
Intro
The Amorphic Dataset portal enables the creation of unstructured, semi-structured, and structured datasets while providing comprehensive data lake visibility. These datasets serve as a unified source of truth for different departments within an organization.
Users can access and explore available datasets under the Discover section: Discover → Datasets.
The Amorphic Dataset page provides Google-like search capabilities for dataset metadata, allowing users to efficiently discover and manage datasets. Users can list or create new datasets, sort them by attributes such as Dataset Name, and filter datasets based on attribute values for precise navigation. Additionally, users can select the attributes they want to display on the listing page for a customized view.

How to create a New Dataset?
To create a new dataset, click on + New Dataset on the listing page. Users can choose from three methods to create a dataset:
To create a dataset in Amorphic, first, create a Domain using Amorphic Administration. Then, create a dataset and upload structured, semi-structured, or unstructured files to it.
- Using a Template – Start with a predefined structure, making dataset creation quick and standardized.
- Importing JSON – Upload an existing JSON file to define the dataset structure automatically.
- Create from Scratch – Manually build a dataset with fully customizable configurations.
Using a Template
Users can select a template from the list of templates that are available by default, as well as those created by other users.
After registering the dataset, users can conveniently save the templates for future use, allowing for quicker and more efficient dataset creation in subsequent instances.
Importing JSON
Users can upload a JSON file that includes the necessary attributes and values to automatically define the dataset structure. The following JSON provides an example of this process. This option is intended for advanced users who understand the API and the payload format.
Example JSON
{
"DatasetName": "Payroll_Data",
"DatasetDescription": "Dataset containing payroll-related records for employees.",
"Domain": "hr",
"Keywords": ["Owner: HR_Team", "Category: Payroll"],
"DatasourceType": "api",
"FileType": "csv",
"IsDataCleanupEnabled": false,
"LifeCyclePolicyStatus": "Disabled",
"TargetLocation": "s3",
"MalwareDetectionOptions": {
"ScanForMalware": true,
"AllowUnscannableFiles": false
},
"SkipFileHeader": false,
"SkipLZProcess": false,
"TableUpdate": "append",
"DataMetricsCollectionOptions": {
"IsMetricsCollectionEnabled": true
},
"AreAIServicesEnabled": false,
"DatasetType": "internal"
}

Create from Scratch
This option allows users to manually build a dataset with fully customizable configurations.
Dataset Configuration Attributes
Following are the attributes that users can configure while creating a new dataset:
Basic Information
- Dataset Name: 3-120 alphanumeric/underscore characters; Must be unique per Domain.
- Description: Contains information about a topic; text searchable.
- Domain Name: Groups related datasets; used as 'database' in Glue/Athena, schema in Redshift.
- Keywords: Meaningful words to index/search within the application; helps find related datasets.
- Dataset Type: Decide whether the dataset is internal, external or view type.
Connection & File Settings
- Datasource Type: Amorphic currently supports:
- File Upload: Default connection for manual file upload. Refer to Dataset files documentation.
- JDBC: Ingest data from JDBC connection as source to dataset. Scheduled ingestion.
- S3: Ingest data from S3 connection. Scheduled ingestion.
- Ext API: Ingest data from external API. Scheduled ingestion.
- Email: Ingest data sent over emails.
- File Type: File type should be compatible with ML Model's supported formats. Use auto ML to extract metadata from unstructured datasets integrated with AWS Transcribe and Comprehend services.
Target Location
Amorphic currently supports:
- S3: Files uploaded to dataset stored in S3.
- Redshift: Files stored in Redshift datawarehouse. DB selection during deployment determines which DB is displayed.
- S3-Athena: Structured data stored in Athena. Refer to Athena Datasets for more information.
- Lakeformation: Lakeformation datasets extend S3-Athena datasets, providing access control on dataset columns. For more information, see Lakeformation Datasets.
- DynamoDB: For storing structured data as key-value pairs. Refer to DynamoDB Datasets for more information.
If the target location is a data warehouse (Redshift/S3-Athena), users should upload a file for schema inference and then publish the schema.
Update Methods
Amorphic currently supports three update methods:
- Append: This will append data to the existing data.
- Latest Record: This update method allows users to query the latest data using the Record Keys and Latest Record Indicator defined during the schema extraction process.
- Reload: This update method reloads data to the dataset. There are two exclusive options for a Reload type dataset:
-
Target Table Prep Mode
- Recreate: Dataset will be dropped and recreated when this option is selected.
- Truncate: Just the data is deleted in the dataset without deleting the table.
-
Skip Trash (Optional): When Skip Trash is True, old data is not moved to Trash bucket during the data reload process; default is true when not provided.
Based on the above reload settings, data reload process times can vary.
-
Header & Row Handling
- Data Files Have Headers: Users can specify if dataset files contain headers. Files must consistently include or not include headers. In the schema definition step, users may use a sample file with headers even if the final dataset files will not contain headers.
-
For S3-Athena and Lake Formation datasets:
- Skip Header Row Count: Specify the number of lines (from the start of the file) to be ignored for every file while querying the dataset. This count includes the header along with data rows.
- Skip Footer Row Count: Specify the number of footer lines to be ignored for every file while querying the dataset.
- Example: If a user created an S3Athena/Lakeformation dataset with skip header count as 10 and footer count as 5, and uploaded a file with 30 rows, then ONLY 16 rows will be retrieved when querying the dataset by excluding the first 9 data rows (1 for header) and last 5 rows i.e., 30-9-5 = 16 data rows.
Important NoteNo changes are made to the original data uploaded to the dataset. This functionality just ignores the header/footer rows while querying the dataset, and files stored in S3 will retain all data rows.
-
For Redshift datasets, if 'Data Files Have Headers' is set to Yes:
- Skip Header Row Count: Specify the number of lines (from the start of the file) to be ignored for every file being uploaded to the dataset.
- Example: If a user created a Redshift dataset with skip header count as 10 and uploaded a file with 30 rows, then ONLY 21 rows will be uploaded to the dataset by excluding the first 9 data rows (1 for header) i.e., 30-9 = 21 data rows.
Important NoteChanges are made to the original data uploaded to the Redshift dataset. The original data is still present in S3, which can be queried using Query Target location as Athena.
-
Validation & Processing
- Skip LZ (Validation) Process: If Skip LZ is set to True, the whole validation (LZ) process will be skipped and the file will be directly uploaded to the DLZ bucket. This avoids unnecessary S3 copies and validations, and automatically disables MalwareDetection and IsDataValidationEnabled (for S3Athena and Lake formation datasets). It is applicable only to append and update types of datasets. If set to False, the LZ process with validations will be followed.
As of Amorphic 1.14, this is applicable to the dataset file upload process through Amorphic UI (manual file upload), ETL (file write) process streams, and Appflow. It is not applicable to other file upload scenarios like ingestion and Bulkloadv2. The SkipLZ feature will be implemented for these other scenarios in upcoming releases.
Security & AI Features
- Enable Malware Detection: Choose whether to enable or disable malware detection on the dataset.
- Unscannable Files Action: When malware is found in a file uploaded to the dataset, decide whether to quarantine or pass-through the file.
- Enable Data Profiling: This is only applicable for datasets targeted to S3Athena or DataWarehouse (Redshift).
- Enable AI Services: Only applicable for datasets targeted to S3.
- Enable AI Results Translation: Users can enable/disable AI result translation to English for datasets. Amorphic runs ML algorithms to analyze PDF/TXT files uploaded to datasets. This option enables/disables auto-translate AI results to English for reading/searching Amorphic interfaces.
For example, Amorphic can identify language, run ML algorithms & analyze sentiment in an Arabic PDF document. Setting the flag to "No" allows users to preserve native language and query AI results in the original language. AI results default to English unless users specify another language.
Data Management
- Enable Data Cleanup: Users can enable/disable dataset auto clean up. Data deletion to save storage costs is based on the input clean up duration. All files past the expiration date (clean up duration) will be permanently removed and cannot be recovered. Expired datasets are identified by upload date, not time. For example, a file uploaded on August 21, 2020, at 4:55 PM with a clean up duration of 2 days will be cleaned up on August 23, 2020, at 12:00 AM, not 4:55 PM.
- Enable Life Cycle Policy: Only applicable for datasets targeted to S3, S3-Athena & LakeFormation.
- Enable Data Metrics Collection: This feature is available for all datasets regardless of their TargetLocation. When enabled, dataset metrics are collected daily and displayed on the Insights page. Collected metrics automatically expire after one year. To fetch dataset metrics up to given duration in days
Metadata & Classification
- Data Classification: This is a list of values (such as PII, PCI, etc.) that can be used to classify the dataset. This will help to search and filter datasets from the dataset listing or catalog.
Fetch Dataset Metrics
Retrieve comprehensive metrics for a dataset over a specified duration in days using the following API endpoint:
Endpoint: /metrics/datasets/{id}?duration={days}
Method: GET
-
Parameters:
id: Unique identifier of the datasetduration: Number of days to fetch metrics for
-
Sample Response:
{
"FileCount": 1,
"TotalFileSize": 5391,
"AvgFileSize": 5391,
"ProcessingFiles": 0,
"TotalFiles": 2,
"CorruptedFiles": 0,
"FailedFiles": 1,
"CompletedFiles": 1,
"DeletedFiles": 0,
"InconsistentFiles": 0, // Negative value indicates S3 has more files than DynamoDB metadata
"PendingFiles": 0,
"DependentResources": {
"Views": 2,
"Jobs": 3,
"Workflows": 1,
"Datalabs": 1
},
"AuthorizedTags": 2,
"DuplicateRows": 0,
"Columns": 7,
"DatasetSize": "10 MB",
"Rows": 100,
"PercentageOfDuplicateRows": 0.0,
"LastUpdated": "2023-08-15T12:00:00Z"
} -
Key Metrics Explained:
- File Metrics: Track file processing status (completed, failed, pending, etc.)
- Data Quality: Includes duplicate rows, column count, and row count
- Storage: Total dataset size and file size metrics
- Dependencies: Count of dependent resources (views, jobs, workflows, datalabs)
- Security: Number of authorized tags with access to the dataset
The dependent resources section may include various resource types beyond just views, depending on the dataset's usage and integrations.
Dataset Notification Settings
Users can configure notifications to stay informed about important changes to their datasets. Below are the available notification settings for dataset resources:
Notification Preferences
Users can configure how they receive updates related to their datasets and associated resources. Notification preferences are available for both Email Notifications and Push Notifications. You can toggle Select All to enable or disable all preferences at once.
Notification Categories
| Setting | Trigger Condition | Description |
|---|---|---|
| Update | Metadata changes | Notifies users when any dataset metadata is modified (e.g., name, description) |
| Delete | Dataset deletion | Alerts users when a dataset is permanently deleted from the system |
| DataUpdate | Data modifications | Sends notifications when the dataset's content is updated or changed. See data update subcategories for available options below |
| DataError | Data loading issues | Notifies users of any errors that occur during data ingestion or processing |
| AuthUpdate | Access changes | Alerts users when authorization grants are modified (user/group access changes) |
Data Update Subcategories
| Subcategory | Description |
|---|---|
| File Upload | Sends notification when files are uploaded to the dataset. |
| Delete All Files | Alerts users when all files are deleted. |
| Delete Pending Files | Notifies users when pending files are deleted. |
| Permanent Deleted Files | Sends notification when files are permanently removed. |
| Restore Deleted Files | Sends notifications when files are restored from deleted state. |
| Temporary Deleted Files | Notifies users when files are temporarily deleted. |
Below is a GIF demonstrating how to configure dataset notification settings:
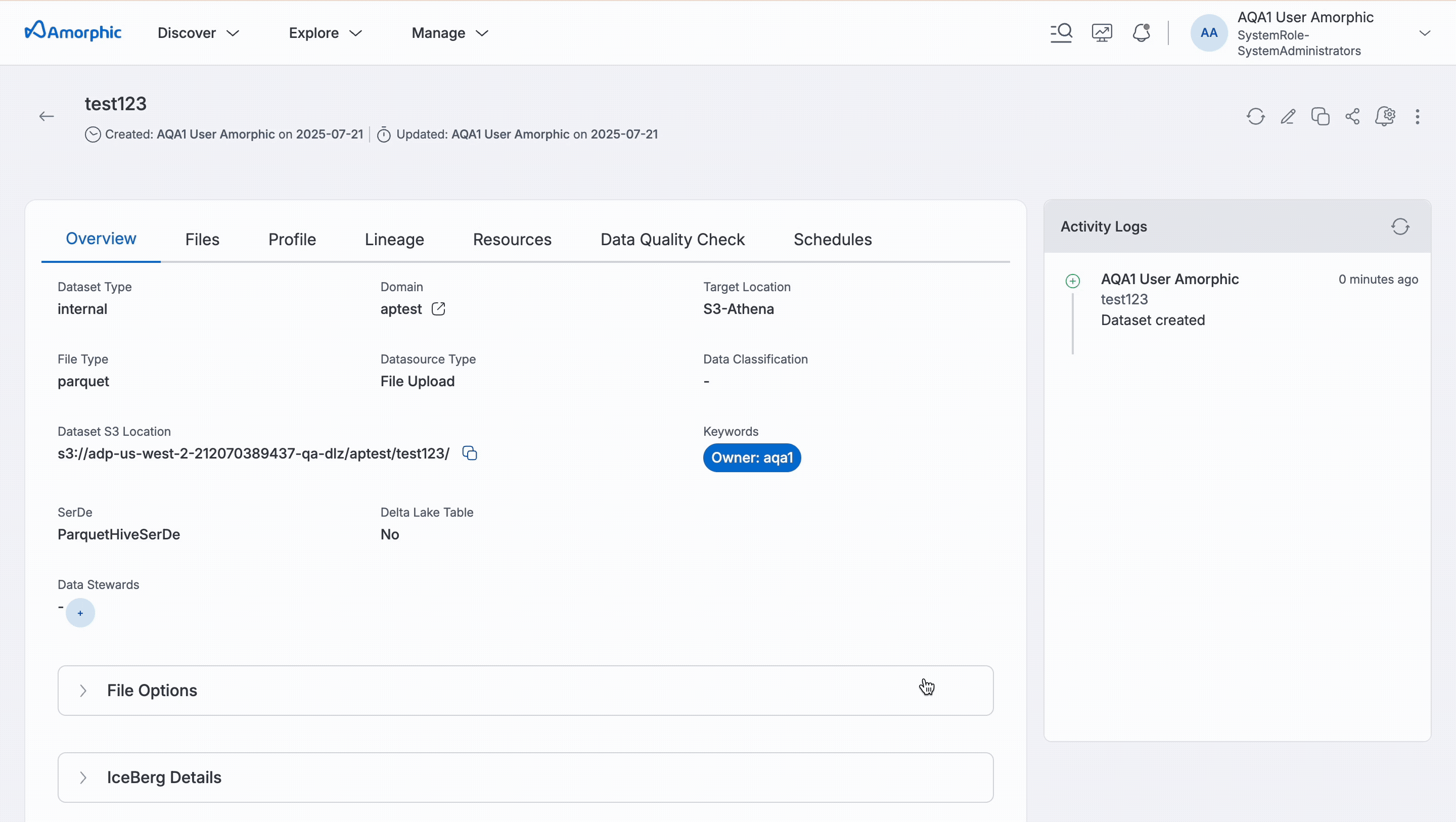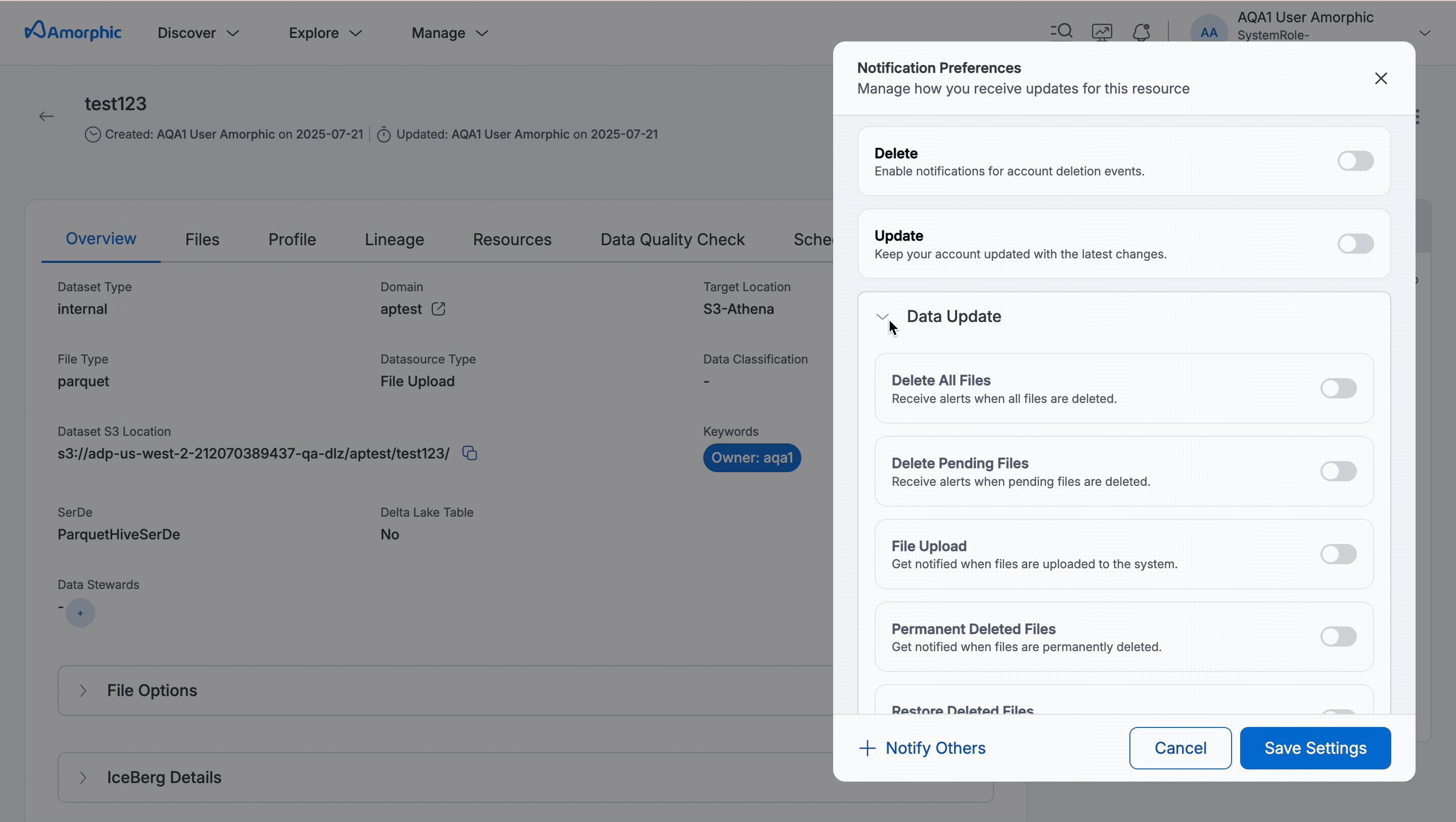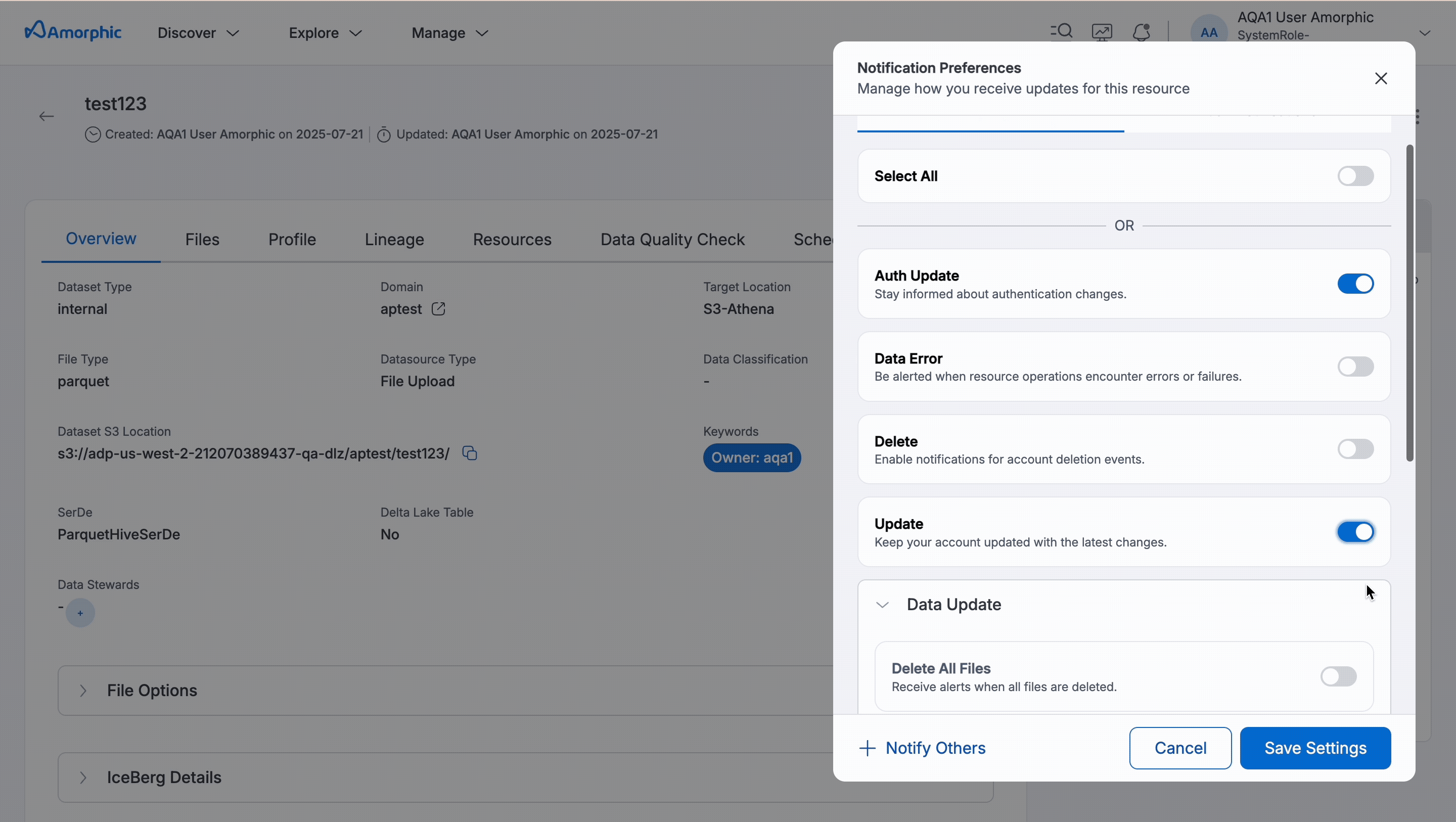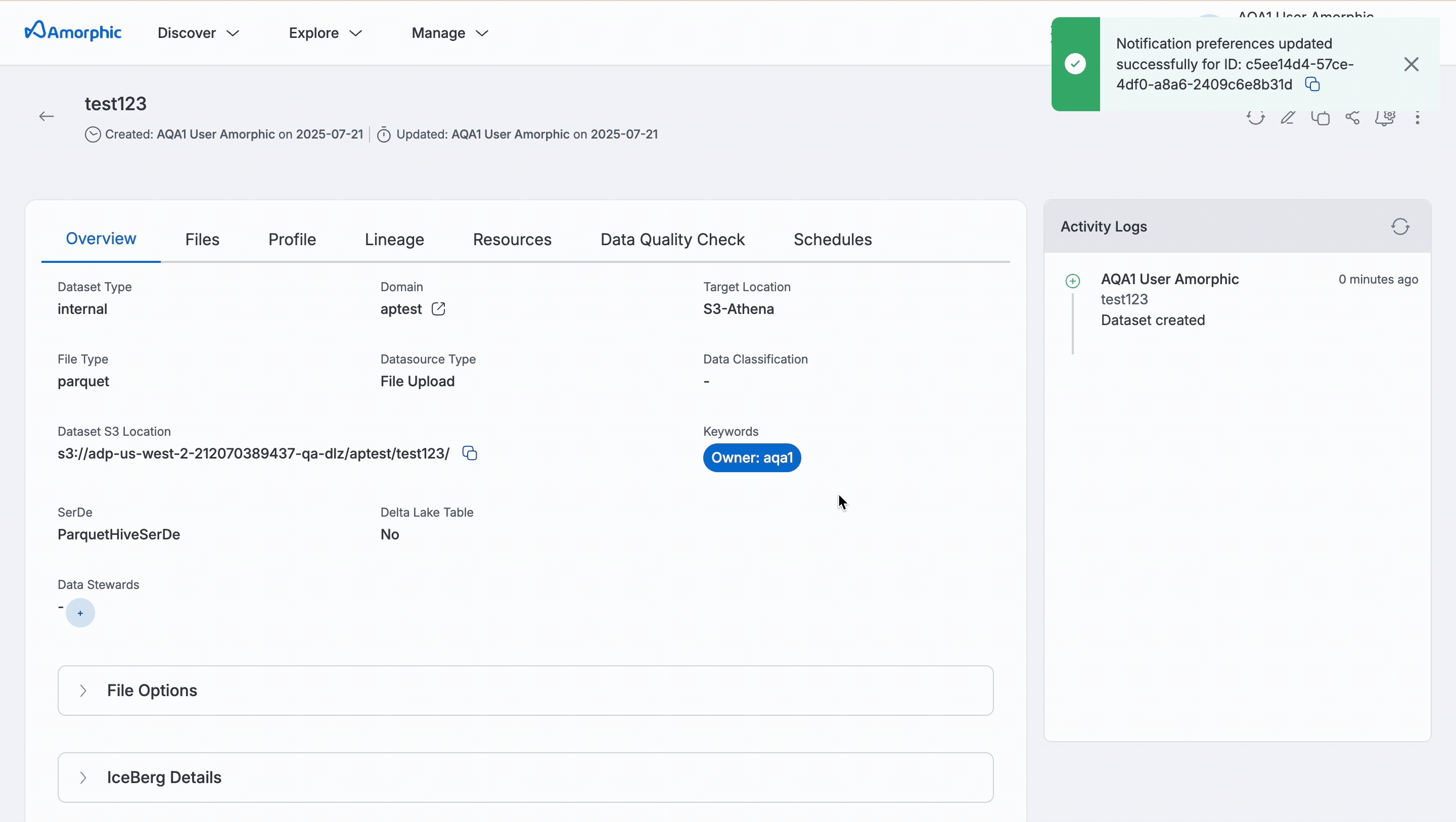
Enable notifications for critical operations like Delete and DataError to maintain awareness of potential data loss or processing issues.
Schema
 The Amorphic Dataset Registration feature provides robust schema management capabilities when users select S3-Athena, LakeFormation, Redshift, or DynamoDB as their target location. This feature automatically extracts and registers the schema from uploaded files, ensuring:
The Amorphic Dataset Registration feature provides robust schema management capabilities when users select S3-Athena, LakeFormation, Redshift, or DynamoDB as their target location. This feature automatically extracts and registers the schema from uploaded files, ensuring:
- Seamless Integration: Direct compatibility with the selected storage and query services
- Consistent Data Structure: Proper schema enforcement across all data operations
- Efficient Data Management: Automated schema handling reduces manual configuration
- Service Optimization: Tailored schema implementation for each supported target location
This functionality streamlines the data onboarding process while maintaining data integrity across different storage platforms.
Schema Definition
Users can upload a schema using one of the following methods:
1. Upload a Sample File
- Users can upload a file containing actual data.
- Supported formats: CSV, XLSX, TSV, JSON, Parquet.
- The system will extract and apply the schema from the file.

2. Upload a JSON File
- Users can provide a JSON file containing the schema definition.
- This is useful for predefined schemas that need to be reused across multiple datasets.
- The schema structure should match the required format for seamless integration.
Example of a JSON file structure
[
{
"columnName": "<Column_Name_1>",
"columnType": "<Integer | Double | Boolean | Varchar(MAX) | Varchar(200) | Varchar / String | Date Time | Date>",
"description": "<String>"
},
{
"columnName": "<Column_Name_2>",
"columnType": "<Integer | Double | Boolean | Varchar(MAX) | Varchar(200) | Varchar / String | Date Time | Date>",
"description": "<String>"
},
{
"columnName": "<Column_Name_n>",
"columnType": "<Integer | Double | Boolean | Varchar(MAX) | Varchar(200) | Varchar / String | Date Time | Date>",
"description": "<String>"
}
]

3. Manually Define the Schema
- Users can enter schema fields manually via the interface.
- This option allows full control over defining column names, data types, and constraints.
- Ideal for custom datasets where schema files are unavailable.

Schema Publishing
The Schema Extraction page provides comprehensive schema management capabilities, allowing users to:
- Add New Fields: Insert additional columns to the schema as needed
- Remove Fields: Delete unnecessary or redundant columns
- Modify Column Metadata:
-
Update "Column Name" to better reflect the data content
-
Change "Column Type" to ensure proper data representation
-
Edit column descriptions to provide detailed documentation

-
Key Schema Guidelines
- Column names must start with a letter and may contain alphanumeric characters and underscores.
- Different target locations support varying data types. Always verify data type compatibility with user's target storage system.
Users can also custom partition the data. Please check the documentation on Dataset Custom Partitioning.
Create Dataset with Schema in a Single Step (API Only)
Users can create and register the schema of a dataset in a single API call by adding the schema information to the request body.
When using this approach, it's important to be aware of the following schema considerations:
- Schema Validation: The schema will be validated against the dataset's file format and content
- Data Type Compatibility: Ensure column types match the actual data in the dataset
- Column Naming: Follow naming conventions (alphanumeric with underscores, starting with a letter)
- Required Fields: At minimum, each column must have a name and type specified
In the event of a schema registration failure, the dataset creation process will complete successfully, while the schema registration will be marked as pending. This design ensures dataset availability while allowing for subsequent schema registration attempts. Users can retry the schema registration process at any time through either the user interface or API endpoints.
API Request Payload Details
API Endpoint: /datasets
HTTP Method: POST
Request Body Structure:
{
"DatasetName": "TestDatasetName",
"DatasetDescription": "",
"Domain": "TestDomainName",
"DatasourceType": "api",
"IsDataValidationEnabled": true,
"SerDe": "OpenCSVSerde",
"FileDelimiter": ",",
"FileType": "csv",
"IsDataCleanupEnabled": false,
"IsDataProfilingEnabled": false,
"LifeCyclePolicyStatus": "Disabled",
"TargetLocation": "s3athena",
"MalwareDetectionOptions": {
"ScanForMalware": true,
"AllowUnscannableFiles": false
},
"SkipFileHeader": true,
"SkipLZProcess": false,
"TableUpdate": "append",
"DataMetricsCollectionOptions": {
"IsMetricsCollectionEnabled": false
},
"IcebergTableOptions": {
"IsIcebergTable": false,
"TableProperties": []
},
"DatasetSchema": [
{
"name": "FirstName",
"type": "varchar(256)",
"description": ""
},
{
"name": "LastName",
"type": "varchar(256)",
"description": ""
},
{
"name": "Address",
"type": "varchar(256)",
"description": ""
}
],
"PartitionKeys": [
{
"rank": 1,
"name": "partition1",
"type": "varchar(256)"
}
]
}
Along with the schema, add other required parameters, for example: SortType in case of a redshift dataset
View Dataset

The details page provides comprehensive insights into dataset properties and operations. When users click on a dataset, they can access the following key sections:
- Overview: Displays essential metadata including dataset name, location, domain, file type, and advanced configuration options
- Files: Manages file uploads, downloads, and deletions; enables ML model applications and result viewing
- Profile: Shows connection details (JDBC, Host, ODBC) and schema information for data warehouse targets
- Lineage: Visualizes data flow and dependencies between datasets and processes
- Resources: Lists associated assets and access permissions
- Data Quality Check: Provides validation metrics and quality assessment reports
- Schema Details: Presents the complete dataset schema with column names, data types, and descriptions (For View type datasets)
- Versions: Tracks historical versions and changes to view definitions (For standard type view type datasets)
The interface serves as a centralized hub for all dataset-related operations and insights, supporting effective data management and utilization across the platform.
Overview
The Overview tab provides comprehensive details about the dataset, including essential metadata and configuration parameters. It displays key information such as the Dataset Name, Dataset S3 Location, Target Location, Domain, and File Type. The tab also includes advanced dataset attributes such as File Options and Advanced Options. Users can also view the activity logs of the dataset, which provide information about dataset creation, updates, and other related activities.

Files
Users can manually upload files to the dataset if the connection type is 'File Upload' (default). The Files tab allows users to:
- Upload files to the dataset.
- View file details.
- Delete files.
- Restore files.
- Download files.
- Apply machine learning models.
- View AI/ML results.

For additional details, please refer to the Dataset Files documentation.
Invocations & Results
When a machine learning model is applied to a dataset, the process generates outputs known as invocations and results, applicable to both structured and unstructured data types. Users have the capability to download detailed logs for each invocation to analyze the model's performance and outcomes. In scenarios where no ML model has been applied, interacting with the "Invocations and Results" button will prompt a display message indicating "No invocations found for this file."
Apply ML

Users can apply Machine Learning models to files in the dataset. After selecting the "Apply ML" option, user can select the model and instance type from the dropdowns.
If the selected type is ML Model, then users need to provide the following details:
- ML Model: Dropdown shows ML model names users have access to.
- Instance Type: Dropdown shows machine types users want to apply model on.
- Target Dataset: Dropdown shows Amorphic datasets users want to write output to.
View AI/ML Results
The "View AI/ML Results" option in the File Operation shows users the AI/ML results applied to ML models.

View More Details
When files are added to the dataset via an S3 connection, View More Details provides the location of the file on the source, for example, the source object key.
The source metadata of the file can only be seen for data loaded via an S3 connection of version 1.0 or higher (e.g., new or upgraded connections). Due to S3 limitations, this metadata will not be available for files larger than 5 GB.
File Search
To activate file search functionality, navigate to the Administration section, select OS Management, and then choose Reindex Opensearch Index with the file indexing option enabled.

For datasets containing non-analytic file types, the File Search tab offers a robust search functionality to explore file metadata. Within this tab, a user-friendly Search bar is provided to streamline the search process. Upon conducting a search, the system will display files that match the search criteria, accompanied by several actionable options:
Searchable Attributes:
- 'DatasetId': Unique identifier for the dataset
- 'FileName': Name of the file
Universal Search: Typing "*" in the search bar will display all files associated with a particular dataset.
Example Search Queries:
*: Fetches every file within the datasetFileName:\*samplefile\*: Retrieves files whose names includesamplefileFileName:"samplefile.csv": Specifically finds a file namedsamplefile.csv

- File Preview: Users can preview the file. Supported file formats are txt, json, docx, pdf, mp3, wav, fla, m4a, mp4, webm, flv, ogg, mov, html, htm, jpg, jpeg, bmp, gif, ico, svg, png, csv, tsv.
- Complete Analytics: Users can view the complete analytics of the files for S3 AI-enabled datasets.
- File Download: Users can download the file.
Profile
The Profile tab prominently features the dataset schema, especially when linked to a Data Warehouse such as Redshift. This section allows users to thoroughly examine the schema details, enhancing their understanding of the dataset's structure.
Additionally, when data profiling is activated, this tab provides a comprehensive display of profiling metrics and insights. These details help in assessing the quality and characteristics of the data within the dataset. For more in-depth information on data profiling capabilities, refer to the Data Profiling documentation.
Following the schema and profiling insights, the Profile tab also offers crucial connectivity details, including JDBC, Host, and ODBC connection specifics. These connection details are essential for integrating various data sources with the Amorphic platform, thereby enabling seamless data interactions.

-
Establishing a JDBC connection through a data source or a BI tool grants access to all tables within the specified database. It displays schema definitions but not the actual data, covering both system and user-owned tables (datasets).
-
When establishing JDBC connections through BI tools or data sources, the platform displays both system tables and user-owned datasets, enabling comprehensive data exploration while maintaining data security.
For in-depth information on data profiling capabilities and metrics, refer to the Data Profiling documentation.
Lineage
The Lineage tab provides a comprehensive view of data flow and dependencies within your datasets. This feature helps you understand:
- Data Flow Visualization: Interactive diagram showing how data moves between datasets, jobs, and datasources.
- Upstream Dependencies: View all sources that feed into your dataset
- Downstream Dependencies: See where your dataset's data is being used
- Impact Analysis: Assess the potential impact of changes to your dataset
- Understand Column Level Lineage: Track how individual columns are transformed and mapped across datasets
- View Lineage History: Access historical lineage information to understand how data relationships have evolved over time

Resources
Explore the complete range of resource dependencies associated with the dataset, including Jobs, Datalabs, and View Type Datasets, among others.

- Users should detach or delete all dependent resources before deleting the dataset.
- For standard view type datasets created in Redshift, if view type datasets are established using the "WITH NO SCHEMA BINDING" option, the originating dataset will not recognize these view type datasets as dependencies.
SQL statement for creating view with no schema binding
Create view DomainName.ViewName as select * from DomainName.DatasetName WITH NO SCHEMA BINDING
Here, the view is not considered a dependent view of the dataset. However, if the dataset is deleted, the view cannot be queried.
Share Dataset Access
Sharing dataset access in Amorphic is designed to be a straightforward process, allowing dataset owners or users with appropriate permissions to manage access efficiently. Below is an overview of how to share dataset access:
- Access Management Panel: Navigate to the dataset intended for sharing and click on the 'Share' icon. This action opens the access management panel.
- Add Tags: In the panel, users can add tags to the dataset.
- Set Access Type: Assign the appropriate access type (e.g., FullAccess, Editor, Read Only) to the tags.
- Review and Confirm: Review the settings to ensure the correct permissions are assigned to the appropriate users or tags. Confirm the changes to update the access settings.

- Selecting the
Provide Domain Accessoption automatically grants the necessary tenant or domain access in the background, along with access to the dataset. - Users with FullAccess or Editor permissions, allowing them to extend access to additional users or tags within the system.
Data Stewards
Data Stewards are designated users who have specialized responsibilities for managing and overseeing specific datasets within Amorphic. This feature enables organizations to implement proper data governance by assigning accountability and expertise to key personnel for critical datasets.
Assigning Data Stewards
Dataset owners and editors can assign Data Stewards through the dataset details page. Any user who has owner or editor access to a dataset can be made its data steward.
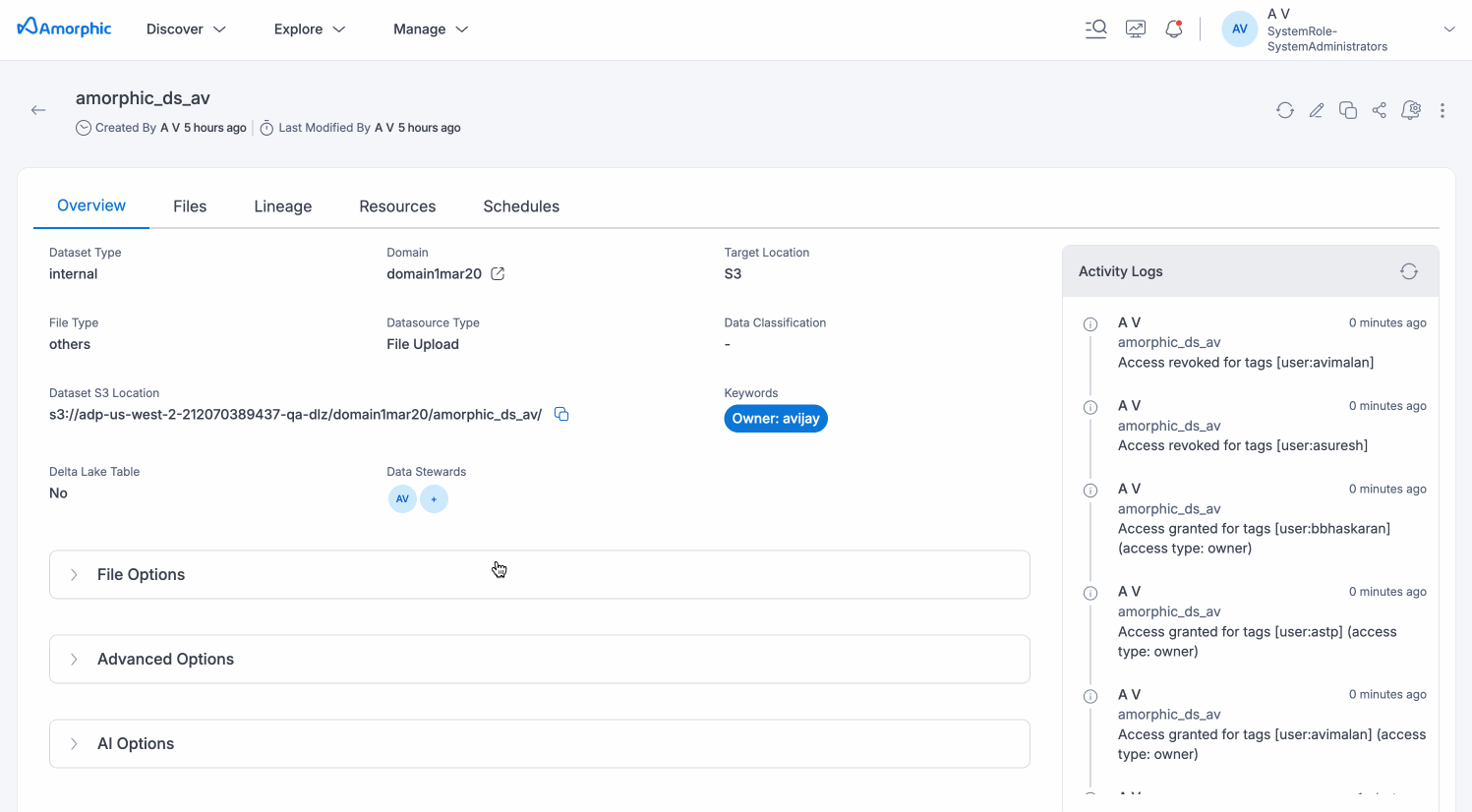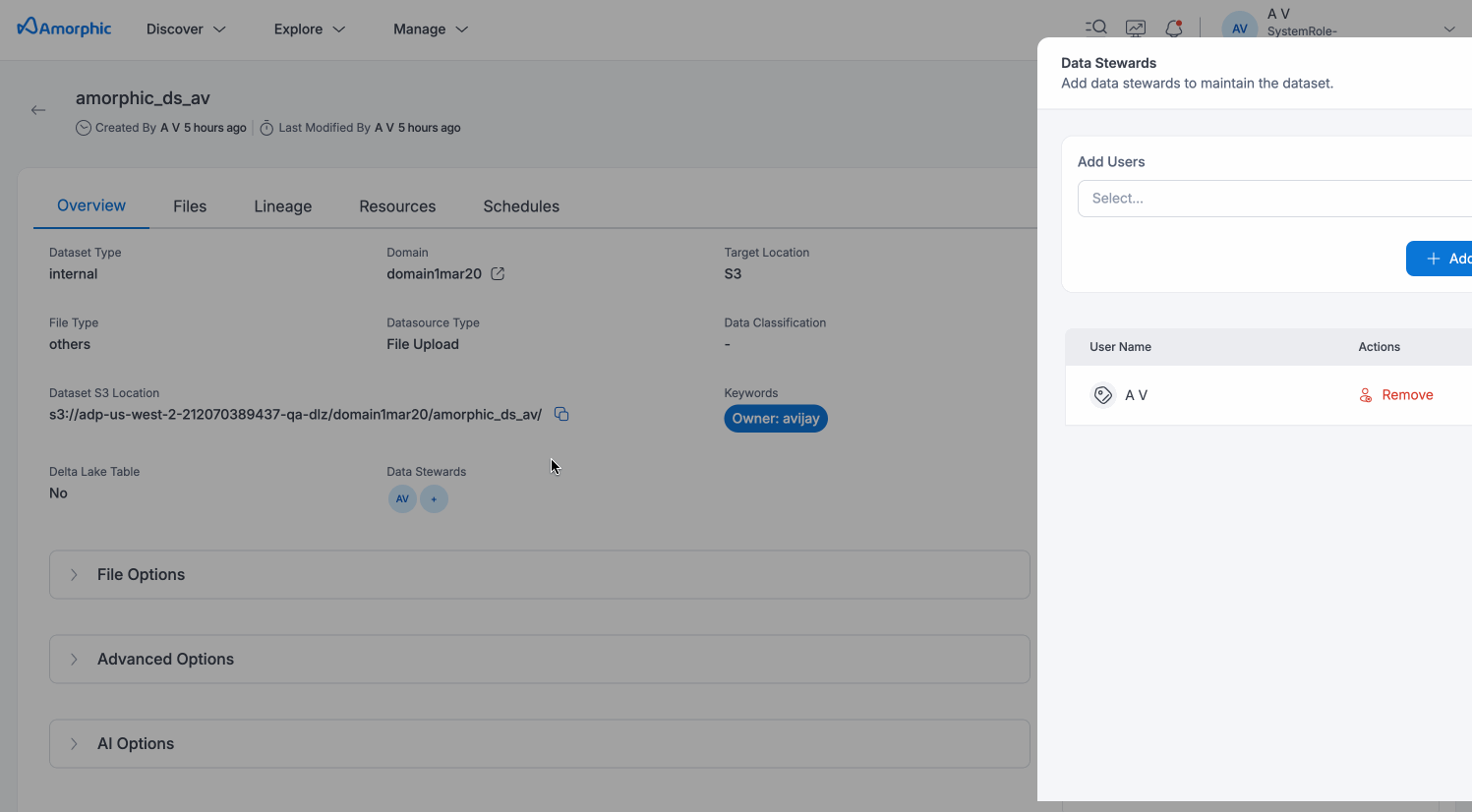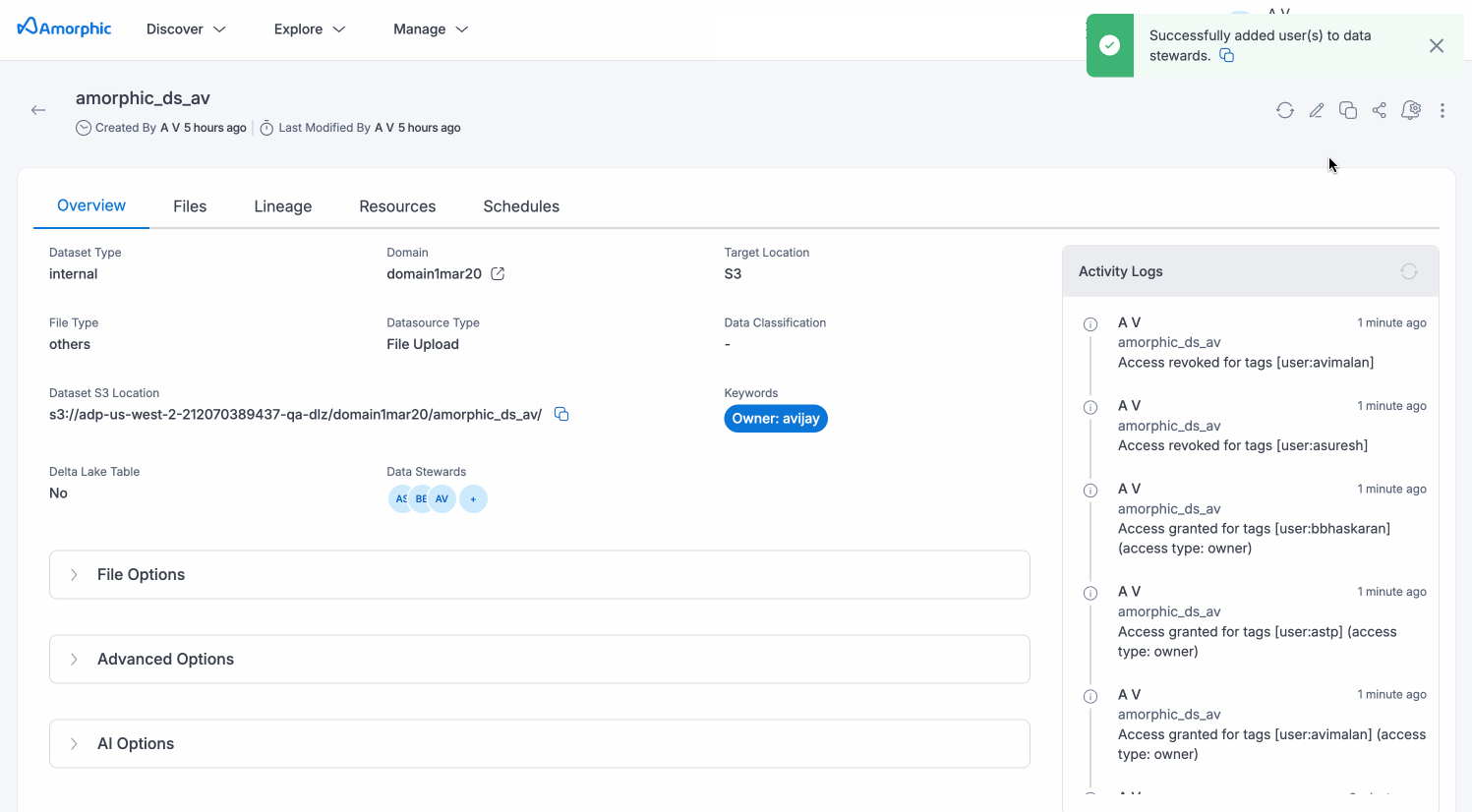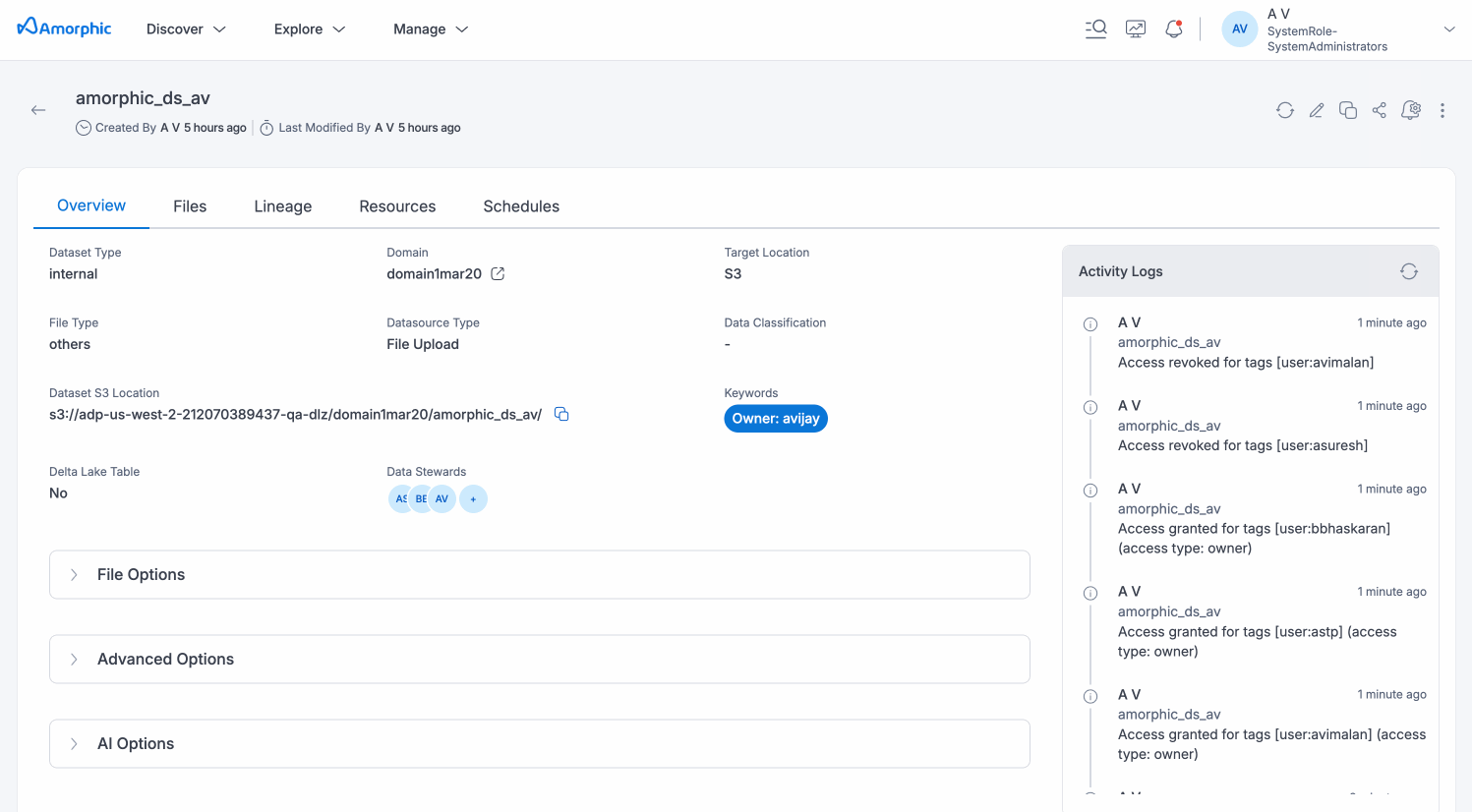
Edit Dataset
Amorphic provides the flexibility to edit datasets, allowing modifications to all fields that are relevant and editable for the specific type of dataset. The following GIF demonstrates how to edit a dataset:

Clone Dataset
Cloning a dataset in Amorphic is a streamlined process designed for ease and efficiency. Here's how users can do it:
- Auto-Population of Metadata: When users access the Clone Dataset page, it automatically fills in the fields with the metadata from the dataset users wish to clone.
- Modify Dataset Name: The only required change is the
Dataset Name. Ensure users provide a new name to distinguish the cloned dataset from the original. - Edit Additional Fields: Users have the flexibility to modify any other fields as necessary before finalizing the clone.

Delete Dataset
Users can instantly delete a dataset along with all associated metadata.

The deletion process operates asynchronously in the background.
Force delete for redshift dataset(API only)
If users attempt to delete a Redshift dataset and the operation fails, this may be due to dependent views that are not visible in the Amorphic user interface but exist within Redshift itself. In such cases, users can employ the 'force delete' option to proceed with the deletion.
The following GIF demonstrates how to force delete a Redshift dataset:

To use the force delete option, send a DELETE request to the following endpoint with the specified query parameter:
- Resource Path:
/datasets/id - HTTP Method: DELETE
- Query String Parameters:
force_delete=True
The force delete option should only be used when the dataset has no other dependencies visible in the Amorphic UI, except for those views that exist within Redshift.
For bulk deletion of datasets, please check the documentation on How to bulk delete the datasets in Amorphic
Repair Dataset(s)
Dataset issues can be addressed and documented through two distinct methods:
- Individual Repair/Report: To address issues with a specific dataset, navigate to the dataset details page and click the "Repair Dataset/Generate Report Dataset" button located in the top right corner. This option enables targeted troubleshooting and repair.
- Global Repair/Report: For addressing issues across multiple datasets, click the "Global Dataset Repair/Report" button in the top right corner of the dataset listing page. This method helps in identifying and resolving issues across all datasets simultaneously.
For comprehensive instructions on utilizing these features, please visit the How to Repair Dataset(s) in Amorphic page.