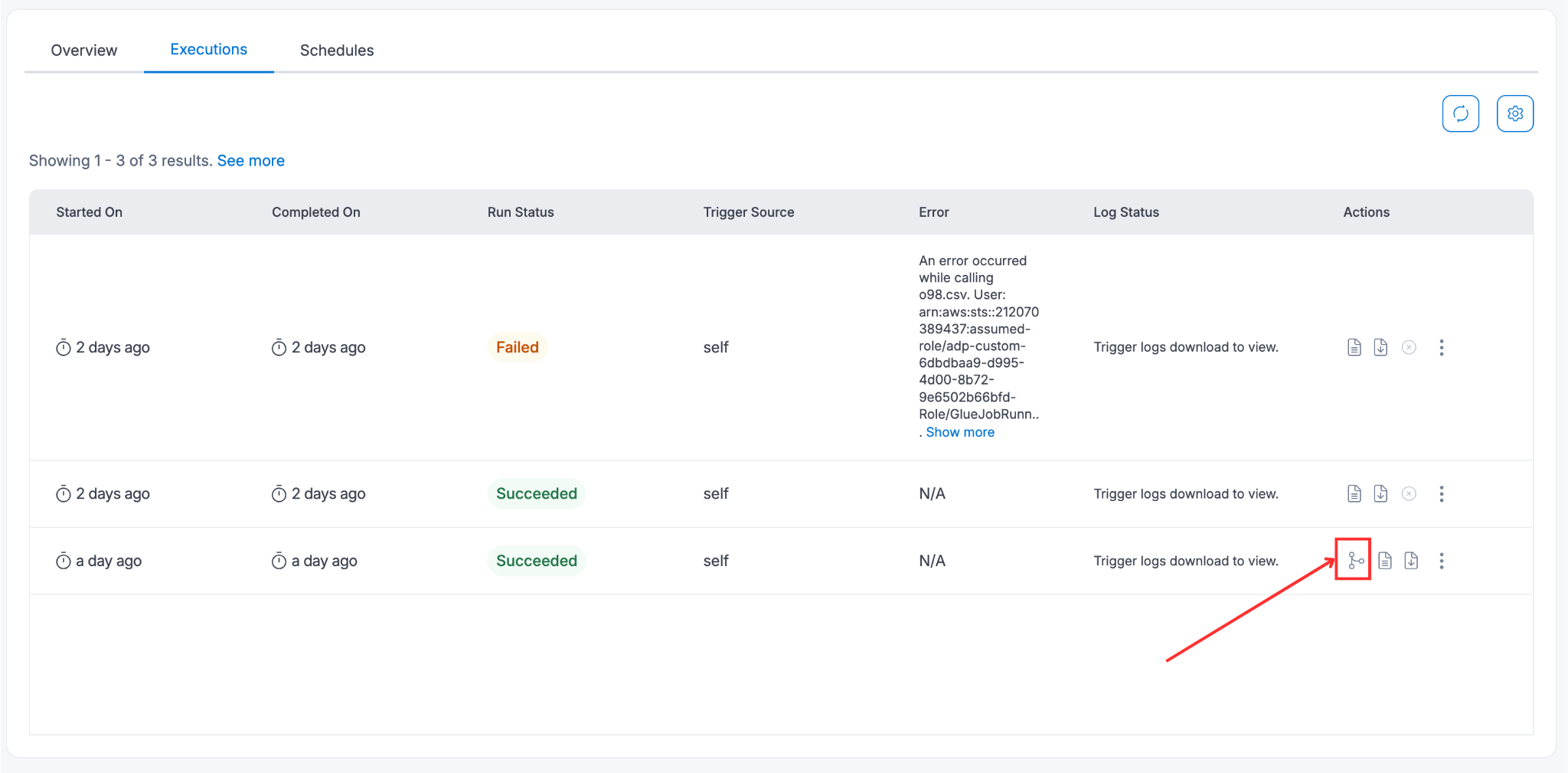
This would show user the operations that have been performed on the data during the execution of the spark job. There can be read operations, transformation operations, and write operations. In an IP whitelisting enabled environment, data lineage cannot be enabled for jobs with Public Network Configuration. For others, the Elastic IP address, which is the public IP of the source, needs to be whitelisted.
Job Logs
Starting from version 2.7, users have access to enhanced logging features, including Download All Logs and Preview Logs, to help track the performance and status of their Glue jobs more effectively.
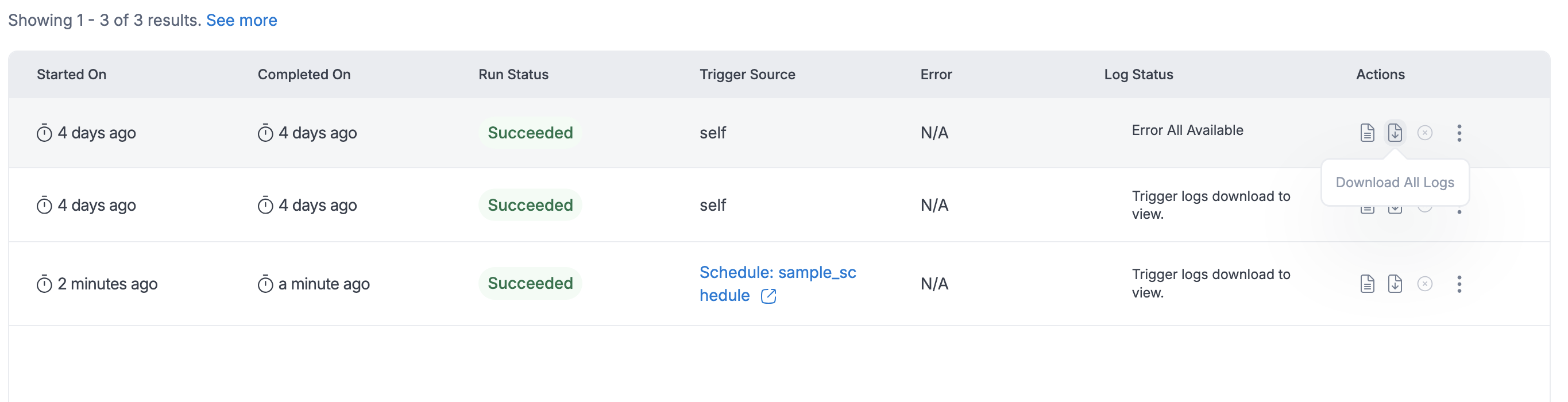
Download All Logs - After a Glue job completes, users will have the option to download logs for further analysis. They can choose between Output Logs (which track successful execution details) or Error Logs (which capture any issues or failures during the job). These logs provide a complete record of the job's execution and are available only after the job finishes.
When users click on Download All Logs, the log generation process is triggered, and the status will update to Logs Generation Started.
Once the logs are generated, the status will be updated to reflect completion, at which point users can download the logs. This streamlined process allows users to download the logs most relevant to their needs, making it easier to troubleshoot issues or review performance.
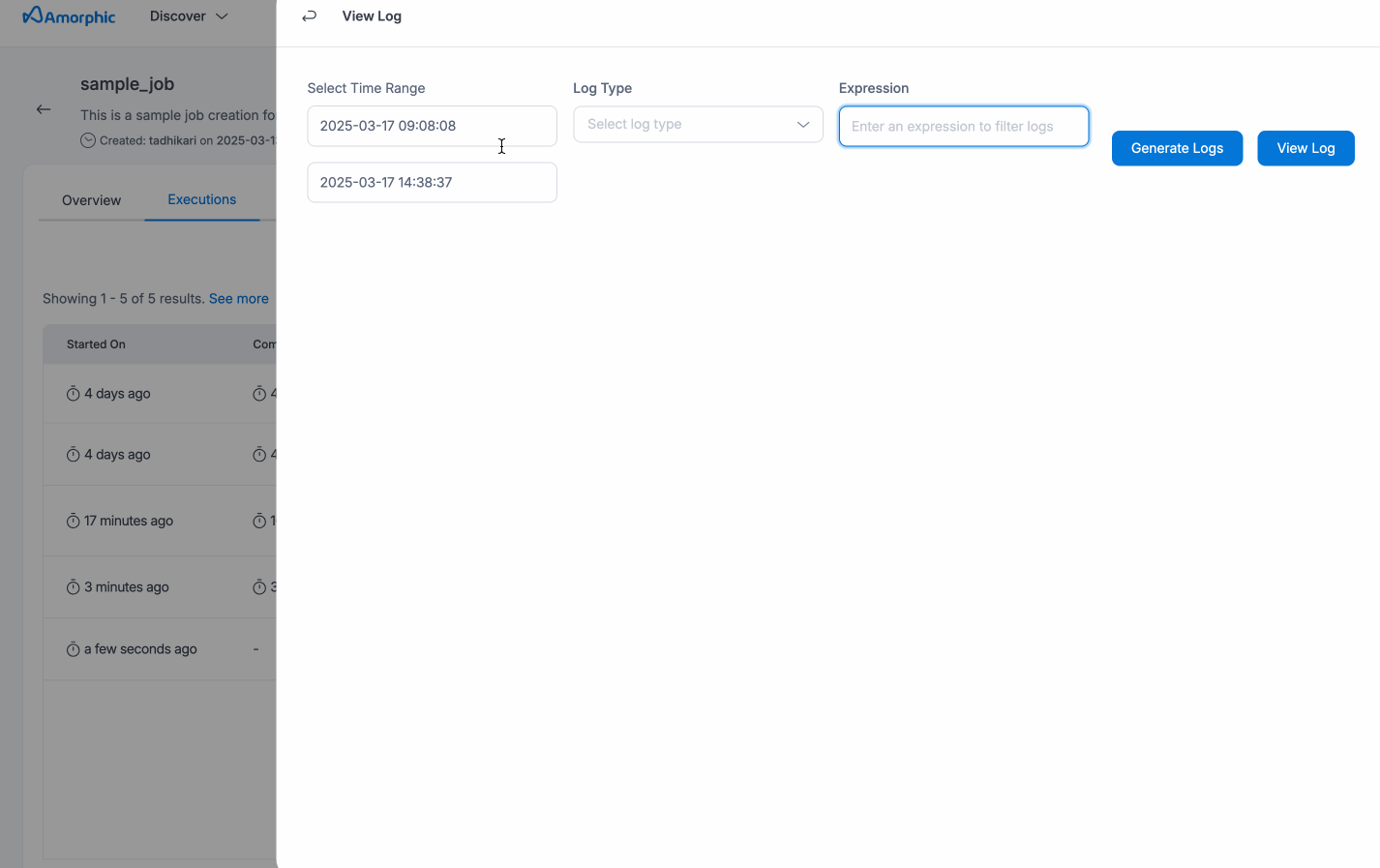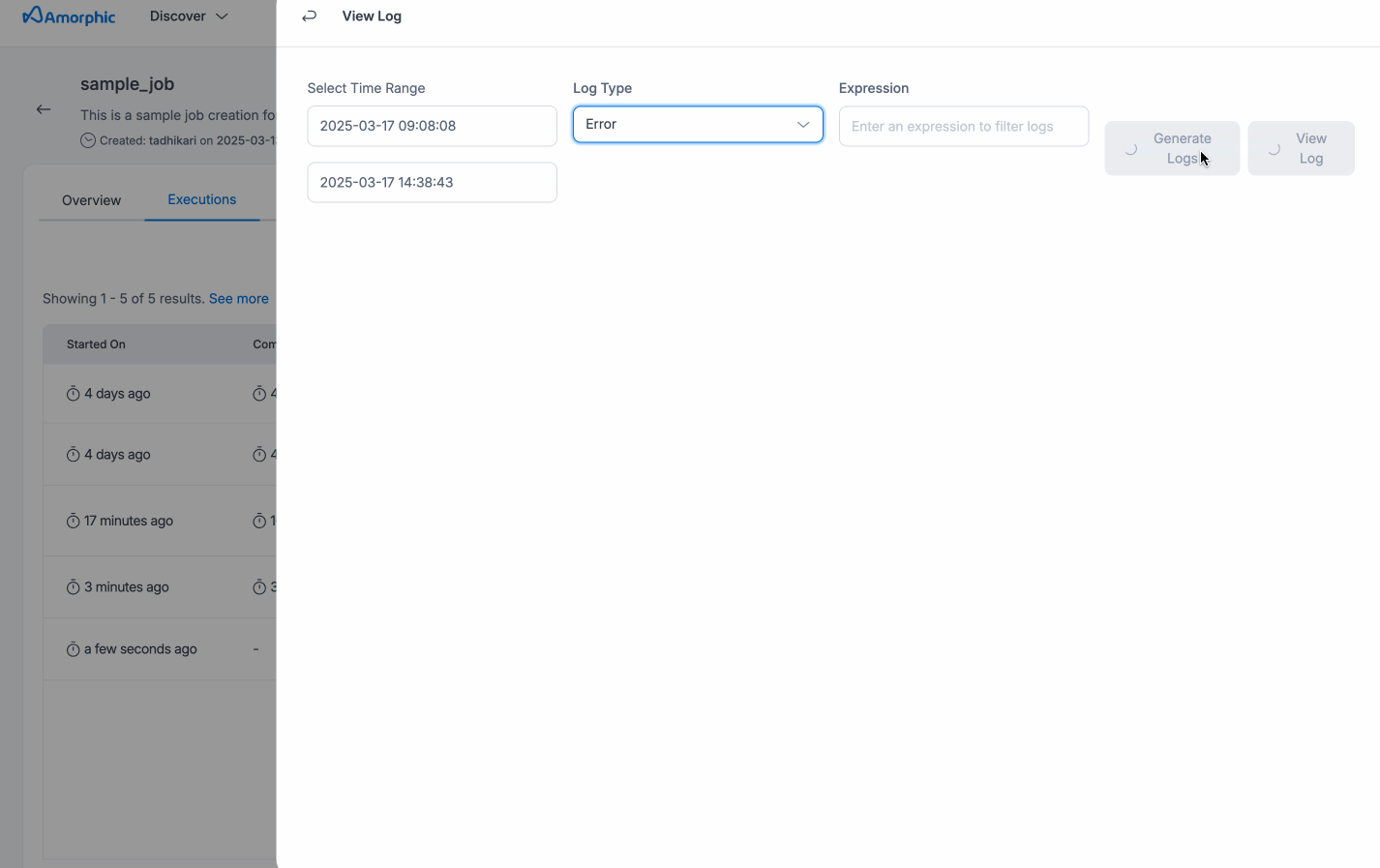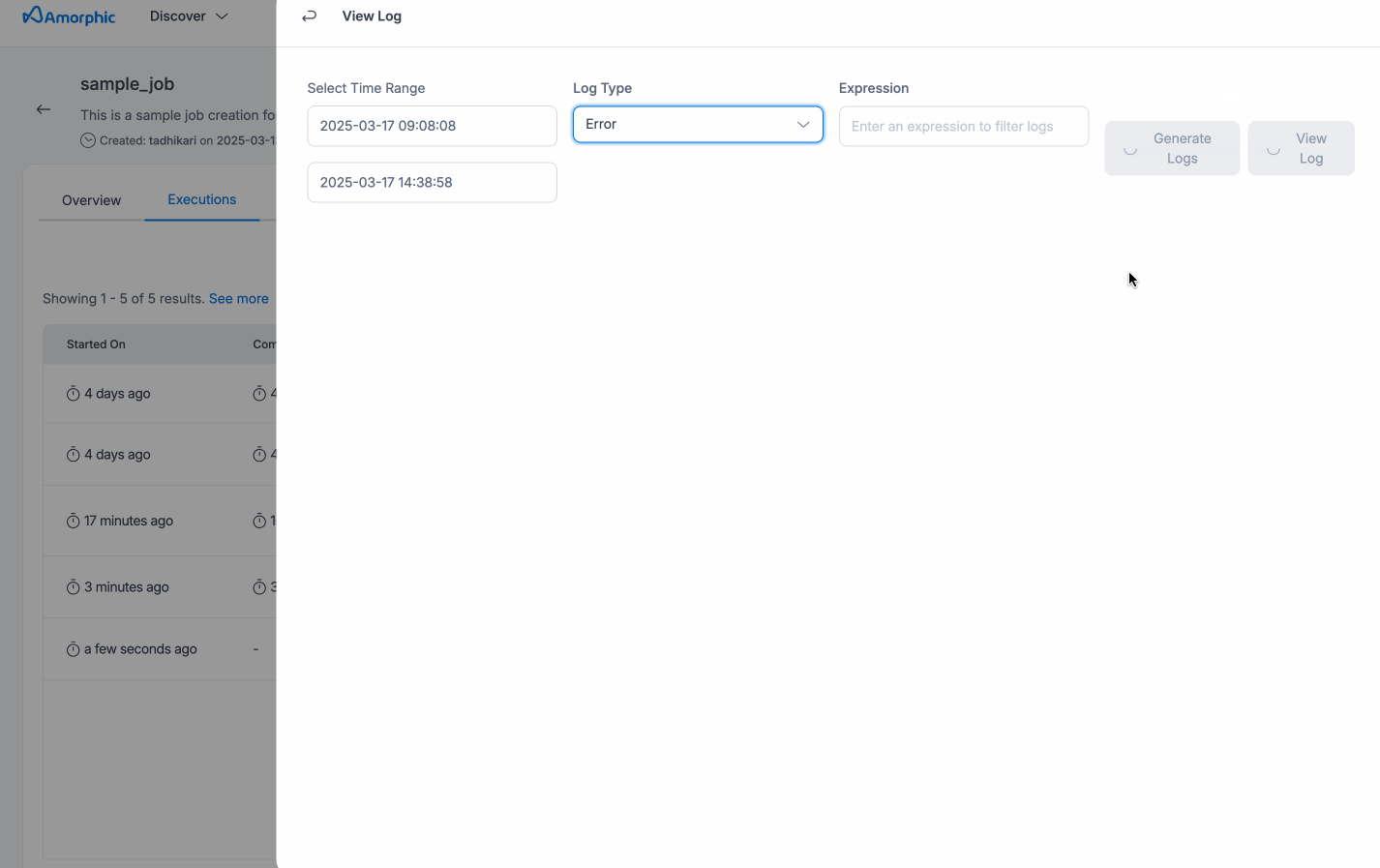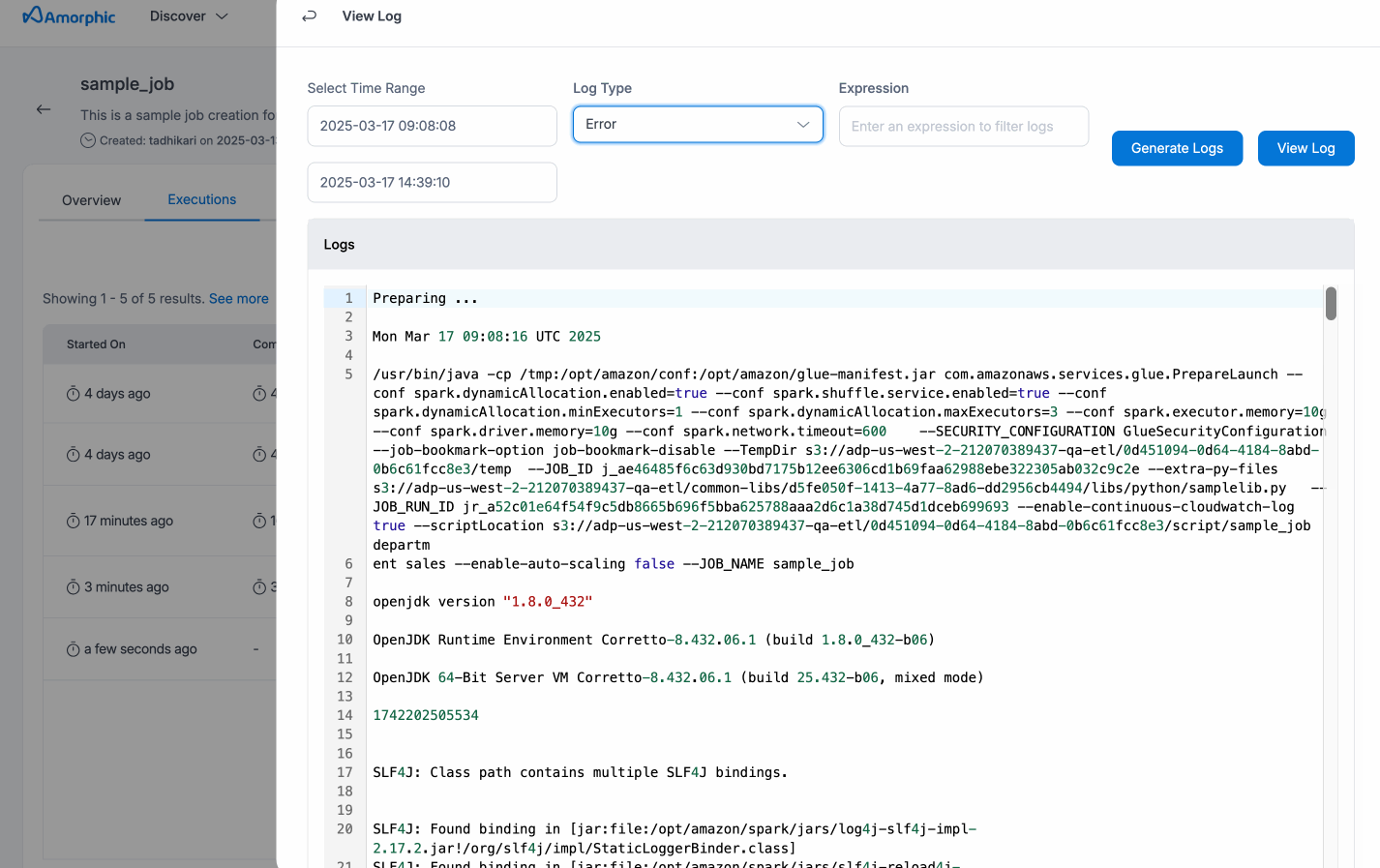
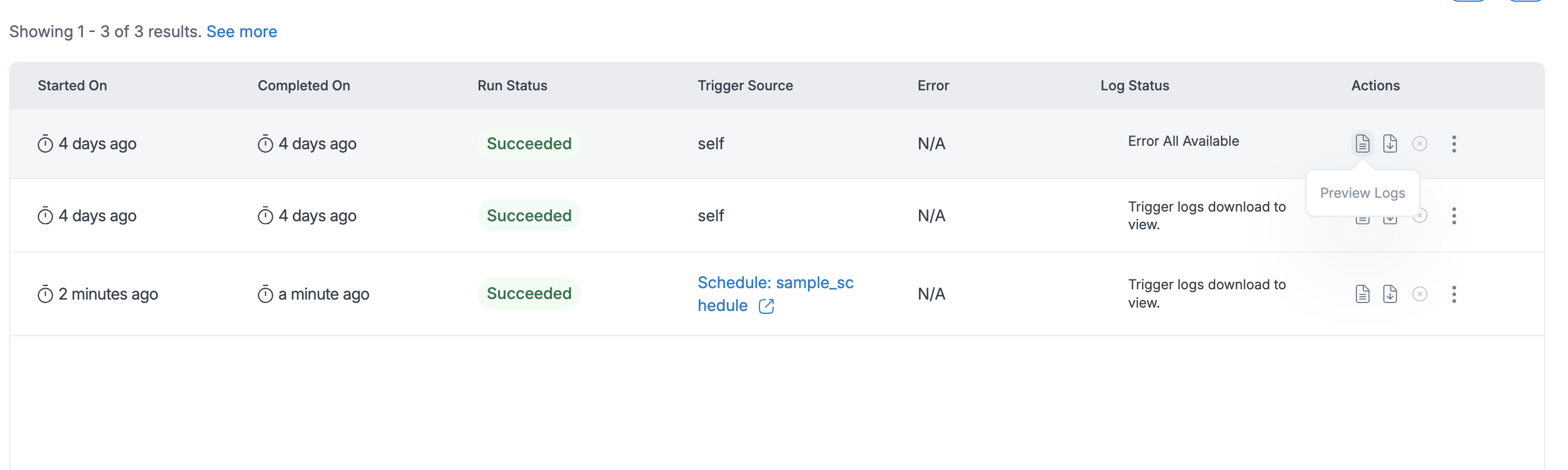
Preview Logs - While a job is running, users can monitor real-time progress using the Preview Logs feature. By clicking on the View Logs option, users can immediately view the most recent output logs. If the job is still in progress, the preview will show logs from the last 2 hours, helping users stay informed of current job activity. Once the job is completed, the last 2 hours of logs will also be displayed by default. For more control, users can specify a custom timestamp to view logs from a specific period during the job's execution.
Additionally, they can toggle between Error Logs and Output Logs, depending on whether they want to see error details or execution outputs. After reviewing the logs, users can also download them based on the selected timestamp for more detailed inspection or offline review.
For any log generation or downloading operations,(regardless of job access level) user can perform the action; provided access to all attached resources to the job is present.
Job Bookmarks
Bookmarks helps track data of a particular job run. For more info on job bookmarks, please refer documentation.
Refer this documentation to understand the core concepts of job bookmarks in AWS Glue and how to process incremental data.
Choose from the below three bookmarks:
Enable - Keeps track of processed data by updating the bookmark state after each successful run. Any further job runs on the same data source, since the last checkpoint, only processes newly added data.
Disable - The default setting for most jobs.It means that the job will process the entire dataset each time it is run, regardless of whether the data has been processed before.
Pause - It allows the job to process incremental data, since the last successful run, without updating the state of the job bookmark. The job bookmark state is not updated and the last enabled job run state will be used to process the incremental data.
- For job bookmarks to work properly, enable the job bookmark option in Create/Edit job and also set the "transformation_ctx" parameter within the script.
- For PythonShell jobs, bookmarks are not supported.
Below is the sample job snippet to set the "transformation_ctx" parameter:
InputDir = "s3://<DLZ_BUCKET>/<DOMAIN>/<DATASET_NAME>/"
spark_df = glueContext.create_dynamic_frame_from_options(connection_type="s3",connection_options = {"paths": [InputDir],"recurse" : True},format="csv",format_options={"withHeader": True,"separator": ",","quoteChar": '"',"escaper": '"'}, "transformation_ctx" = "spark_df")
Access Control
ETL jobs also have a resource level access control on top on them. To access certain functionality access to all attached resource should be independently present.
The details for the levels of access control can be viewed in the visual below:
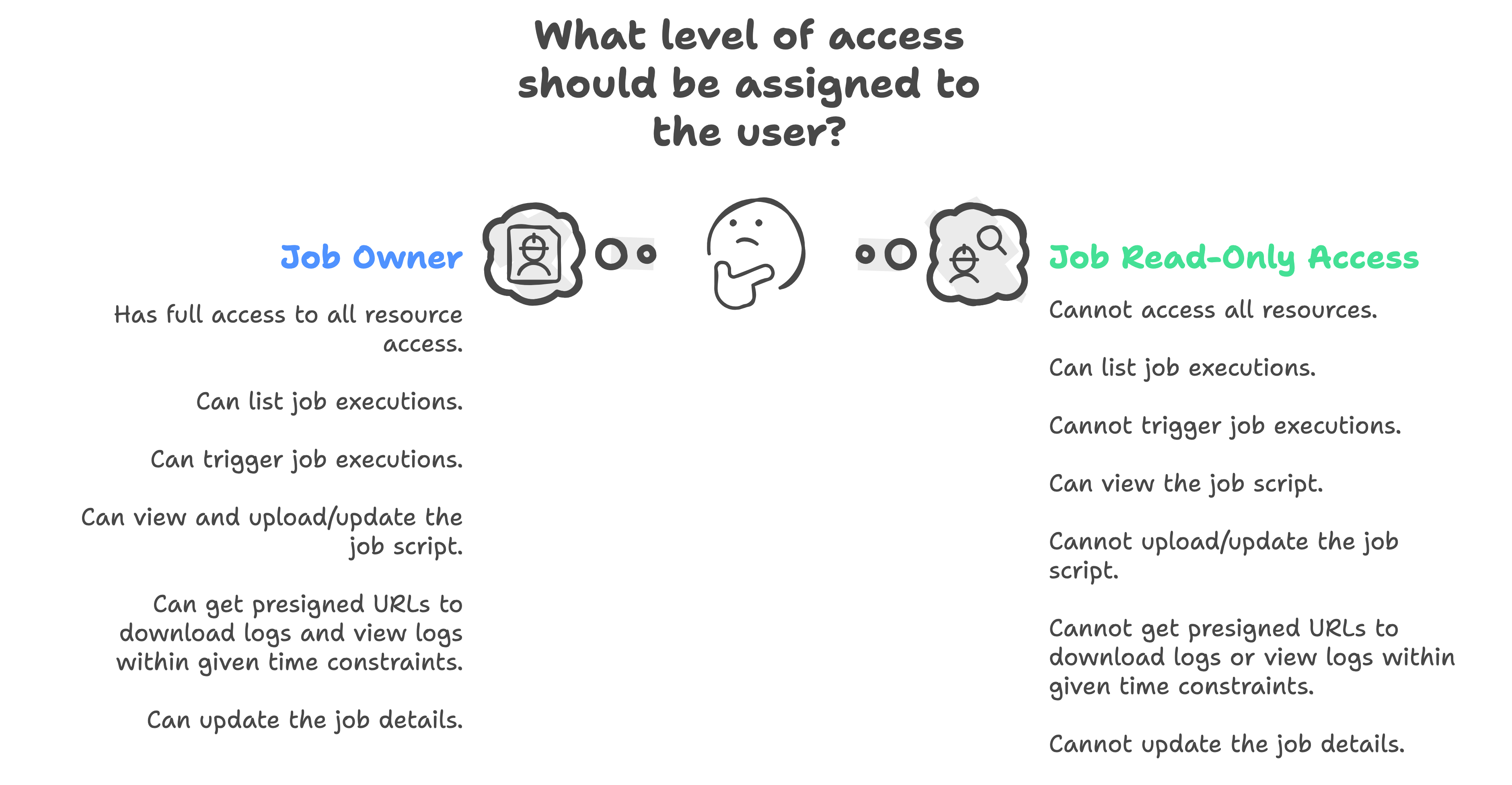
Query View in Jobs
Using boto3 S3-Athena client: User can use below script to query view in jobs. Here, in Amorphic context, the database_name refers to the domain and the view_name refers to the dataset(of type view). The output of the query will be stored in the specified S3 bucket path.
User is allowed to query Amorphic datasets of type view from jobs using athena not internal/external type of datasets as they are expected to be queried via spark/pandas dataframes.
import sys
from pyspark.context import SparkContext
from awsglue.context import GlueContext
from awsglue.utils import getResolvedOptions
import boto3
# Initialize GlueContext and SparkContext
args = getResolvedOptions(sys.argv, ['JOB_NAME'])
sc = SparkContext()
glueContext = GlueContext(sc)
spark = glueContext.spark_session
# Athena query execution
athena_client = boto3.client('athena')
athena_bucket_name = "" # name of the athena bucket in the environment
resourceid = "" # Id of the Amorphic view to query
database_name = "" # Domain name under which the view lies
view_name = "" # Name of the view to query
# Athena query details
query = f"SELECT * FROM {database_name}.{view_name} LIMIT 10;"
database = database_name
output_s3_path = f"s3://{athena_bucket_name}/glue-etl/{resourceid}"
# Start Athena query execution
response = athena_client.start_query_execution(
QueryString=query,
QueryExecutionContext={'Database': database},
ResultConfiguration={'OutputLocation': output_s3_path}
)
# Get query execution ID
query_execution_id = response['QueryExecutionId']
# Wait for the query to complete
query_status = athena_client.get_query_execution(QueryExecutionId=query_execution_id)
state = query_status['QueryExecution']['Status']['State']
# Wait for query to complete
while state in ['QUEUED', 'RUNNING']:
query_status = athena_client.get_query_execution(QueryExecutionId=query_execution_id)
state = query_status['QueryExecution']['Status']['State']
# If the query succeeded, read the result from the S3 output location
if state == 'SUCCEEDED':
# Fetch the result file path
result_file_path = f"{output_s3_path}{query_execution_id}.csv"
# Read the result into a Spark DataFrame and show it
athena_df = spark.read.csv(result_file_path, header=True)
athena_df.show()
elif state == 'FAILED':
print(f"Athena query failed with state: {state} and response: {query_status}")
else:
continue
Job Metrics and Summaries
Starting from Amorphic version 3.1, a custom logging functionality will be available for all ETL jobs; namely ETL Logger.
This logger can be used in job script to publish custom logger which would be compiled to job executions and presented out to user to get a summarized glance on there operations. User will have complete freedom to provide their own custom metrics to be published and compiled for job executions.
How to use:
from etlLogger import CustomLogger
logger = CustomLogger(logger_name = "", log_level = "")
logger.info("This would be a simple logger with a metric here" , metrics = {"Test metric key here": "Metric value here"})
The metrices can be previewed from the job executions panel as previewed below:
- The metrices take some time to be compiled and won't be available instantly in the panel.
- Additionally these job summaries can be viewed via dashboards as well as shown below:
Use Case: Connecting to customer system/database from a glue job
Customer has a glue job that needs to connect to a system/database that has a firewall placed in front of it.
In order to establish the connection, the public IP of the source needs to be whitelisted. The public IP required here will be the NATGateway ElasticIP.