
Hudi Datasets
Introduction
Apache Hudi is an open-source data management framework that enables incremental data processing with ACID (Atomicity, Consistency, Isolation, and Durability) guarantees. In Amorphic, users can create Hudi datasets with LakeFormation as the target location, allowing efficient data storage and retrieval using Hudi tables.
This document provides a step-by-step guide on creating, managing, and querying Hudi datasets in Amorphic.
What is Apache Hudi?
Apache Hudi allows users to perform record-level insert, update, upsert, and delete operations efficiently. Upsert combines insert and update operations, reducing data processing overhead. To learn more, visit the Apache Hudi Documentation.
Amorphic Support for Hudi
Amorphic provides the following key features for Hudi datasets:
- ACID Transactions: Ensures consistency with atomic writes and snapshot isolation.
- Table Properties: Users can define properties like Hudi Write Operation Type.
- Insert, Update, and Delete Operations: Requires Apache Spark or custom ETL processes.
- Table Types:
- Copy on Write (CoW): Overwrites files when records are updated. Optimized for read-intensive workloads.
- Merge on Read (MoR): Stores changes separately before merging. Ideal for write-intensive workloads.
- Supported File Formats: CSV, JSON, Parquet.
Supported Hudi Query Types
| Table Type | Supported Query Type |
|---|---|
| Copy On Write | Snapshot - Retrieves the latest table snapshot as of a specific commit. |
| Merge On Read | Read-Optimized - Displays the most recent compacted data. |
For more details on Athena's Hudi support, visit the Athena Hudi Documentation.
Limitations
-
Applicable only to LakeFormation target location.
-
Unsupported Features:
- Data Validation
- Skip LZ (Validation) Process
- Malware Detection
- Data Profiling
- Data Cleanup
- Data Metrics Collection
- Life Cycle Policy
-
Schema and Partition Evolution: Not supported.
-
Restricted Table Properties: Only predefined key-value pairs are allowed.
Property Name Allowed Values hoodie.datasource.write.operation upsert, insert -
Unsupported Queries:
- Incremental Queries
- CTAS (Create Table As Select) or INSERT INTO
- MSCK REPAIR TABLE
- Direct insert, update, delete queries in Athena
For more details on limitations, visit Athena Hudi Documentation.
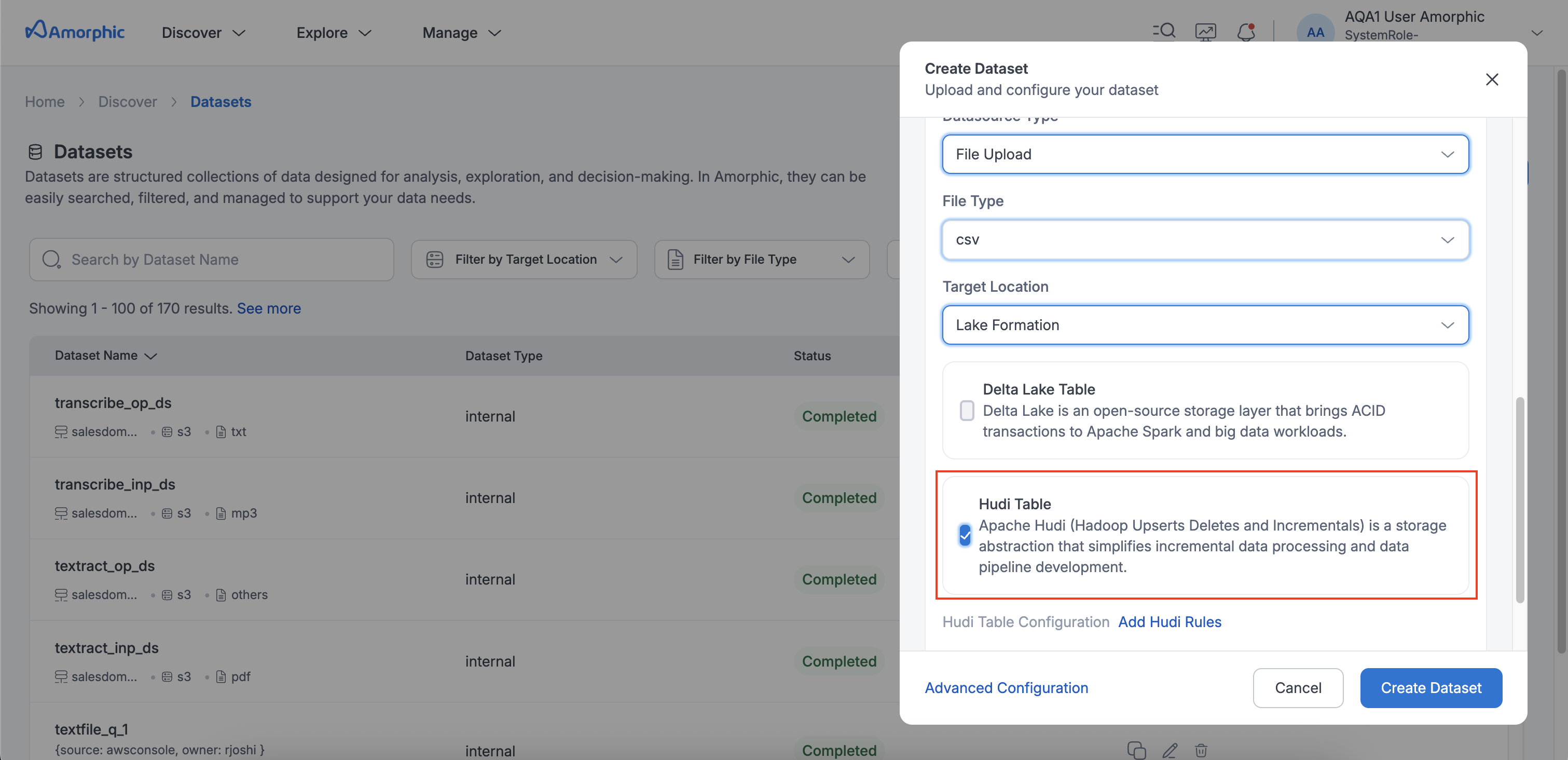
Creating Hudi Datasets in Amorphic
Dataset can be created by using either of the three ways:
- Using already defined Hudi Datasets Templates
- Importing required JSON payload
- Using the form and entering the required details
- Steps:
- Navigate to the Create Dataset section in Amorphic.
- Select LakeFormation as the target.
- Choose a file type: CSV, JSON, or Parquet.
- Enable Hudi Table and select an Update Method:
- Append: Adds data to an existing dataset.
- Overwrite: Replaces existing data with new data.
- Define Hudi table properties in the Hudi Table Properties section.
- Define the Schema.
- Configure dataset attributes:
- Storage Type: Copy on Write (CoW) or Merge on Read (MoR).
- Hudi Primary Key: Select a unique identifier column from the schema to serve as the primary key. For composite keys, choose multiple columns that together uniquely identify each record.
- Pre Combine Key: A column name from the schema, used to determine the latest update for a record.
- Partition Column Name: Users can select one or more columns to partition their data. The partitioning will follow the exact order of the columns users select, creating a hierarchical partition structure.
- Create the dataset.
- Steps:

Loading Data into Hudi Datasets
- Data upload follows Amorphic's Data Reloads process.
- Files enter a Pending State and users have to select and process pending files.
- Pending files can be deleted before processing.
- Restrictions:
- Cannot delete completed files.
- No Truncate Dataset, Download File, Apply ML or View AI/ML Results options.
Querying Hudi Datasets
Once data is loaded, users can query it via the Amorphic Playground.
Supported Commands:
- View Metadata:
DESCRIBE table_nameSHOW TBLPROPERTIES table_nameSHOW COLUMNS FROM table_name

AWS Hudi Merge on Read (MoR)
- MoR tables create two internal tables:
table_name_ro: Read-optimized view with compacted data.table_name_rt: Real-time view with all latest changes.
Compaction
- Non-Partitioned Tables: All Data exposed to read optimized queries is compacted automatically.
- Partitioned Tables: Requires manual compaction:
ALTER TABLE database_name.table_name
ADD PARTITION (partition_key = partition_value)
LOCATION 'location_path'
- By default, Hudi tables are stored in the DLZ bucket in the Amorphic account.
- Currently
table_name_roandtable_name_rtboth shows the latest data (checking with aws on the same) and to get only the compacted data, query thetable_namealone. - In the manual compaction process, location_path should be of the following format:
<DLZ_bucket>/<Domain>/<DatasetName>/<partitions_key=partition_value>/. - Inorder to access
table_name_roandtable_name_rtthrough playground, it is mandatory to assume user's IAM role.
Resource Sync Hudi Datasets to Amorphic from Cross-Account/ Cross-Region
Prerequisites
These steps must be performed directly in the AWS console for Hudi dataset resource syncing.
-
From Source Account (A):
- In LakeFormation, revoke IAM allowed principals from the appropriate database and table. If already revoked, skip this step.
- Grant at least Select permissions on the database and table to Account B.
- If Glue Catalog is encrypted, update KMS permissions for glue catalog encryption key to allow access for Account B (especially for admin and resource sync roles).
-
From Target Account (B):
- If using different organizational accounts, accept the shared resource in RAM (Resource Access Manager). If already accepted, skip this step.
- In LakeFormation (same region as Account A):
- Grant at least
Selectpermissions (including grantable permissions) to the resource sync Lambda role. - If granting access to tables, choose the database as
defaultwhile providing permissions (since shared tables will come under default database). - If the default database doesn't exist, create it and retry.
- Grant at least
- In LakeFormation (preferred region of Account B):
- Click "Create Resource Link", provide table name by choosing appropriate database (database you need to place this destined table).
- choose appropriate source region (Account A's region) and choose source table and databse name and grant permissions.
-
Update description to sync the resource back to Amorphic, update the description in Glue/LakeFormation as follows:
Request Description: { source: awsconsole, owner: owner-name, additionaloptions: { framework_type: hudi, source_account_region: region-name } } -
After updating the description, Trigger the resource sync scheduled backend job to complete synchronization.
-
Go Back to Source Account A and if glue catalog is encrypted, provide appropriate KMS permissions for glue catalog KMS key to other account for Hudi IAM Role.
- Hudi IAM role:
<project-short-name>-custom-CORSforHudiDatasets-Role
- Hudi IAM role:
-
After successful resource syncing, the synced Hudi dataset appears in the Amorphic UI and read operations can be performed via playground. views can also be created on top of this synced Hudi dataset.
- As part of this Hudi cross account/region resource sync, new Hudi IAM role with required policies will be created.
- Target account permissions are restricted to
read-onlyaccess, irrespective of the permissions granted. - While updating the Description,
source_account_regioncan be skipped if source and destination account regions are same. - User can only update the new Hudi IAM role in source account after triggering resource sync scheduled backend job or resource sync lambda directly.
- This new Hudi role will be assumed by datasets, views and athena queries inorder to access Hudi data from source account.
- Views cannot be created on multiple datasets if one is a cross-account/region synced Hudi dataset.
- No need to modify S3 bucket encryption or bucket policies as LakeFormation permissions override them.
- If a Hudi MoR table is synced, internal tables (
table_name_roandtable_name_rt) won't be accessible from target account unless explicitly shared.