
Dataset custom partitioning
Dataset partitioning enables the user to ingest the data into custom partitions as they like which further helps in better reading the data and the query performance. In phase-1(v1.11) only S3Athena & LakeFormation are supported targets for the custom partitioning.
While uploading the data(from API), user must specify which partition the data needs to loaded to. Dynamic writes can still be done via ELT jobs on these datasets. As a pre-requisite dataset must be created with partitions to support this feature.
How to create datasets with partitions
Dataset registration can be done either via API or UI. API registration can be done through PostMan or from command line by specifying the dataset and partition schema's. Below is the API and it corresponding method on how to create dataset with partitions followed by an example. As dataset registration is a two-step process one can still perform part-1(Creating metadata) from UI and complete the registration using API.
API → /datasets/datasetid & PUT method
{
"DatasetSchema": [{"name": <string>, "type":<string> }, {"name": <string>, "type":<string> }, ....],
"PartitionKeys": [
{
"name": <string> (Name of partition column)
"type": <string> (Datatype of the partition column)
"rank": <int> (Rank/Position of this partition)
}
]
}
Example API call for the above
{"DatasetSchema":[{"name":"Region","type":"varchar(200)"},{"name":"Country","type":"varchar(200)"},{"name":"Item_Type","type":"varchar(200)"},{"name":"Sales_Channel","type":"varchar(200)"},{"name":"Order_Priority","type":"varchar(200)"},{"name":"Order_Date","type":"varchar(200)"},{"name":"Order_ID","type":"bigint"},{"name":"Ship_Date","type":"varchar(200)"},{"name":"Units_Sold","type":"bigint"},{"name":"Unit_Price","type":"double precision"}],
"PartitionKeys": [
{
"name": "partition_one",
"type": "varchar(200)",
"rank": 1
},
{
"name": "partition_two",
"type": "bigint",
"rank": 2
}]}
File upload via API
User must specify which partition the data needs to send to while uploading the file via API. Apart from FileName & DatasetId in the API, partition columns and their corresponding values must be specified. No change for the data loads that doesn't have partition columns.
API → /datasets/file & POST method
{
"FileName": <string>,
"DatasetId": <string>,
"PartitionKeys": {
<string>: <value>,
<string>: <value>,
}
}
Example API call for the above
{
"FileName": "Sales_Records.csv",
"DatasetId": "66b2dae9-b488-4375-9fee-a52859e56fdb",
"PartitionKeys": {
"partition_one": "sales_data",
"partition_two": 20211130105089
}
}
Adding partitions using UI
Partitions can be added to a dataset in the complete registration page, user must provide partition name, rank and the datatype of the partition, this can be done using custom partition options in the UI.
Below image shows how to add partitions to a dataset.
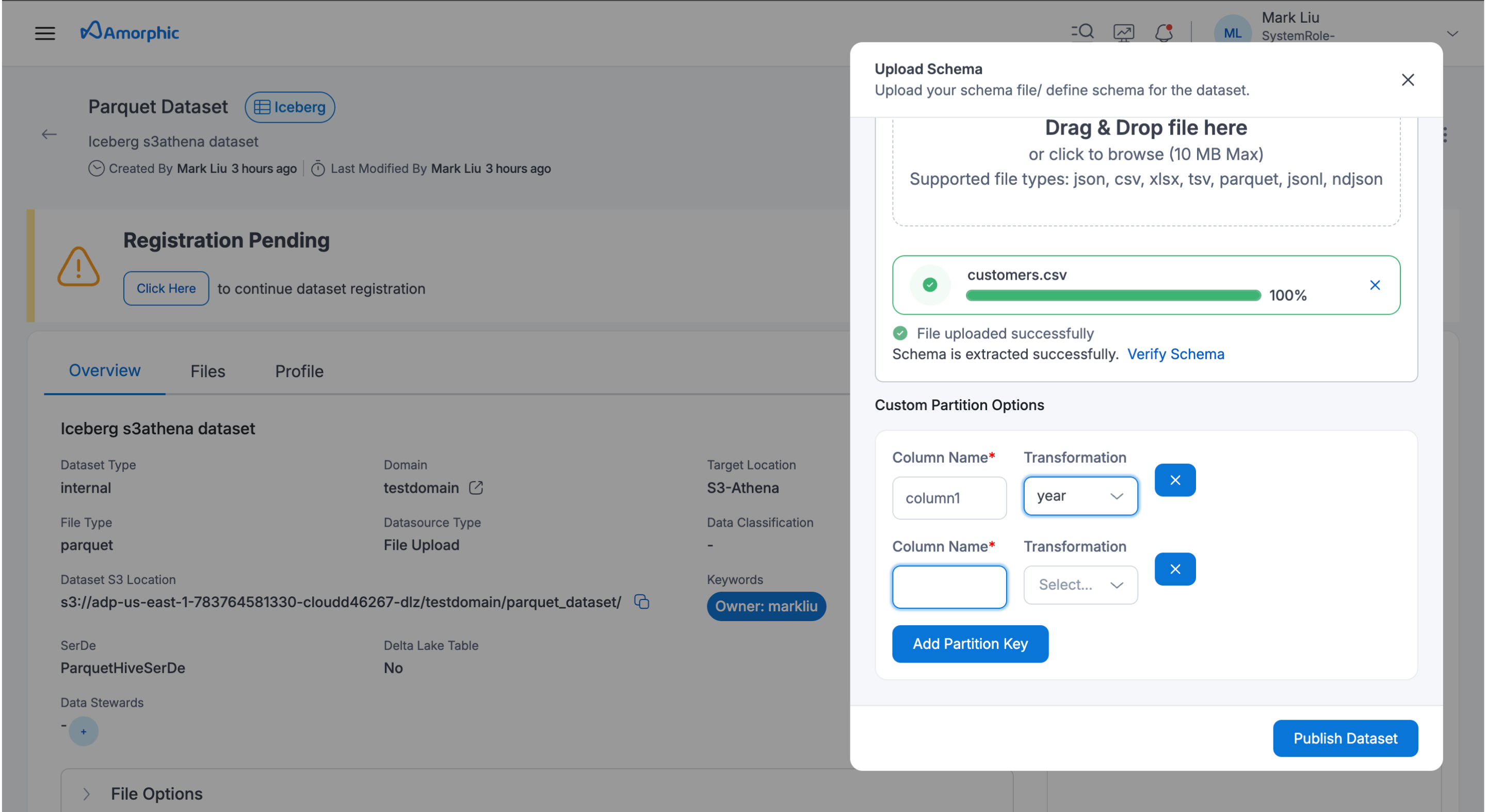
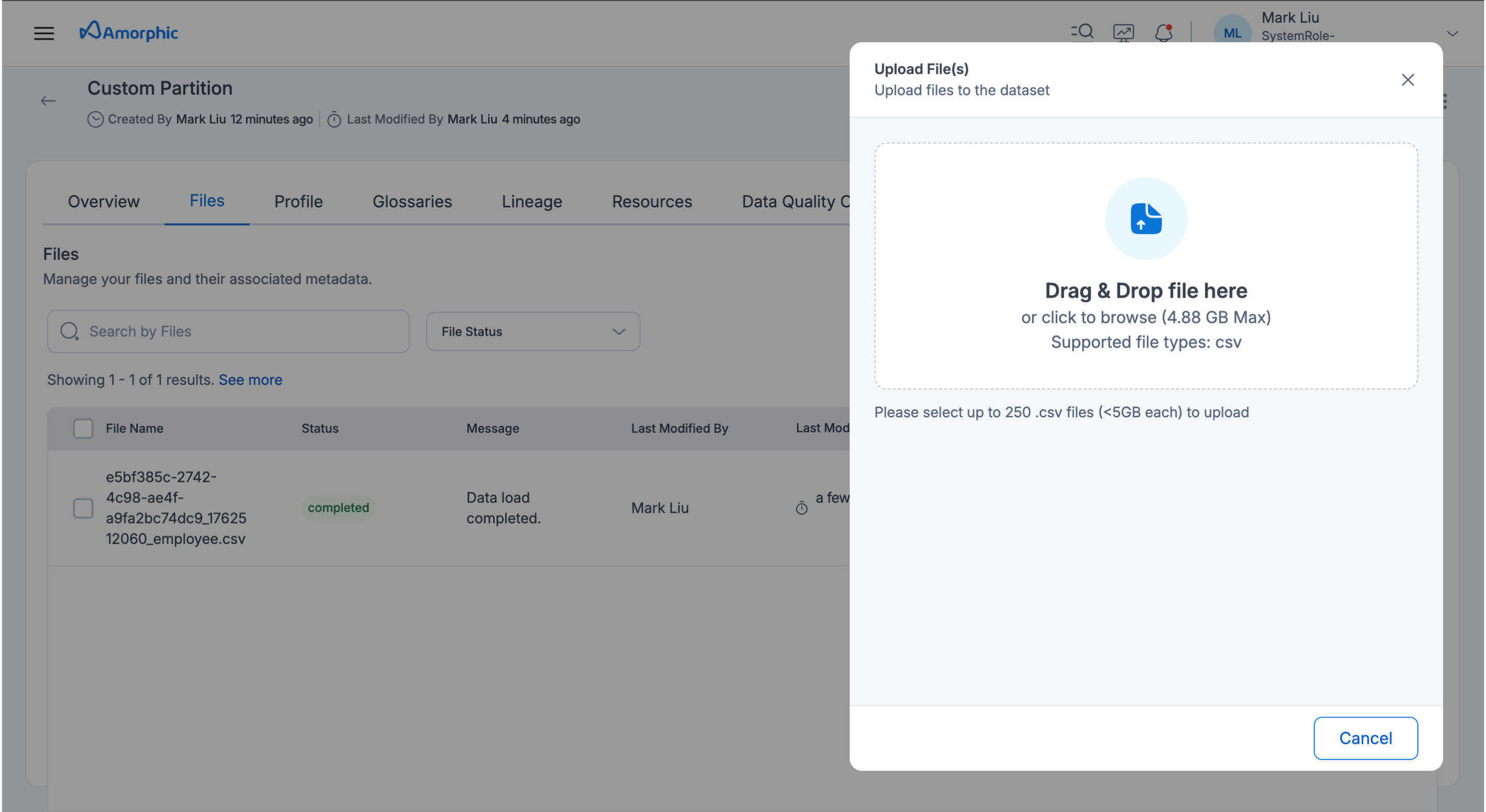
File upload using UI
Upon successful creation of dataset and during file upload, partition values must be specified so that the data will be loaded into that partition and can be used further for querying purposes.
Here is an example of uploading a file to a partition.
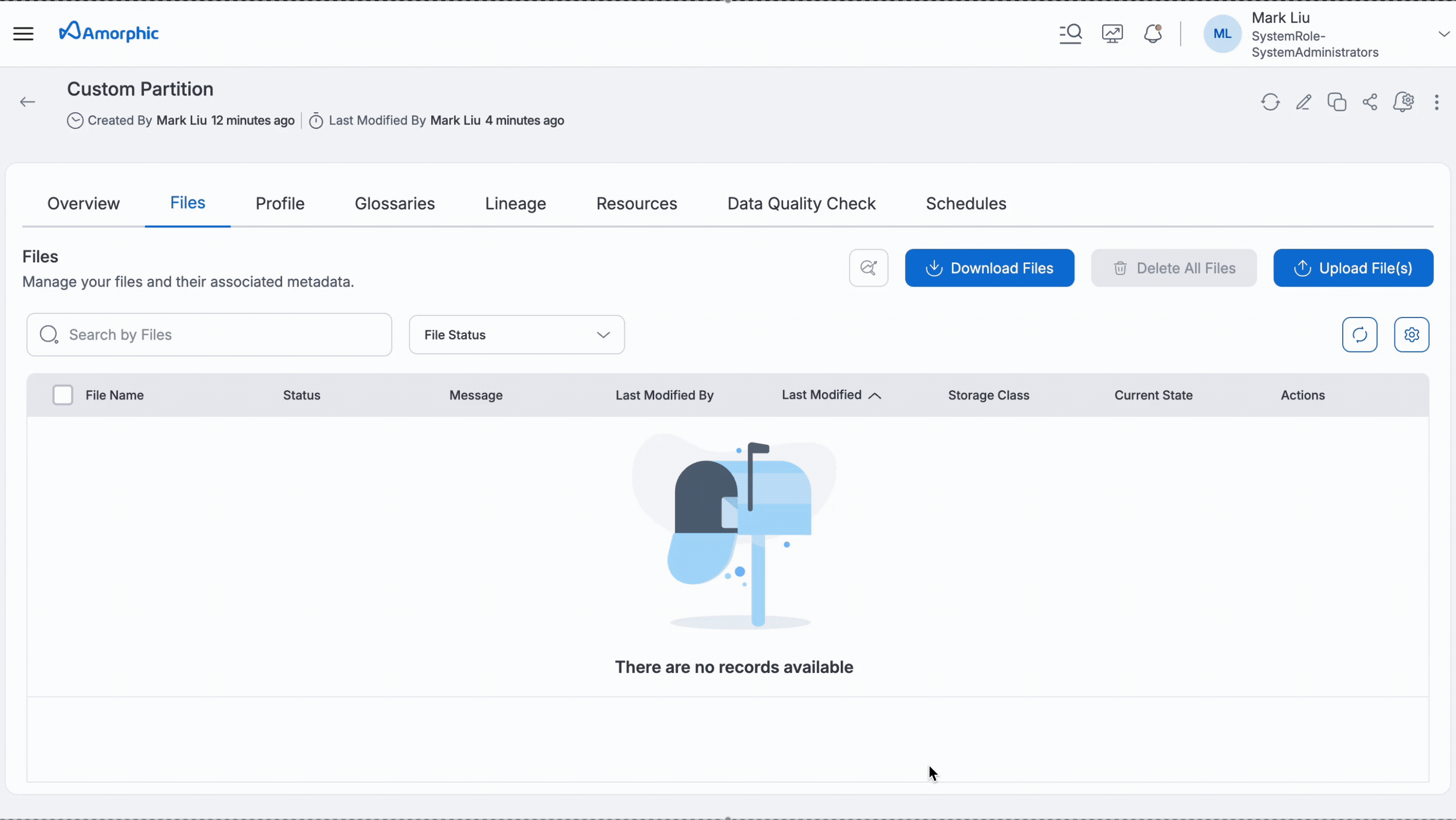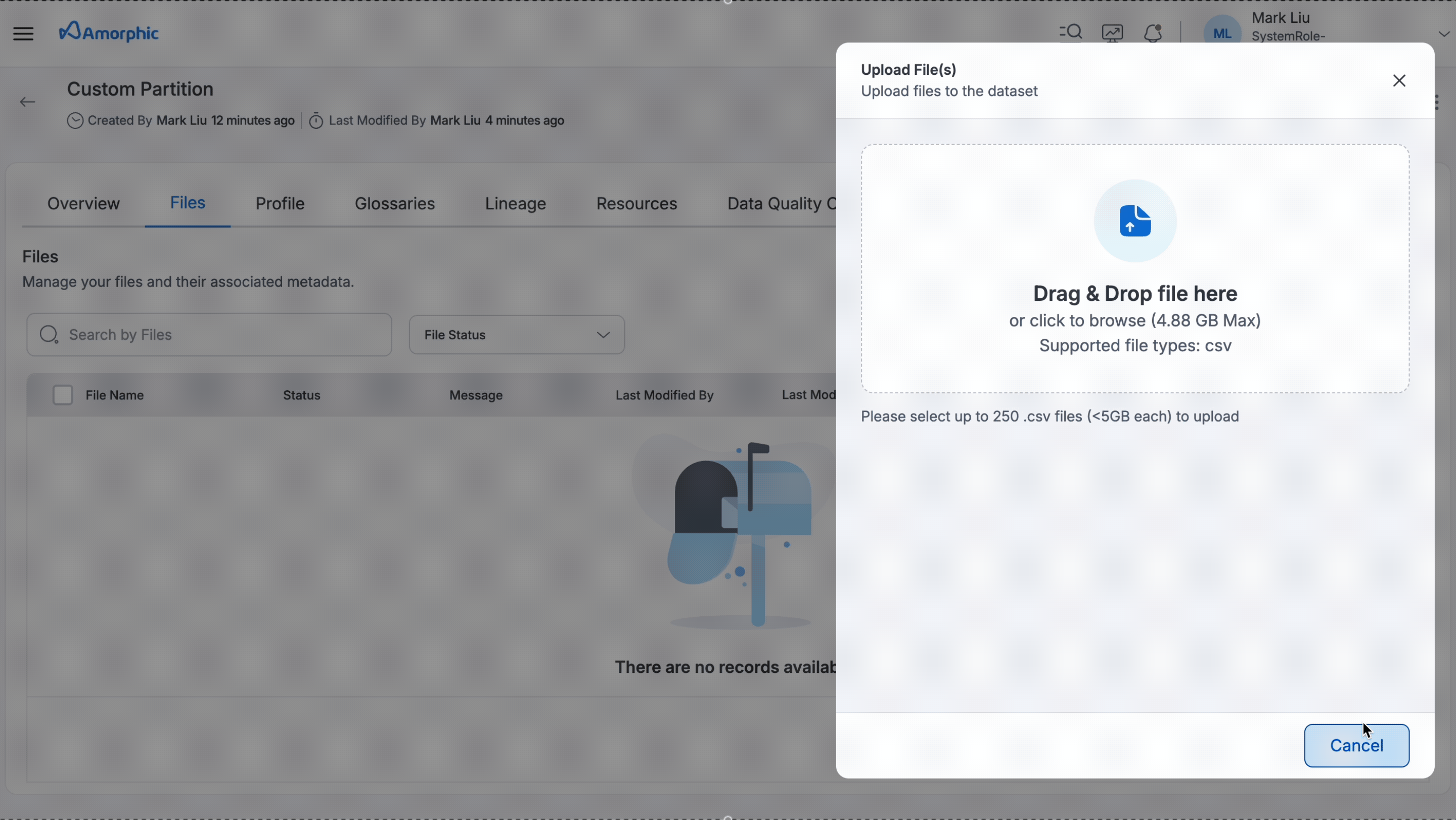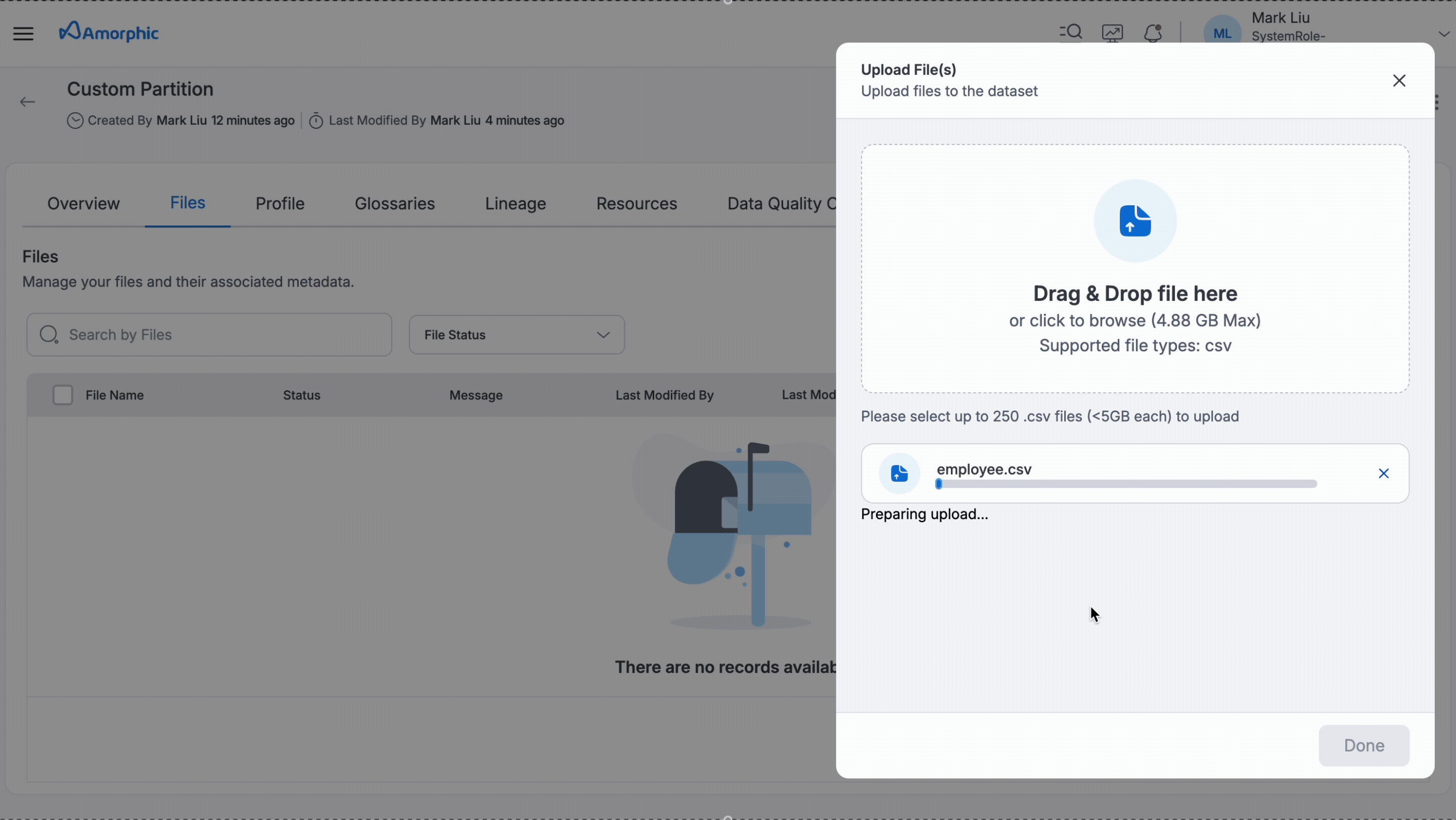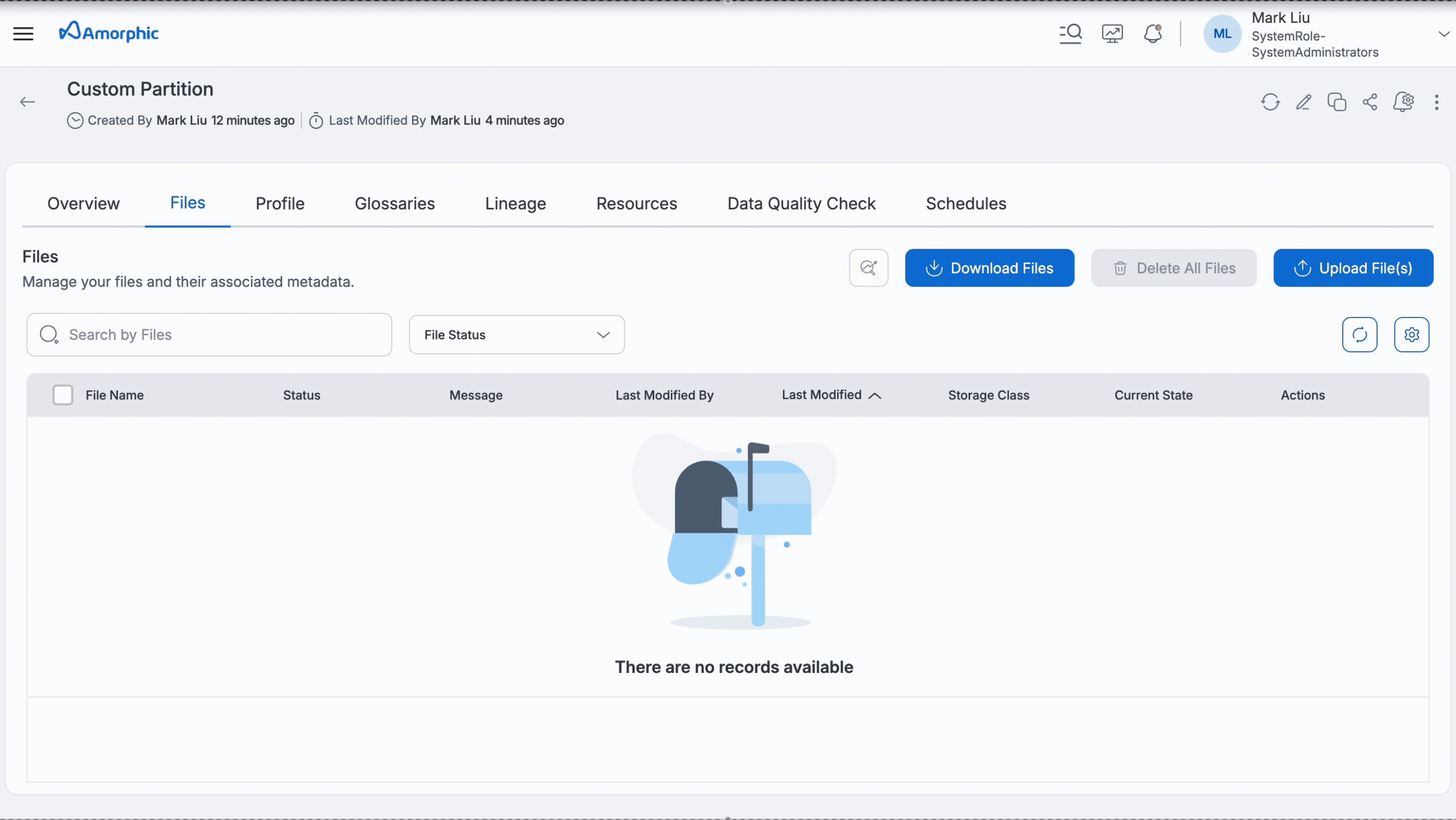
Sync Partitions
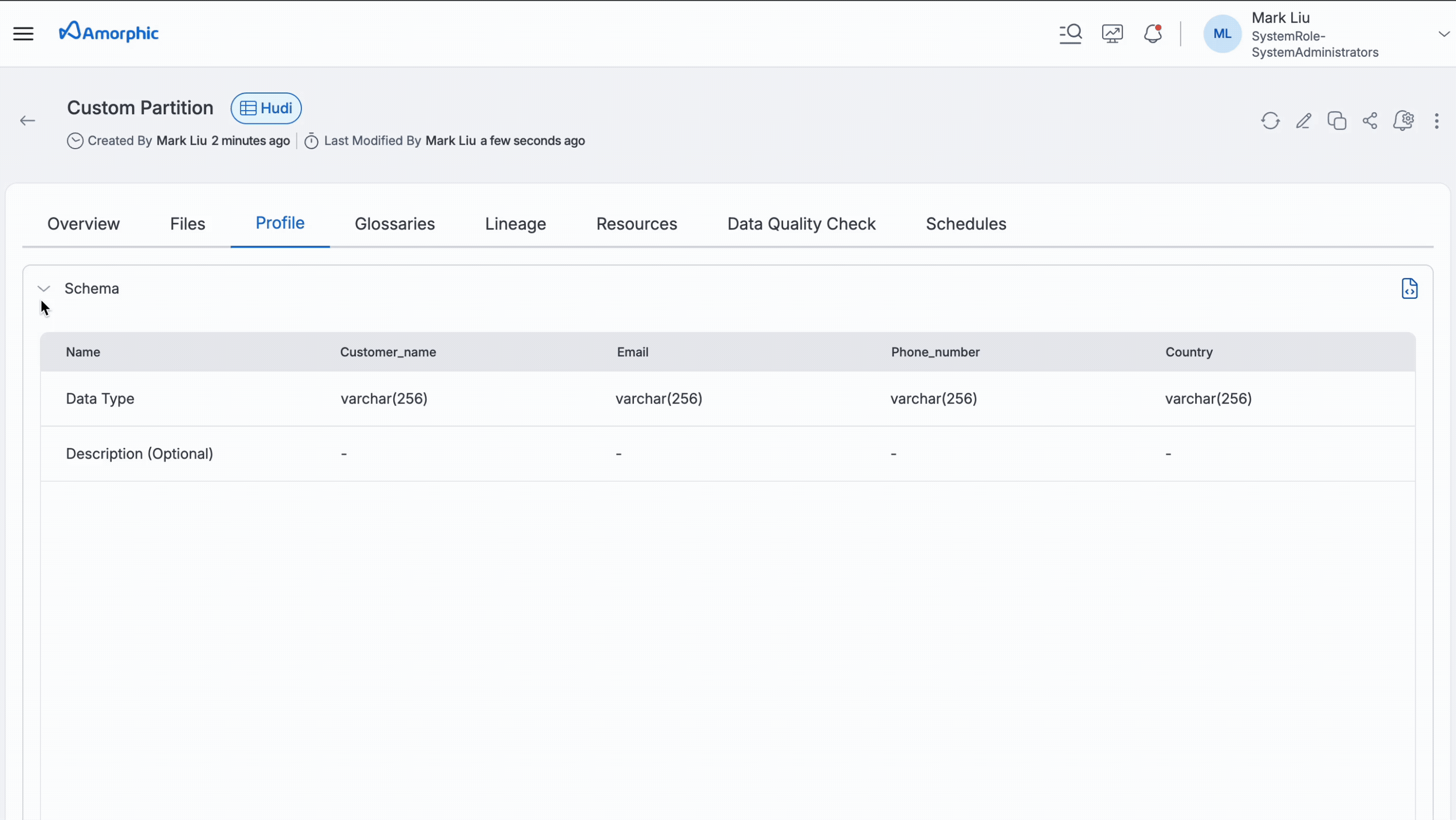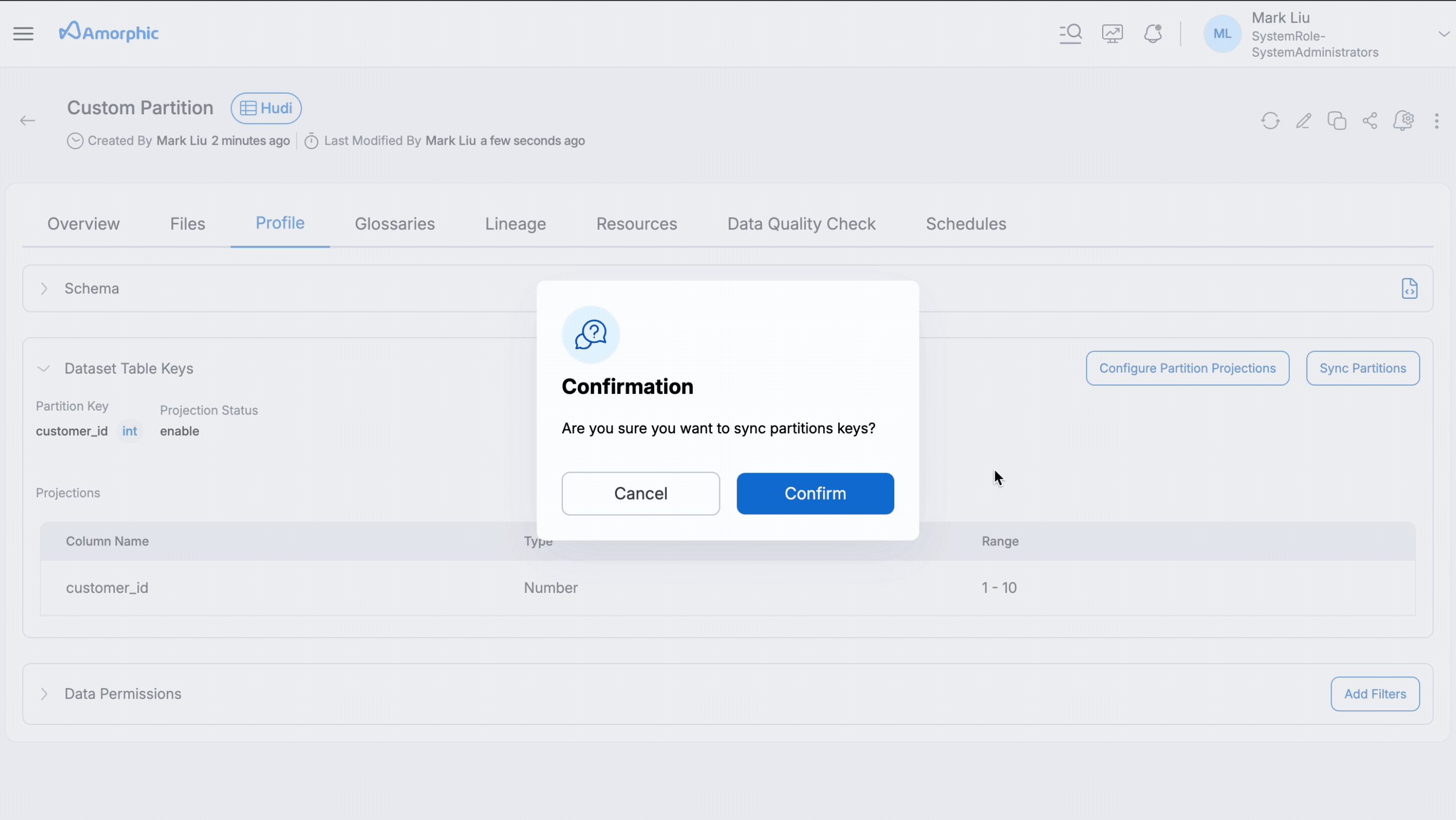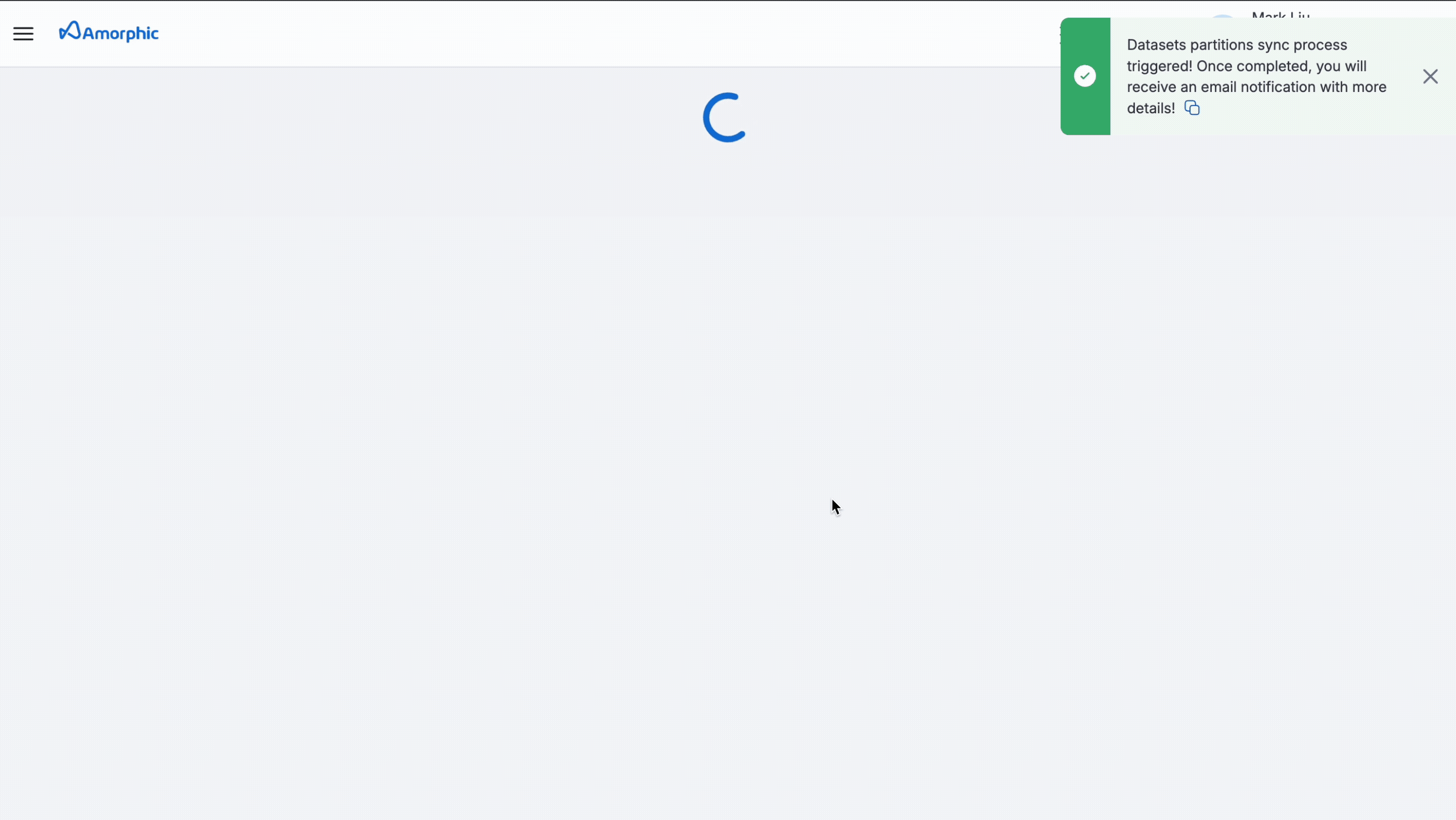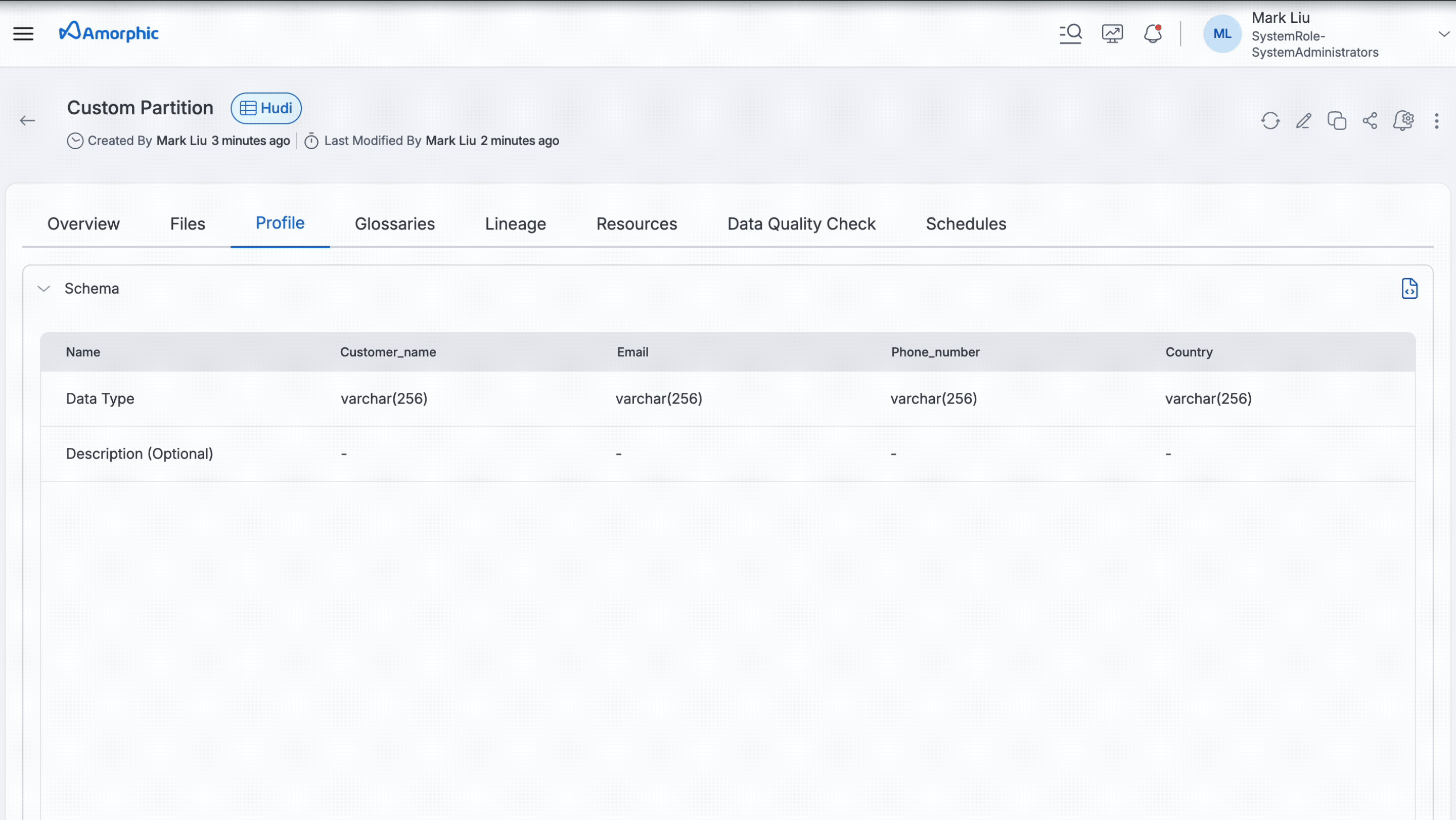
The partition synchronization feature enables automatic syncing of partitioned data from source location to their corresponding target datasets in Amorphic. This functionality supports:
-
External LakeFormation Datasets: Automatically adds all source partitioned data to the Amorphic table, making the data immediately available for querying without manual intervention.
-
Internal LakeFormation Hudi Datasets: Automatically adds partitioned data to the Hudi table created in Amorphic. This is particularly beneficial for Merge On Read (MoR) table types, as it eliminates the need for additional 'ADD PARTITION' queries to make partitioned data available.
Following GIF shows how to sync partitions.
Partition Projection
Partition projection makes queries run faster when working with data that's split into many folders (partitions). Think of it as an efficient indexing system that directly locates data storage paths, eliminating the need to manually search through every folder to access information.
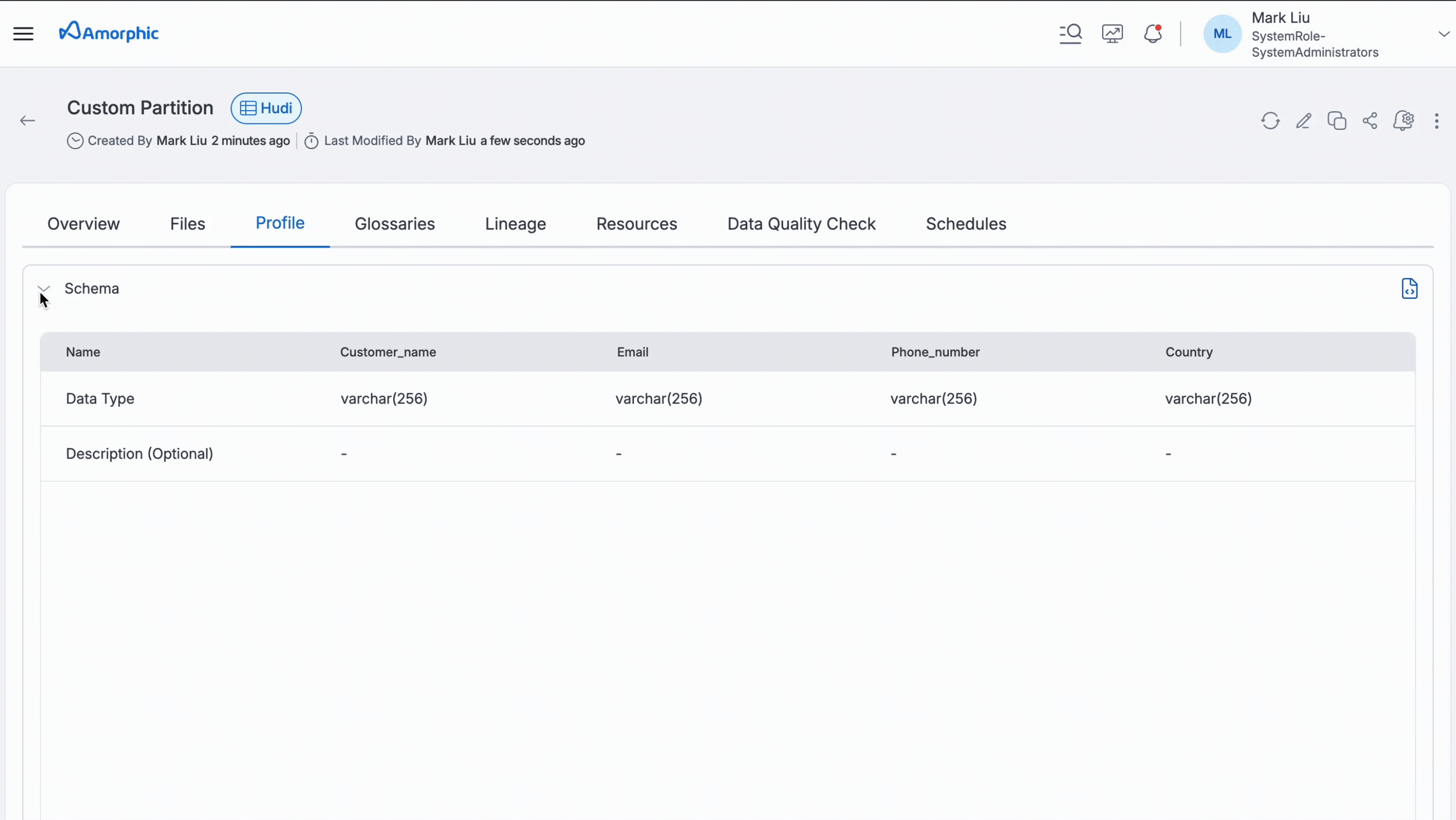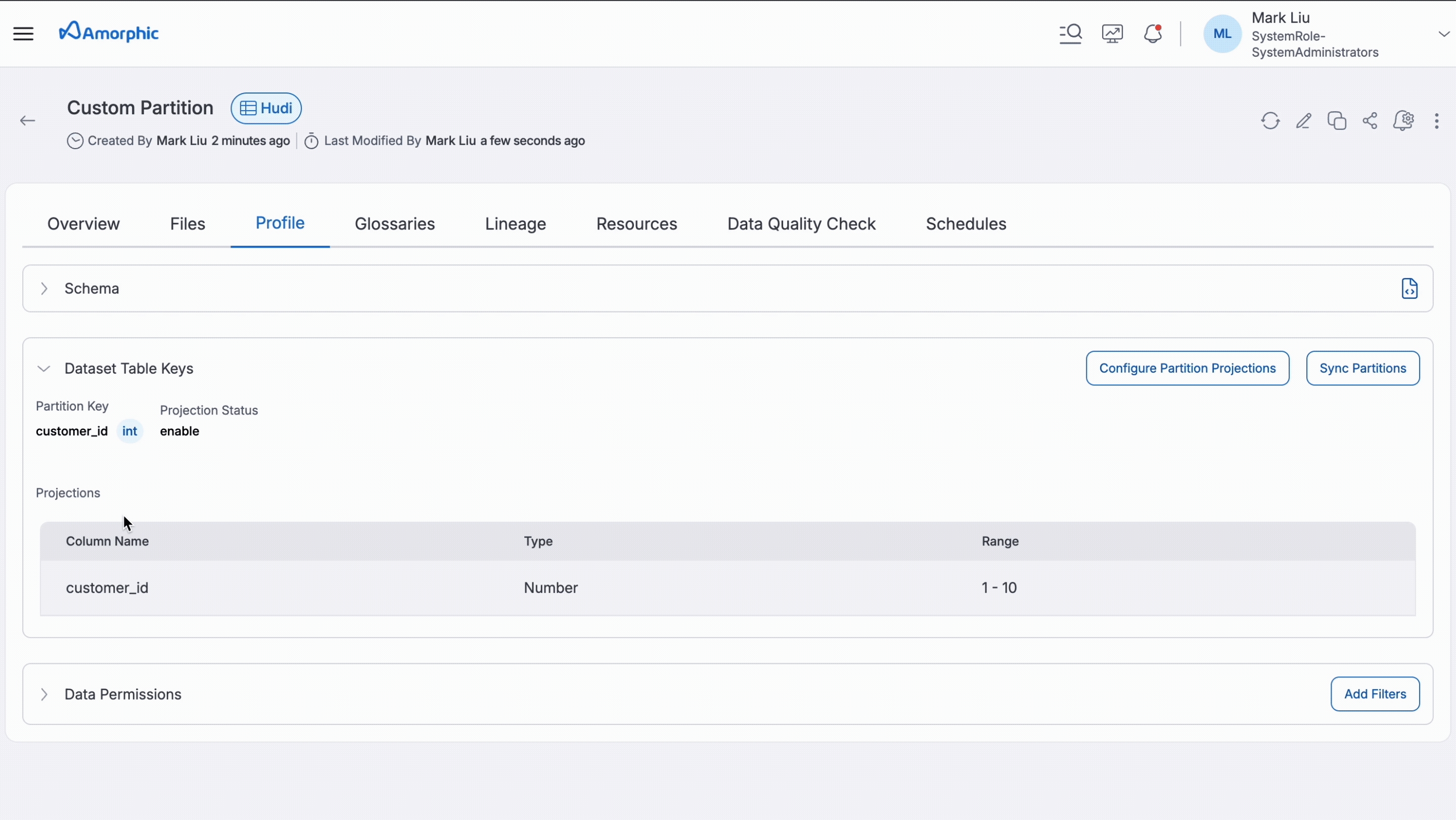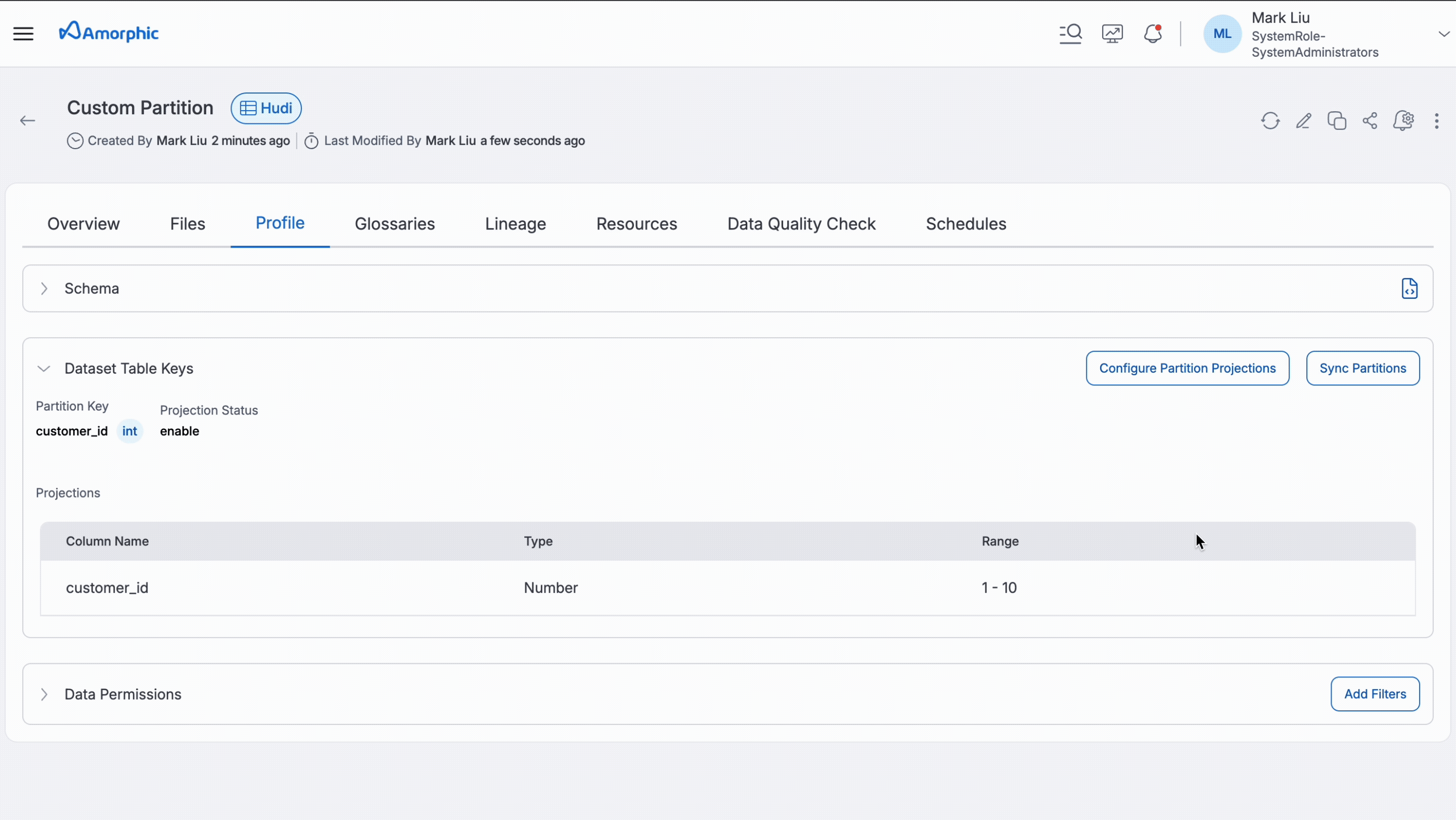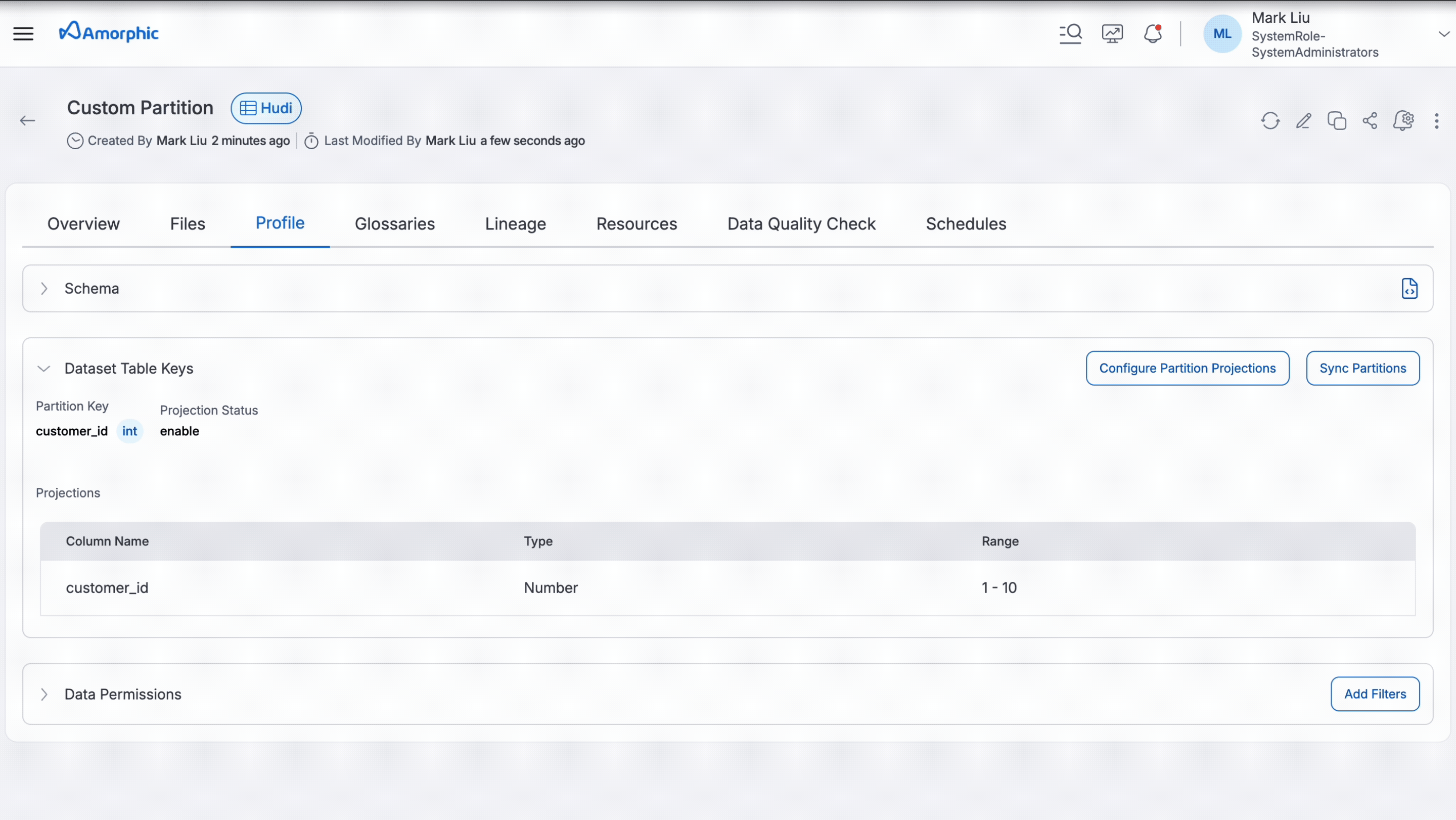
How It Works
The system uses a projection pattern to calculate where data is stored instead of scanning all folders, making queries faster and more efficient.
Benefits
- Faster queries - Searches start almost immediately
- Works with big data - Even with thousands of folders, performance stays fast
- Automatic organization - The system finds the right data folders on its own
When to Use Partition Projection
This feature is especially helpful when:
- Queries are slow because of hundreds or thousands of data folders(partitions)
- Data is regularly added by date (daily, monthly, etc.)
- Only a small portion of the total data is needed in each query
Types of Partitioning
Data folders can be organized using different patterns:
- By date (date) - For data split by year, month, or day
- By numbers (integer) - For data organized by numeric values
- By category (enum) - For data divided into groups (like regions or departments)
- By custom values (injected) - For data that needs specific values provided in queries
Setting It Up
Partition projection works with external LakeFormation datasets and internal LakeFormation Hudi datasets.
Following GIF shows how to enable partition projection for a dataset. In the example below, after setting up partition projection, users will get data of the customers whose customer_id is between 100 and 200.
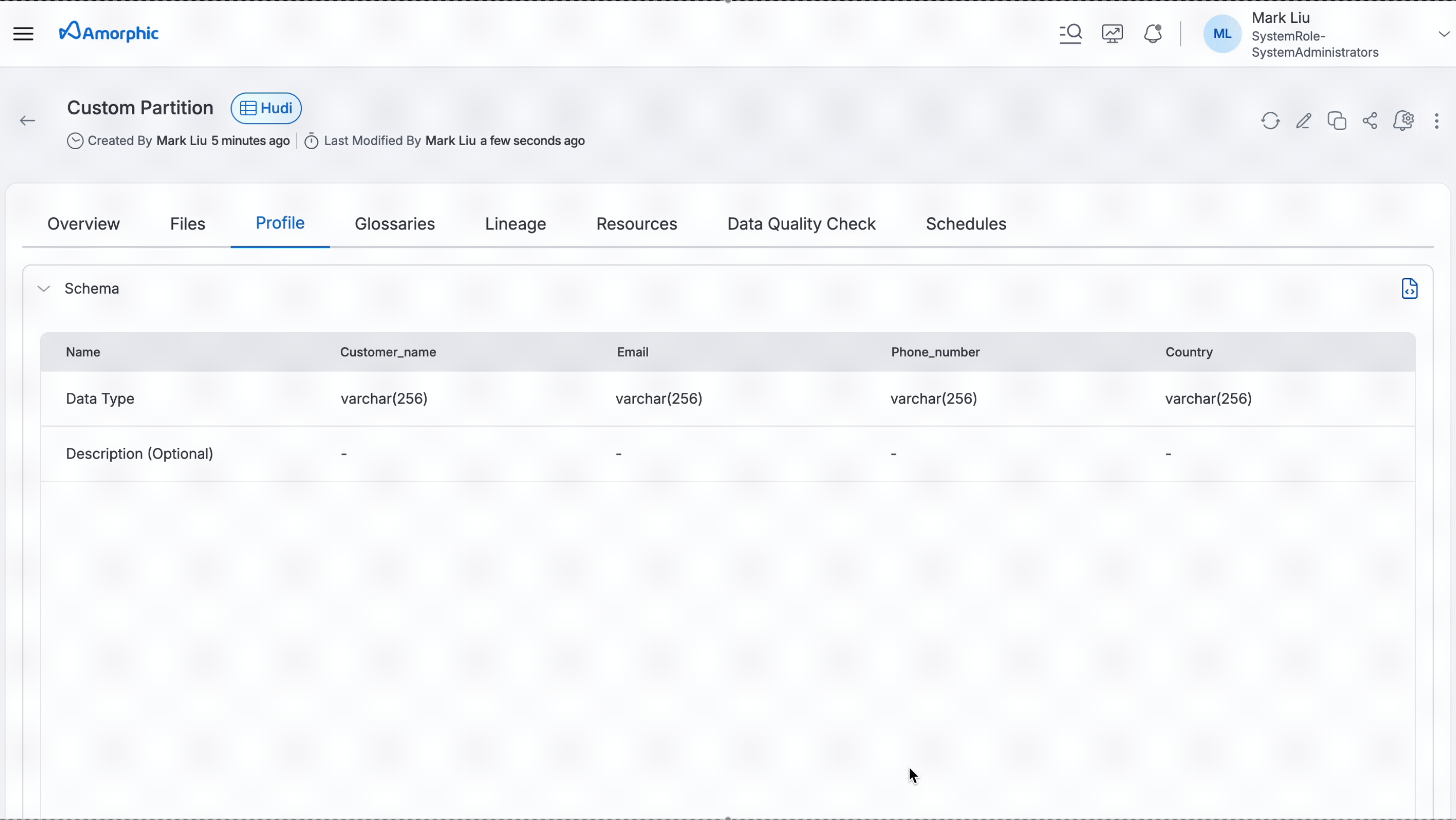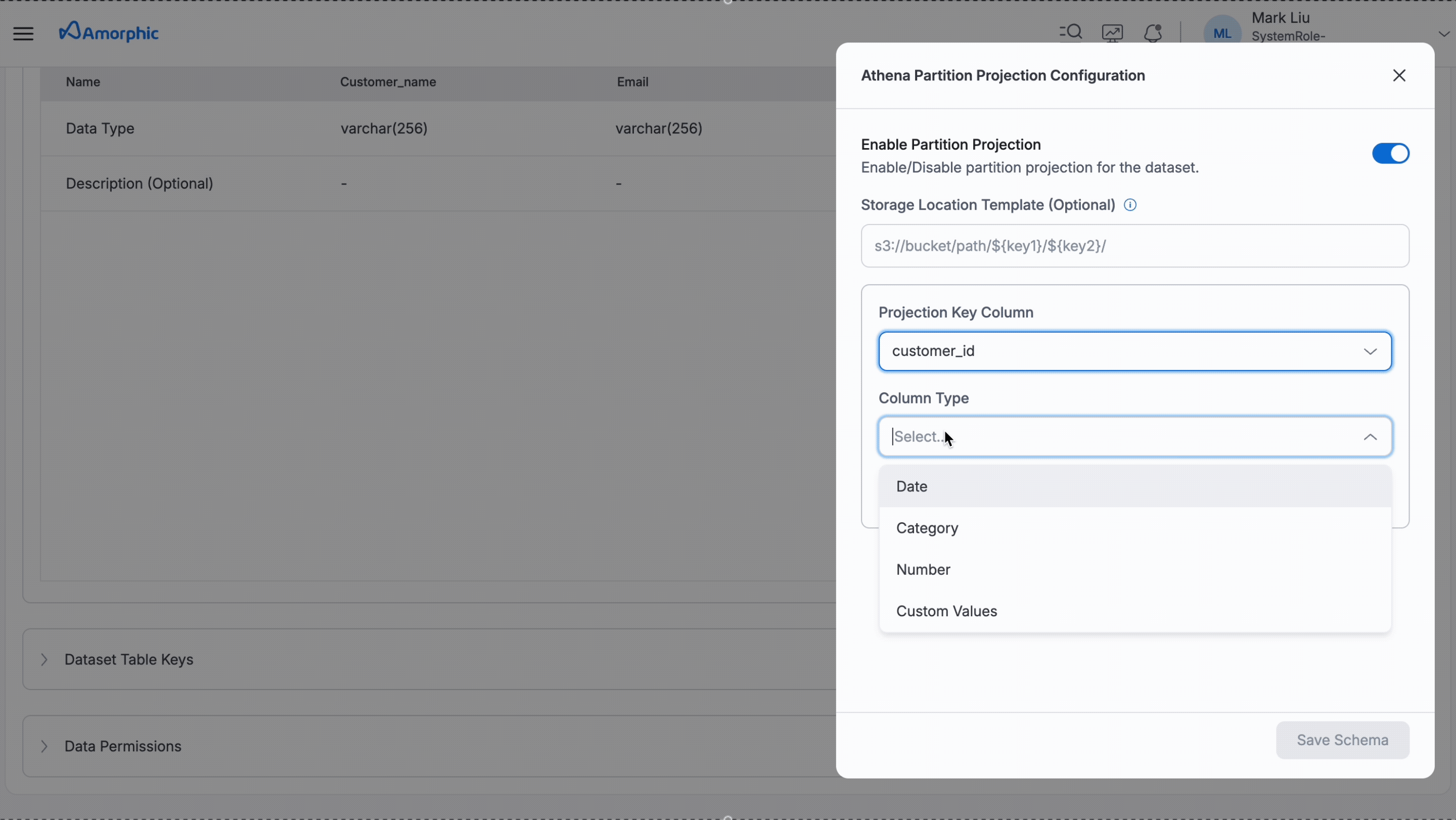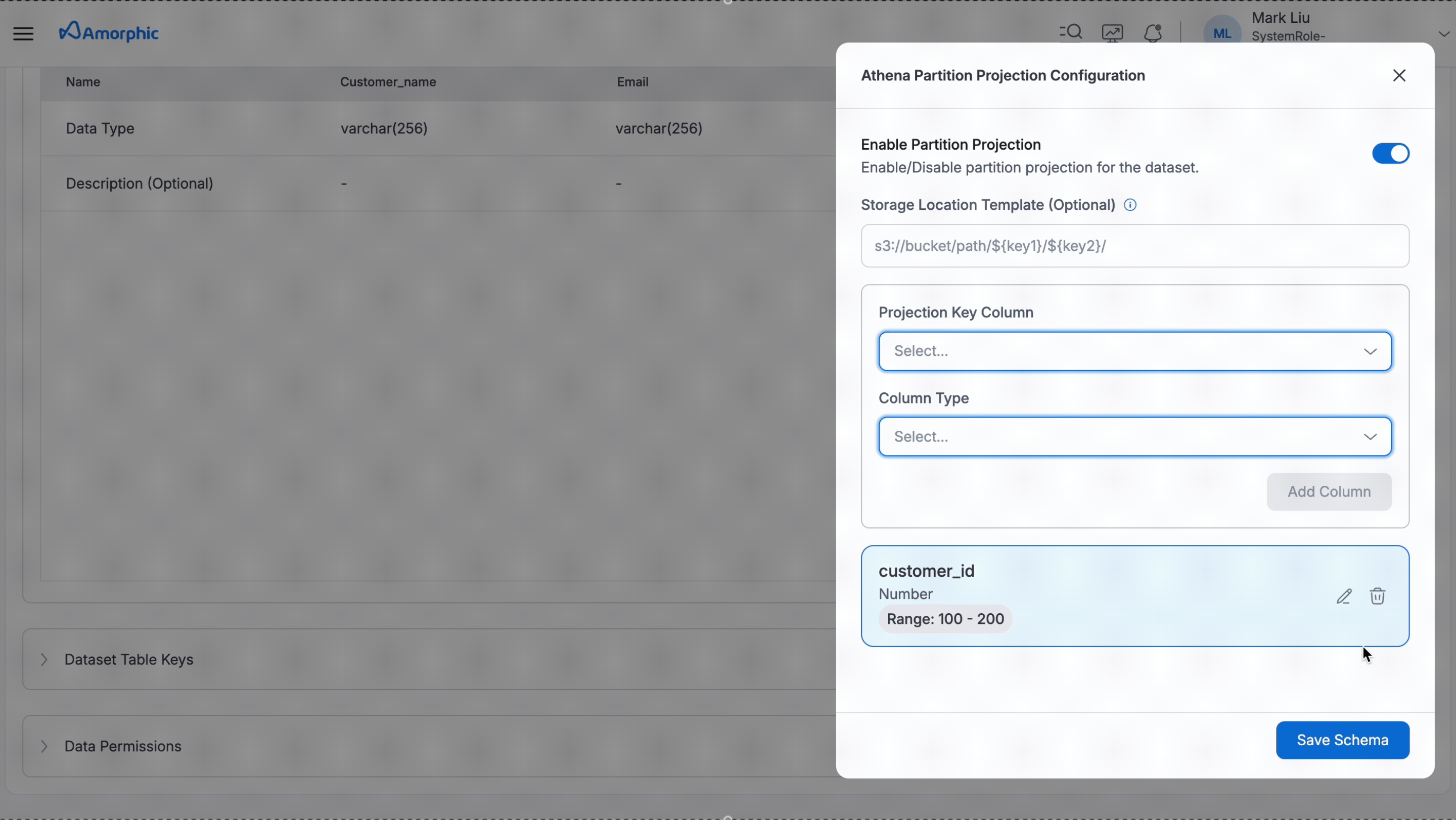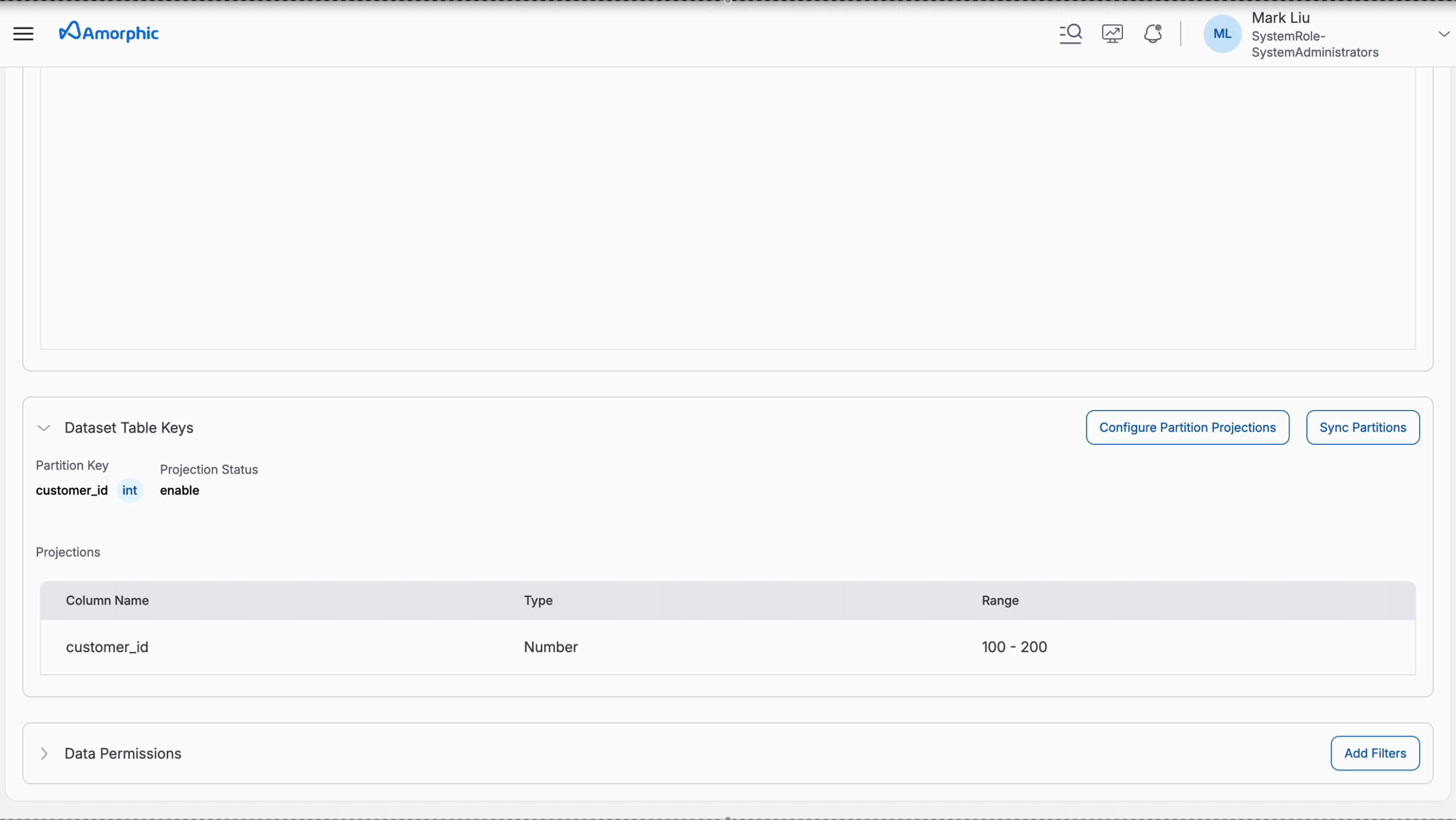
The StorageLocationTemplate field is optional. When omitted, the system assumes data follows the standard folder naming pattern (like bucket/table_name/month=01/day=15/).
This can be included if data folders use a different format and all the partition keys should be available in the template.
Examples by Partition Type
Date Type Example
{
"ColumnName": "date_partition",
"Type": "date",
"Range": ["2020-01-01", "2023-12-31"],
"Format": "yyyy-MM-dd",
"Interval": "1",
"IntervalUnit": "DAYS"
}
If date format contains time information, it should have interval and interval unit.
Number Type Example
{
"ColumnName": "year",
"Type": "integer",
"Range": [1990, 2030]
}
Category Type Example
{
"ColumnName": "region",
"Type": "enum",
"Values": ["us-east", "us-west", "europe", "asia"]
}
Keeping the Values to a small number of values will help in faster query performance. If the number of values is large, it will take more time to query the data.
Custom Value Type Example
{
"ColumnName": "customer_id",
"Type": "injected"
}
For the Custom Value Type, data will be fetched from partitions based on values provided in the query's WHERE clauses.
API Payload Example
Path: /datasets/{id}/updatemetadata
Method: PUT
{
"PartitionProjectionConfig": {
"ProjectionStatus": "enable",
"Projections": [
{
"ColumnName": "year",
"Type": "integer",
"Range": [2020, 2023]
},
{
"ColumnName": "month",
"Type": "integer",
"Range": [1, 12],
"Digits": "2"
},
{
"ColumnName": "region",
"Type": "enum",
"Values": ["north", "south", "east", "west"]
}
],
"StorageLocationTemplate": "s3://my-bucket/data/year=${year}/month=${month}/region=${region}/"
}
}
- Always include start and end values for date and number ranges
- For dates with time information (like hours and minutes), specify both the Interval and IntervalUnit
- The folder path template (StorageLocationTemplate) is optional, but if included, it must start with "s3://", use '${key}' for partition names, and end with "/"
- All partition keys should be present in the dataset schema for hudi datasets
- Each folder level (partition) should only be configured once