
External API Datasource
From version 2.2, encryption(in-flight, at-rest) for all jobs and catalog is enabled. All the existing jobs(User created, and also system created) were updated with encryption related settings, and all the newly created jobs will have encryption enabled automatically.
External API datasources are used to import data from REST APIs to Amorphic datasets. These datasources support various authentication mechanisms and HTTP methods to connect with external APIs and ingest data into your Amorphic Datasets.
Currently supported authentication types:
- NoAuth - No authentication required
- BasicAuth - Username and password authentication
- OAuth1 - OAuth 1.0 authentication with consumer key/secret and access token/secret
- OAuth2 - OAuth 2.0 authentication with client credentials grant type
- BearerToken - Token-based authentication
- ApiKey - API key authentication (can be added to header or query parameters)
Supported HTTP methods: GET, POST
Supported pagination types: Page, Offset, Cursor
How to create an External API Datasource?
To create a External API datasource, input the below details shown in the table or you can directly upload the JSON data.
Metadata
| Name | Description |
|---|---|
| Datasource Name | Give the datasource a unique name |
| Description | Add datasource description |
| Keywords | Add keyword tags to connect it with other Amorphic components. |
| Datasource Type | Type of datasource. In this case it is ExternalAPI |
Datasource Configuration
| Configuration | Description |
|---|---|
| Version | Enables the user to select what version of ingestion scripts to use (Amorphic specific). For any new feature/Glue version that gets added to the underlying ingestion script, new version will be added to the Amorphic. |
| Request URL | The REST API endpoint URL from which data needs to be extracted. Must be a valid HTTP/HTTPS URL. |
| Request Method | HTTP method to use for the API request. Supported methods: GET, POST |
| Request Headers | Additional HTTP headers to include in the request (JSON format). Optional field. |
| Request Query Parameters | Query string parameters for the API request (JSON format). Optional field. |
| Request Body | Request body for POST requests (JSON format). Optional field. |
| Authentication Type | Choose the authentication type: NoAuth, BasicAuth, OAuth1, OAuth2, BearerToken, ApiKey |
| Authentication Configuration | Configuration specific to the selected authentication type (see details below) |
| Pagination Type | Type of pagination to use: Page, Offset, Cursor. Optional field. |
| Pagination Configuration | Configuration specific to the selected pagination type (see details below) |
Authentication Configuration
Based on the selected AuthType, the following configurations are required in AuthConfig:
NoAuth
No additional configuration required.
BasicAuth
| Field | Description |
|---|---|
| Username | Username for basic authentication |
| Password | Password for basic authentication |
OAuth1
| Field | Description |
|---|---|
| ConsumerKey | OAuth 1.0 consumer key |
| ConsumerSecret | OAuth 1.0 consumer secret |
| AccessToken | OAuth 1.0 access token |
| TokenSecret | OAuth 1.0 token secret |
OAuth2
| Field | Description |
|---|---|
| GrantType | OAuth 2.0 grant type (currently supports "ClientCredentials") |
| TokenUrl | URL to obtain the OAuth 2.0 token |
| ClientId | OAuth 2.0 client ID |
| ClientSecret | OAuth 2.0 client secret |
| Scope | OAuth 2.0 scope (optional, space-separated values) |
BearerToken
| Field | Description |
|---|---|
| Token | Bearer token for authentication |
ApiKey
| Field | Description |
|---|---|
| KeyName | Name of the API key parameter/header |
| KeyValue | Value of the API key |
| AddTo | Where to add the API key: "Header" or "Query" |
Pagination Configuration
Based on the selected PaginationType, the following configurations are required in PaginationConfig:
Page
| Field | Description |
|---|---|
| DataKey | JSON path to the data array in the response |
| PageParam | Parameter name for the page number |
| SizeParam | Parameter name for the page size |
| SizeValue | Number of records per page |
Offset
| Field | Description |
|---|---|
| DataKey | JSON path to the data array in the response |
| LimitParam | Parameter name for the limit |
| OffsetParam | Parameter name for the offset |
| LimitValue | Number of records per request |
Cursor
| Field | Description |
|---|---|
| DataKey | JSON path to the data array in the response |
| CursorParam | Parameter name for the cursor |
| CursorPathInResponse | JSON path to the next cursor value in the response |
Ingestion Timeout Configuration (API Only)
You can configure the ingestion process timeout during datasource creation by adding the IngestionTimeout key to the DatasourceConfig payload.
- Value range: 1 to 2880 minutes
- Default value: 480 minutes (8 hours) if not specified
POST - /datasources
{
"DatasourceName": "ExternalAPI-NoAuth",
"DatasourceType": "ext-api",
"Description": "External API datasource with no authentication",
"Keywords": [
"Owner: Mark Liu"
],
"DatasourceConfig": {
"RequestUrl": "https://api.example.com/v1/data",
"RequestMethod": "GET",
"AuthType": "NoAuth",
"IngestionTimeout": 720
}
}
The IngestionTimeout value set in the datasource can be overridden during schedule creation or schedule run by providing a MaxTimeOut argument.
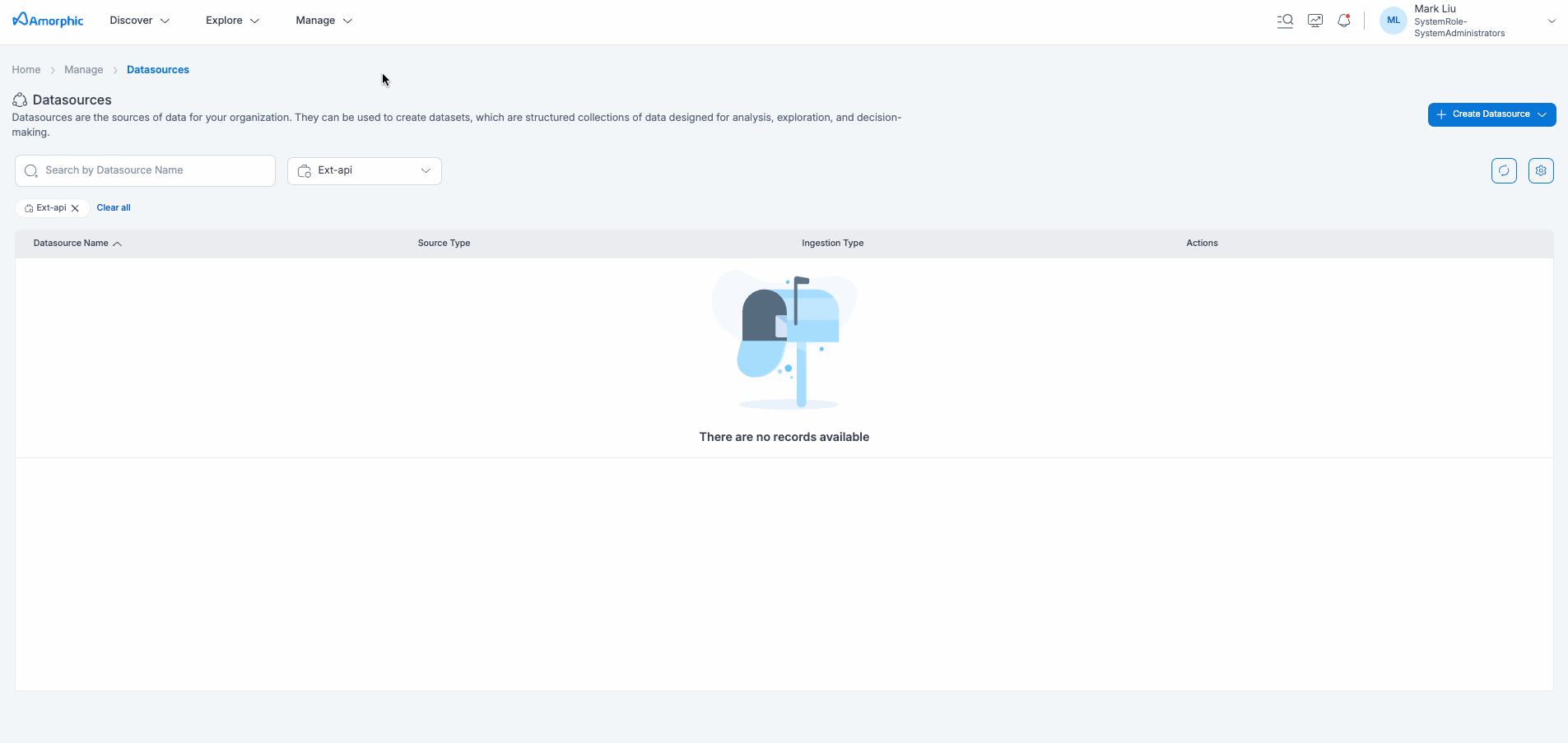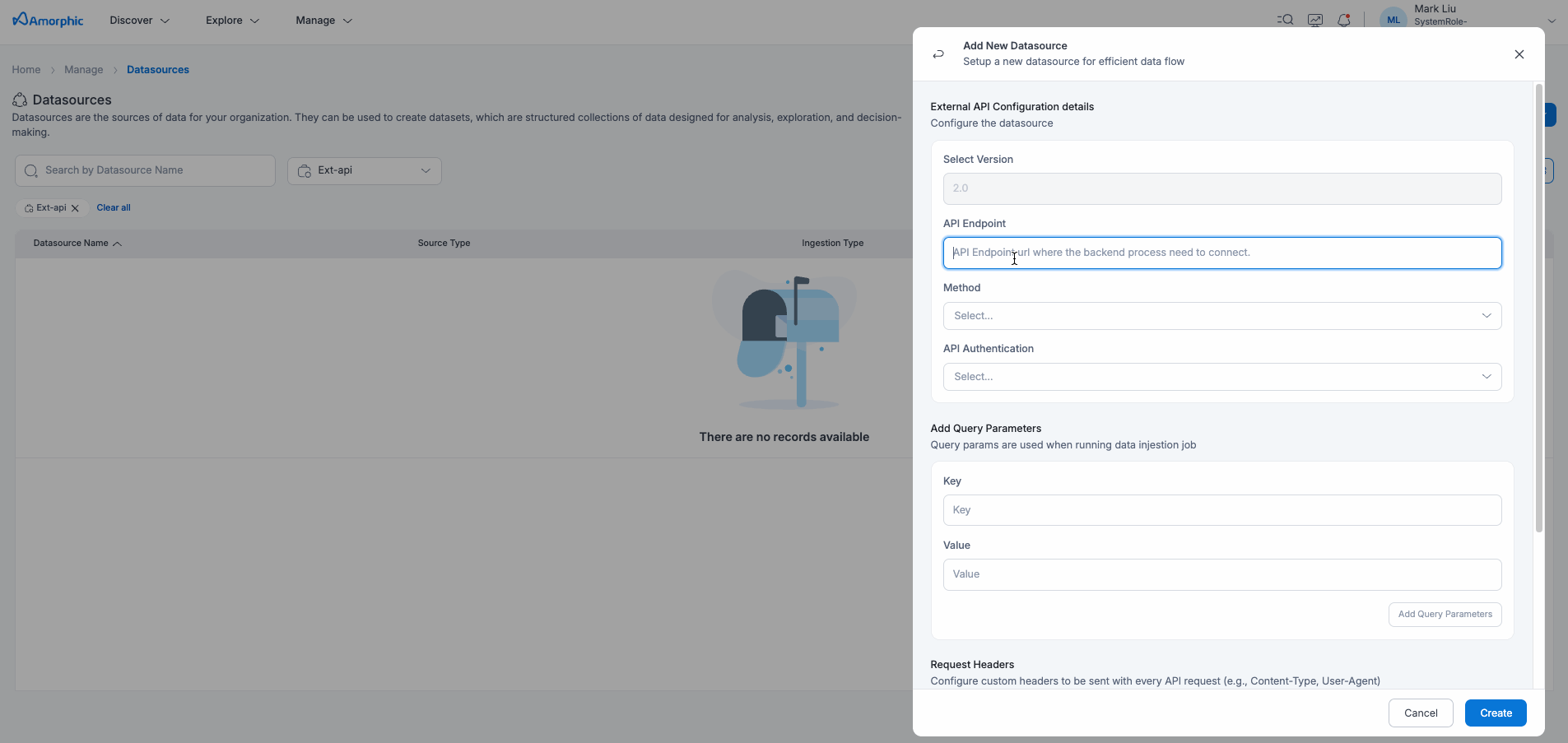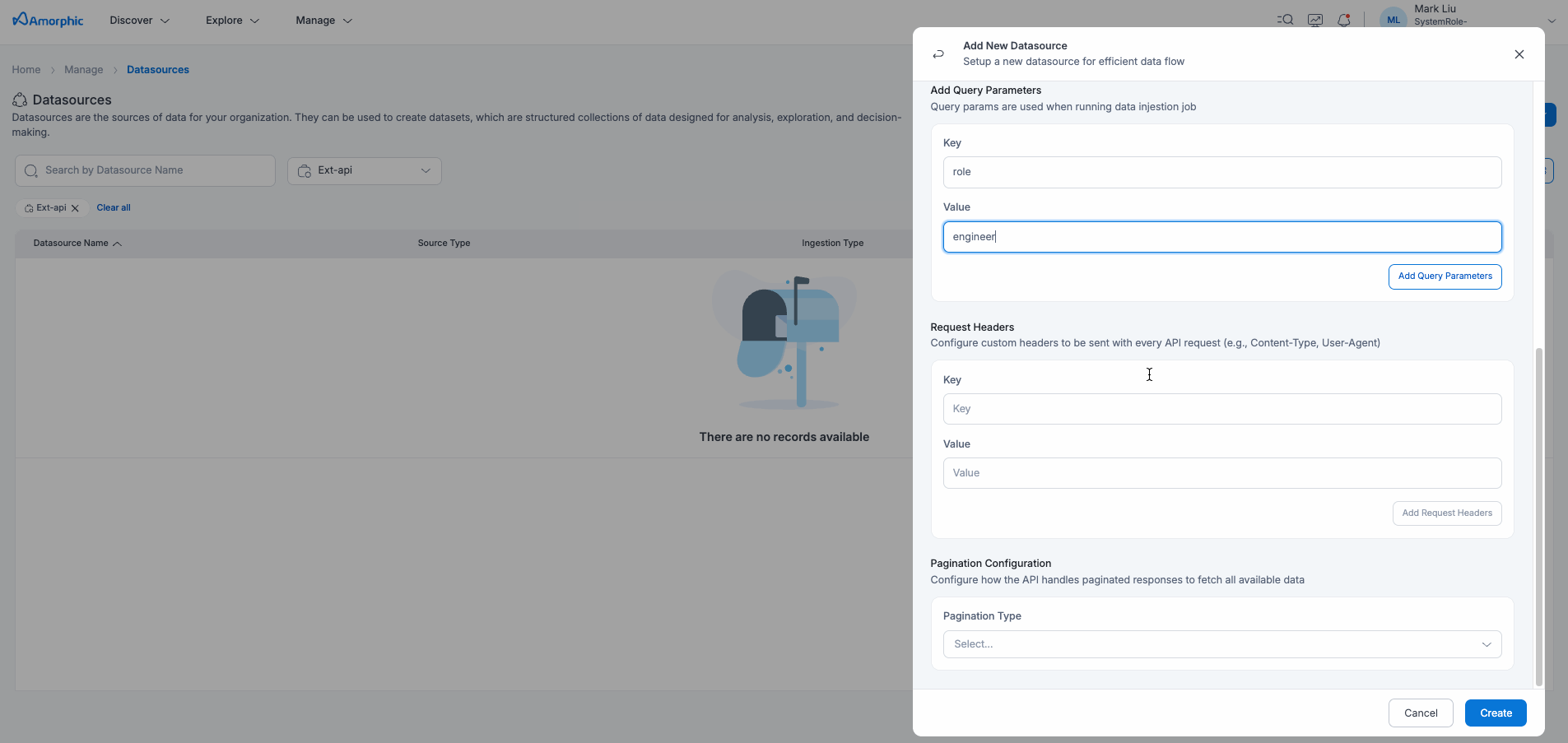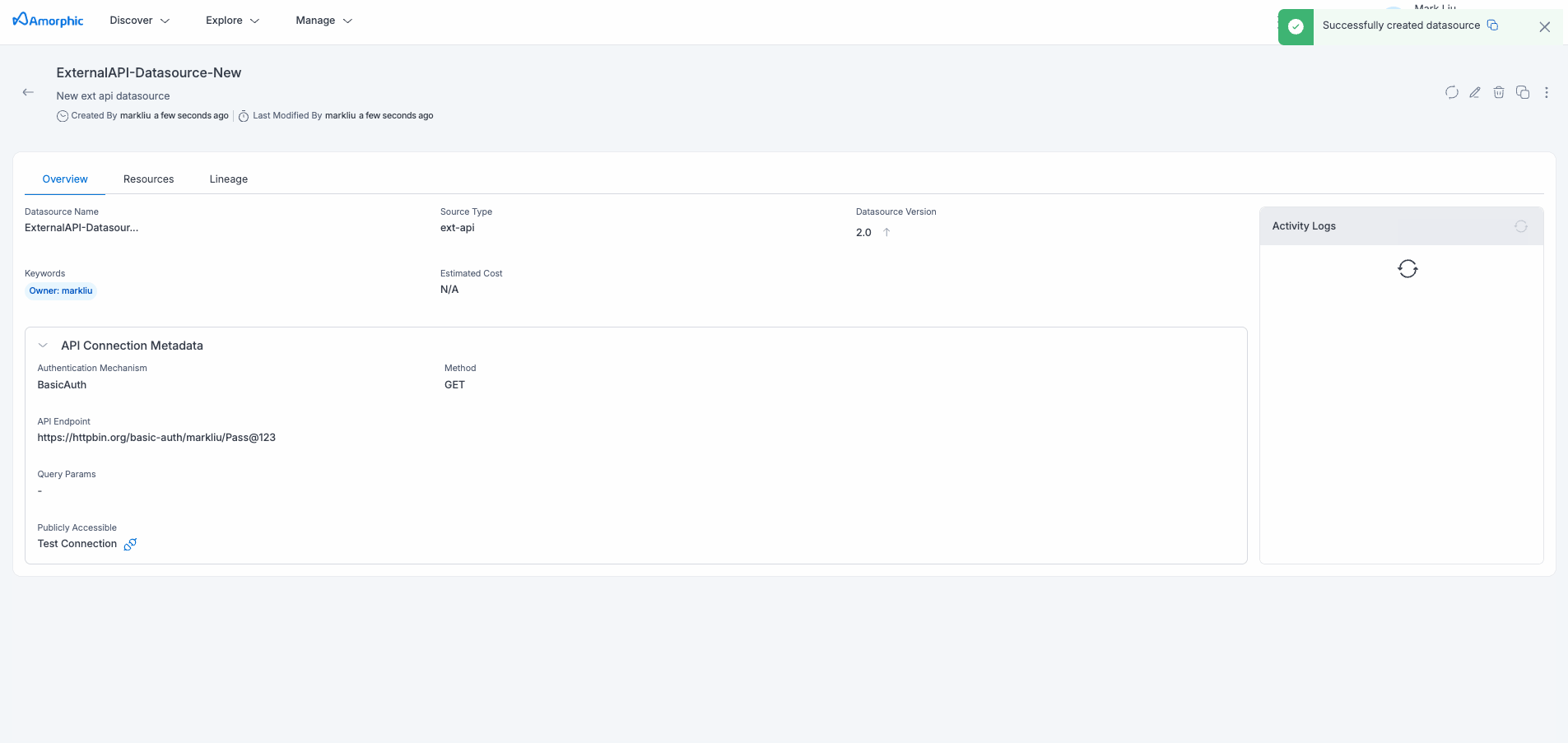
External API Datasource Details
The External API Datasource details page provides comprehensive information about your configured API connection, including authentication settings, request configuration, and connection status. This centralized view enables efficient monitoring and management of your external API integrations.
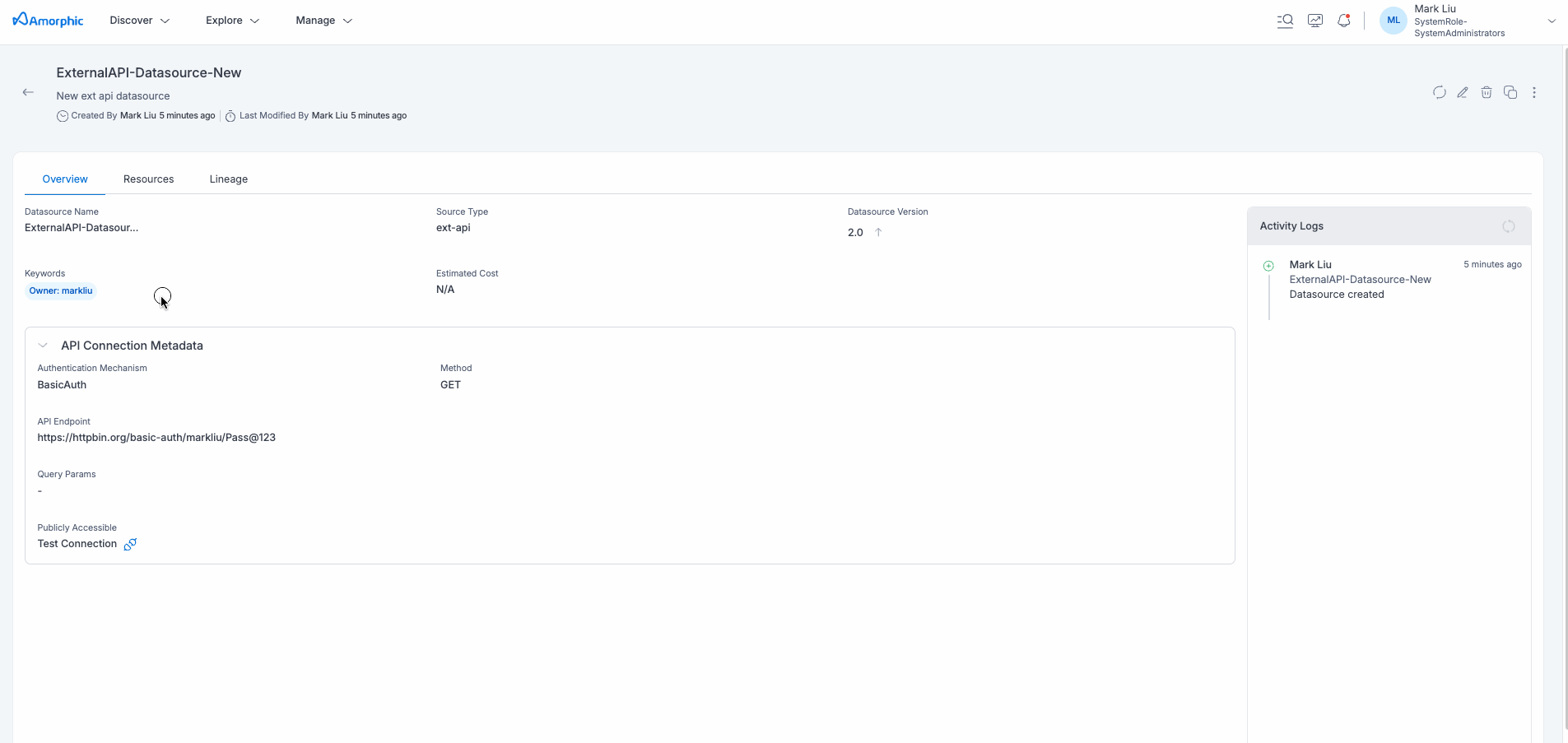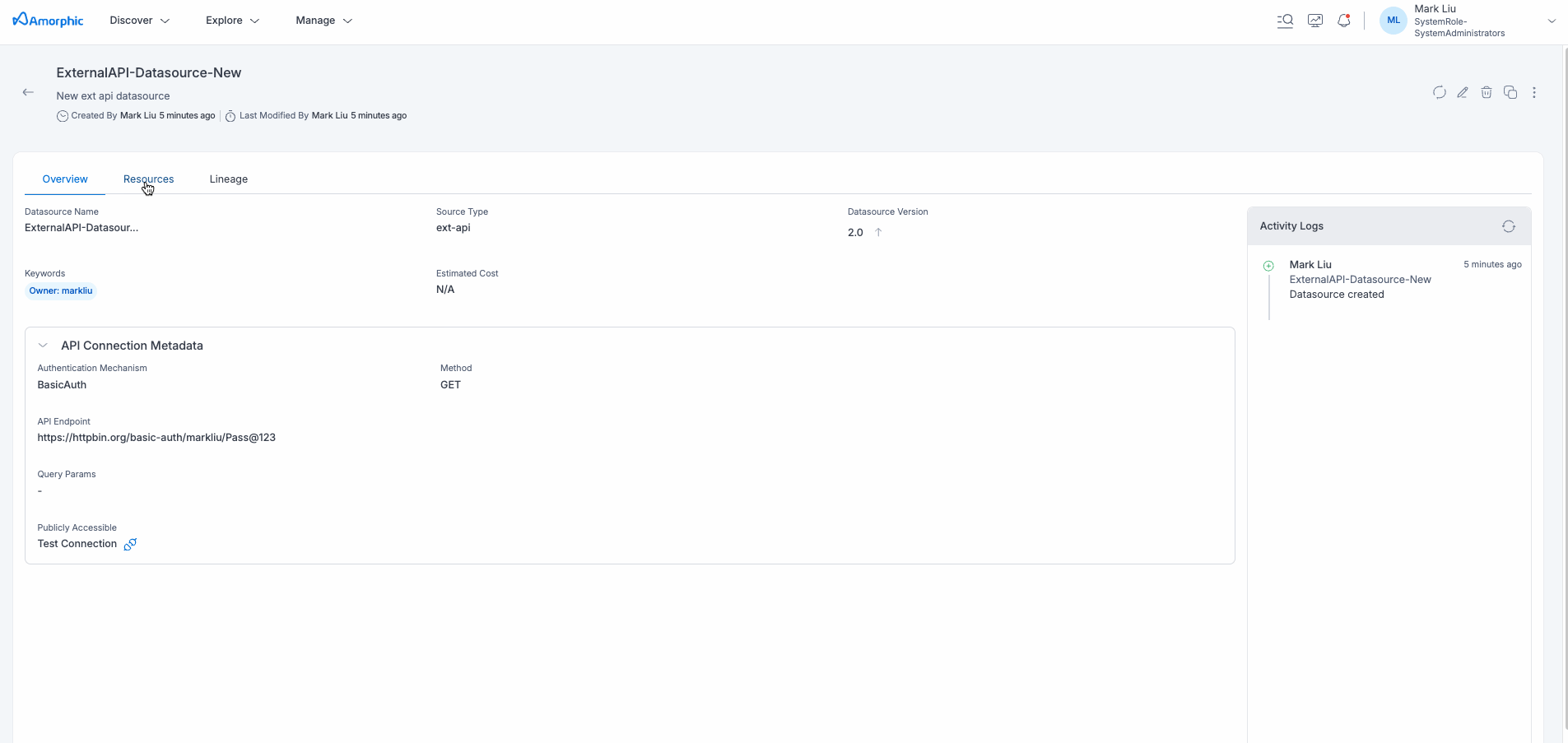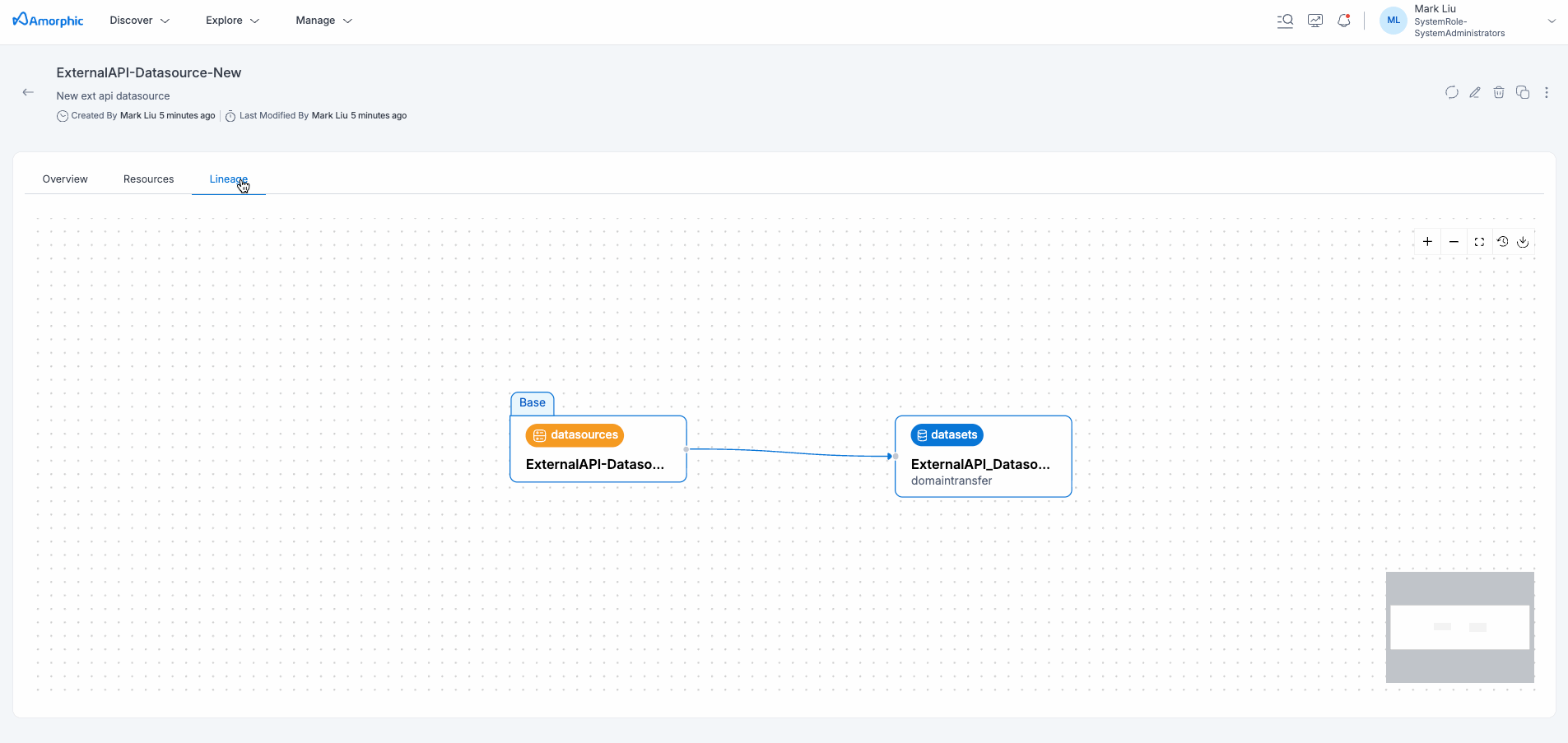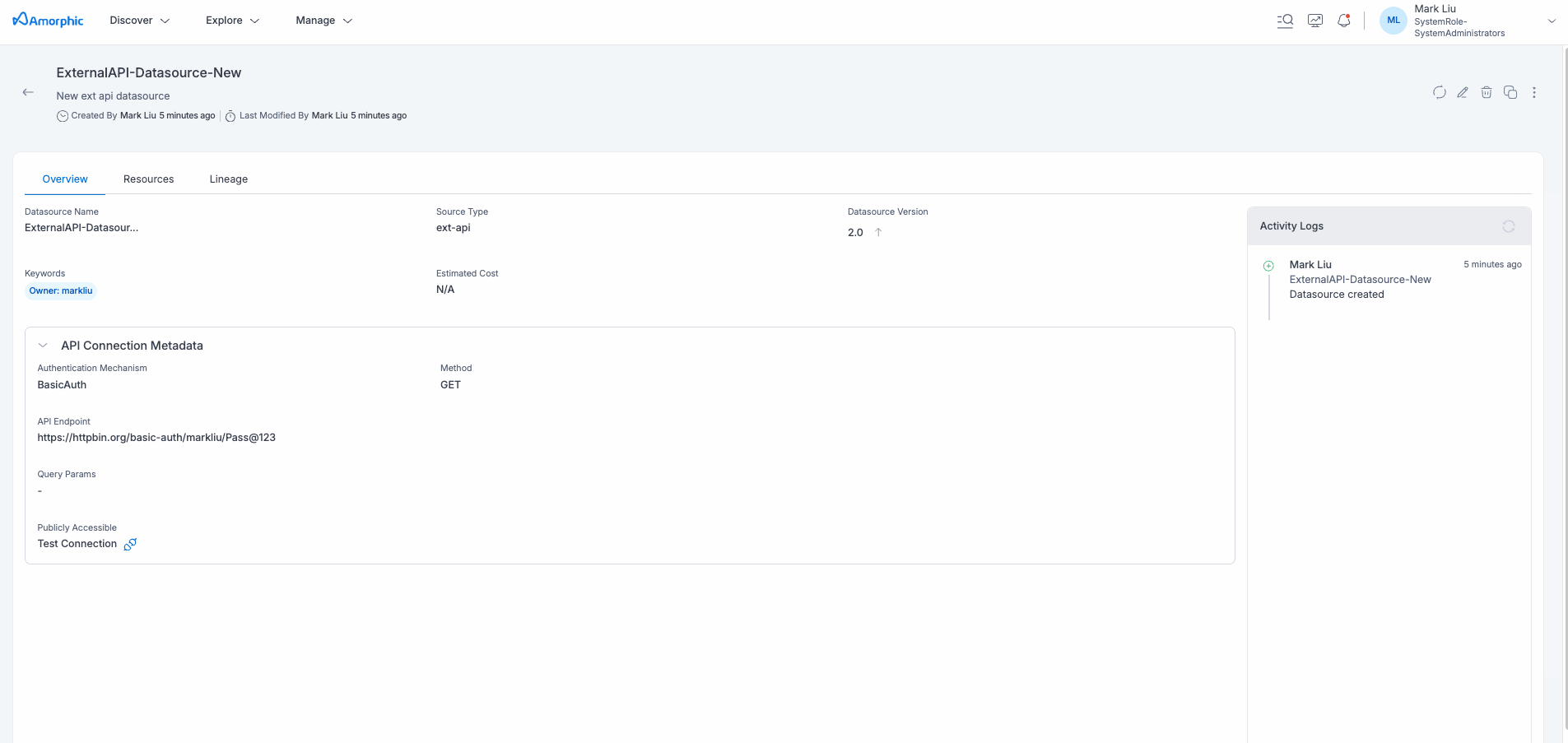
Test Datasource
This functionality allows users to quickly verify the connectivity to the specified API endpoint. By initiating this test, users can confirm if the API configuration is accurate and functional, ensuring seamless access to the external API.
Edit Datasource
External API Datasources can be modified after creation to accommodate changing requirements or update configuration settings. The edit functionality provides flexibility to adjust various aspects of your API datasource without needing to recreate the entire datasource.
To edit an External API Datasource, locate and click the edit button in the upper right corner of the datasource details page. This will open the configuration interface where you can modify supported fields and settings.
Changes to critical configuration like API endpoint URL may require creating a new datasource.
Upgrade Datasource
Users have the option to upgrade a datasource if a new version is available. The upgrade option will be displayed in the available options when a newer version is released. The upgrade option is visible only when a new version is available; otherwise, it won't be shown.
Datasource upgrade upgrades the underlying Glue version and the data ingestion script with new features, performance improvements, and bug fixes.
Downgrade Datasource
Users have the capability to downgrade a datasource to a previous version if they believe the upgrade isn't meeting their requirements. It's important to note that a datasource can only be downgraded if it has previously been upgraded. For datasources that have been newly created, the option to downgrade is not available. If a datasource is compatible with downgrading, you will find the downgrade option.
Delete Datasource
To delete an External API Datasource, locate the delete button (trash can icon) in the upper right corner of the datasource details page and click on it. This action will permanently remove the datasource from your Amorphic environment.
Deleting a datasource is irreversible. Ensure that no active schedules or jobs are dependent on this datasource before proceeding with deletion.
Runtime Query Parameters Support
External API datasources support query parameters to customize API requests. Query parameters can be configured at the schedule level and support both static values and dynamic date placeholders for time-based queries.
Date Placeholder Support
Users can pass date placeholders within the QueryParameters for dynamic date-based queries. This requires a parameter called DATE_FORMAT within QueryParameters to specify the date format.
Example: Consider a financial API that supports querying by transaction date and you want to automatically fetch the previous day's transactions every time the schedule runs.
Configure the following Query Parameters on the External API Datasource:
| Parameter | Value |
|---|---|
| DATE_FORMAT | %Y-%m-%d |
| transaction_date | %%CURRENT_DATE-1D |
Valid Date Placeholders
The date placeholders should be in the format %%CURRENT_DATE - Number Of Days/Hours/Minutes. Valid placeholder examples:
"%%CURRENT_DATE"- Current date"%%CURRENT_DATE-1D"- 1 day before current date"%%CURRENT_DATE-10H"- 10 hours before current time"%%CURRENT_DATE-5M"- 5 minutes before current time
This feature enables flexible scheduling of API data ingestion with dynamic query parameters, making it easier to handle time-based data retrieval scenarios.
Runtime Query Parameter Override
External API datasources support runtime override of query parameters through schedule arguments. This allows users to dynamically modify query parameters without editing the datasource configuration.
Query parameters should be provided as a single schedule argument called QueryParameters whose value is a dictionary with the required parameters. For example:
| Schedule Argument Name | Schedule Argument Value |
|---|---|
| QueryParameters | {"limit": "5", "offset": "1"} |
Example with date placeholders:
{
"DATE_FORMAT": "%Y-%m-%d",
"start_date": "%%CURRENT_DATE-2D",
"end_date": "%%CURRENT_DATE-1D"
}
Query Parameter Priority Order
When query parameters are defined at multiple levels, Amorphic uses the following priority order (highest to lowest):
- Runtime Parameters - QueryParameters argument passed during manual schedule execution (overrides everything)
- Schedule Arguments - QueryParameters argument defined in the schedule configuration (overrides datasource settings)
- Datasource Configuration - Query Parameters configured on the External API Datasource
Datasource Versions
1.1
In this version of External API datasources, we added auto-reload feature for datasets of type reload.
From this version onwards, data reloads process will trigger automatically as soon as the file upload finishes through the external api datasources. So that users don't need to manually trigger reload process after completion of file upload when ingesting data through external api ingestion datasource.
1.2
In this version we made code changes in the underlying Glue script for the support of dataset custom partitioning.
From this version onwards, the data will be loaded into S3 LZ with the prefix containing the partition key (if you specified any) for the targets which support dataset partitioning.
For example, for the partition keys KeyA, KeyB with the values ValueA, ValueB respectively, the S3 prefix will be in the format:
Domain/DatasetName/KeyA=ValueA/KeyB=ValueB/upload_date=Unix_Timestamp/UserName/FileType/.
To understand more about custom data partitioning, read the docs about dataset custom partitioning here.
1.3
In this version of external API datasource, we added support for the Skip LZ feature.
This feature enables users to directly upload data to the data lake zone by skipping the data validation. Please refer to Skip LZ related docs for more details.
1.4
No major changes were made to the underlying Glue script or design, but the logging has been enhanced for better debugging and monitoring capabilities.
1.5
The update in this version is specifically to ensure FIPS compliance, with no functional changes made to the script.
1.6
This version brings full support for Amorphic 3.0 along with an upgrade to the latest Python Glue job version.
2.0
This major version introduces comprehensive enhancements to External API datasource capabilities, providing extensive flexibility and control over API integrations.
Key features introduced in this version:
- Multiple Authentication Types: Added support for NoAuth, BasicAuth, OAuth1, OAuth2, BearerToken, and ApiKey authentication mechanisms, allowing seamless integration with various API security models
- Advanced Pagination Support: Implemented Page, Offset, and Cursor pagination types to handle large datasets efficiently and accommodate different API pagination patterns
- Request Body Configuration: Introduced support for custom request bodies, enabling POST operation with structured JSON payloads for complex API interactions
- Custom Headers Management: Added the ability to configure custom HTTP headers, providing full control over request formatting and API-specific requirements
- Enhanced Request Configuration: Improved overall request handling with better parameter management and configuration options