
Workflows
What is an ER Workflow?
An ER (Entity Resolution) Workflow is a configurable process that performs entity resolution on input datasets to identify and merge duplicate records, ultimately generating a unified master dataset. A workflow orchestrates the entire entity resolution pipeline, from matching records across different sources to applying survivorship rules that determine which values to keep when merging records.
For example, a supplier matching workflow might take supplier records from procurement systems, finance systems, and ERP systems, match them based on business rules, and produce a single Unified Master Record for each unique supplier with the best available data from all sources.
How does an ER Workflow work?
MDM Workflows are responsible for performing entity resolution on the input datasets and ultimately generating the unified master dataset. The workflow process consists of four main stages:
-
Workflow Details: Define the workflow name, description, and entity mappings that link source datasets to their entity schemas.
-
Matching Technique: Configure how records are matched using either rule-based or machine learning-based matching, define matching rules with match keys, and specify output field configurations.
-
Survivorship Rules: Define strategies for selecting values when multiple source records are merged into a unified master record. This includes default governance strategies, source priorities, and attribute-specific rules.
-
Output Data: Configure where the resolved records are written—either to a new dataset or an existing Amorphic Gold Zone dataset.
Once configured, workflows can be run manually or automatically (depending on the processing cadence), and they process input records to identify matches, apply survivorship logic, and produce unified master records for stewardship and downstream use.
CSV input requirements
When using CSV files as workflow input:
- First row must be headers. The first row must contain the column names (schema headers). These headers are required for schema registration and attribute mapping.
- Use underscores, not spaces. In Amorphic Data Platform, column names that contain spaces are automatically converted to underscores during schema registration. Headers in your CSV should use underscores and match the schema defined in Amorphic. Using spaces (e.g.,
member id,full name) will not match the registered schema (e.g.,member_id,full_name), causing schema mapping or ingestion errors and workflow run failures.
Valid example (recommended):
member_id,full_name,patient_ref_id,policy_number,insurance_plan,effective_date,group_id
MEM-5001,mIchAEl thOrnTon mD,PID-1000,POL-99123,Premium Gold,2022-01-01,GRP-A1
Invalid example (causes schema mismatch and workflow failure):
member id,full name,patient ref id,policy number,insurance plan,effective date,group id
MEM-5001,mIchAEl thOrnTon mD,PID-1000,POL-99123,Premium Gold,2022-01-01,GRP-A1
File formats and casing
Use supported input file formats (e.g., CSV) and consistent casing for column headers. Header names are case-sensitive for schema mapping—use the same casing as in your Amorphic entity schema to avoid mapping errors.
How to create an ER Workflow
Rule-based workflow
Ml matching based workflow
Follow these steps to create an ER Workflow:
Step 1: Workflow Details
-
Enter Workflow Name: Provide a unique, descriptive name for your workflow (e.g.,
supplier_matching_workflow,customer_data_reconciliation). Use a naming convention that indicates the purpose or domain so workflows are easy to identify and manage. The workflow name can only contain upper(A-Z) and lowercase(a-z) letters, numbers(0-9), hyphens(-), and underscores(_). The Workflow name must be between 1-255 characters. -
Add Description (Optional): Optionally provide a description that explains the purpose or scope of this workflow. For example, "Primary workflow for matching supplier records from procurement and finance systems." The description can have 1-255 characters.
-
Add Entity Mapping: Add entities that link a source dataset to its entity schema for matching. You can select multiple entities, and each entity represents a mapping between a dataset and the entity structure that will be used for matching.
- Select one or more entities from the available list
- Each entity mapping connects a source dataset to its corresponding entity schema
- You can add multiple entities to process data from different sources in a single workflow
NoteRequired attribute types for ML matching workflows
While selectig a schema mapping for an ML–based matching workflow, the souce dataset must contain at least one of the columns mentioned below mapped to it's appropriate Attribute Type in the Schema Mapping.
- Any name related column mapped to attribute type FULL_NAME. OR
- Any phone number related column mapped to attribute type FULL_PHONE. OR
- Any email address related column mapped to attribute type EMAIL. OR
- Any address related column mapped to attribute type FULL_ADDRESS. OR
- Any Date of Birth related column mapped to attribute type DATE and match key as Date of Birth.
Step 2: Matching Technique
Configure how your data will be matched and processed:
Matching Method
-
Resolution Type: Choose how you want your data to be matched:
- Rule-based matching: Use customized rules to find exact matches. Suitable when you have clear business rules for matching records.
- Machine learning-based matching: Use machine learning models to help find a broader range of matches. Suitable when you need to identify matches that may not be exact but are likely the same entity.
-
Rule Type (Required for Rule-based matching): Choose the complexity level of your matching rules.
- Simple: Suitable for exact matching and schema mappings with multiple data columns mapped to the same input types. Use this when you need straightforward matching logic.
- Advanced: Suitable for fuzzy matching, exact matching, and schema mappings with data columns mapped one-to-one with input types. Use this when you need complex rule conditions with operators like
Exact(),Fuzzy(), and logical operators (AND,OR).
The current version of the application supports only Simple rule type.
-
Processing Cadence: Determine how often to run your matching workflow job:
- Manual: Your matching workflow job is run on demand. Useful for bulk processing when you want full control over when the workflow executes.
- Incremental Processing: Your matching workflow job is run on incremental demand. Useful for bulk processing of new or updated records.
- Automatic/Full Processing: Your matching workflow job is run automatically when you add or update your data inputs. Useful for incremental updates. This option is available only for rule-based matching.
-
Normalize Data (Optional): Check this option to normalize data values before matching. This is recommended for better accuracy, as it standardizes formats, removes extra spaces, and handles case variations.
Normalization is supported only for NAME, ADDRESS, PHONE, and EMAIL_ADDRESS. To normalize related attributes, assign them to the corresponding groupName in your entity schema:
- NAME: Assign
NAME_FIRST,NAME_MIDDLE, andNAME_LASTto the NAME groupName. - ADDRESS: Assign
ADDRESS_STREET1,ADDRESS_STREET2,ADDRESS_STREET3,ADDRESS_CITY,ADDRESS_STATE,ADDRESS_COUNTRY, andADDRESS_POSTALCODEto the ADDRESS groupName. - PHONE: Assign
PHONE_NUMBERandPHONE_COUNTRYCODEto the PHONE groupName.
- NAME: Assign
-
Attribute Matching: Choose how records can be matched:
- One-to-One: Each record can only match with one other record. Use this when you expect a single match per record.
- Many-to-Many: Records can match with multiple other records. Use this when a single record might legitimately match with multiple records.
-
Comparison Type (For Simple Rule Type): Choose how to compare similar data stored in different input fields:
- Single Input Field: Limit comparison within a single input field, when similar data stored across multiple input fields should not be matched.
- Multiple Input Fields: Find any combination of matches across data stored in multiple input fields, regardless of whether the data is in the same or different input field.
Matching Rules�
Define match criteria by creating matching rules. You can create up to 15 rules for Simple rule type, or up to 25 rules for Advanced rule type.
-
Rule Name: Provide a descriptive name for each rule, such as
exact_tax_match,duns_match, orfuzzy_name_match. -
Match Keys (For Simple Rule Type): Select the match keys that define the matching criteria for this rule. Match keys are attributes that have been configured in your entity schema. You can select multiple match keys, and records will match if they satisfy the criteria for all selected keys.
- For example, you might select "Address" and "Email Address" as match keys
- Each rule must have a unique set of match keys
- You can add or remove match keys using the dropdown
-
Rule Condition (For Advanced Rule Type): Define the rule condition using a syntax that supports functions and logical operators:
- Use
Exact(field_name)for exact matching - Use
Fuzzy(field_name, threshold)for fuzzy matching with a similarity threshold (e.g.,Fuzzy(supplier_name, 0.85)) - Combine conditions with
ANDandORoperators - Example:
Exact(tax_id)orFuzzy(supplier_name, 0.85) AND Exact(country)
- Use
-
Rule Priority: Rules are evaluated in priority order from top to bottom. Use the up/down arrows or drag handles to reorder rules. Higher priority rules are evaluated first.
-
Add or Remove Rules:
- Click "+ Add Another Rule" to create additional matching rules
- Click "Remove" to delete a rule
- Click "Reset rule" to clear the current rule configuration
Each rule must have a unique set of match keys (for Simple rule type) or a unique rule condition (for Advanced rule type). The system will validate this and display an error if duplicate rules are detected.
- Do not use Unique Id as a match key. Matching on unique identifiers is not supported and can lead to incorrect behavior.
- Rule-based matching only: The attribute types IPV4, IPV6, and MAID are not supported for rule-based matching. Use machine learning–based matching if you need to match on these types.
Data Output
Configure which fields appear in your output:
-
Search Entities: Use the search field to filter and find specific entities or fields.
-
Output Fields: All fields appear in your output by default. For each field, you can:
- Include: The field will be included in the output (default state)
- Hide: Exclude the field from the output
- Hash: Mask sensitive data by hashing the field values
Step 3: Survivorship Rules
When multiple source records are merged into a unified master record, survivorship rules determine which value wins for each attribute.
Default Governance Strategy
Set the fallback strategy when no attribute-specific rule is defined:
-
Frequency: Use the most frequently occurring value across sources. This strategy selects the value that appears most often across all matched records.
-
Source System: Use the value from the highest priority source based on the configured source priority order. This strategy relies on the source priority configuration.
-
Aggregation: Record with aggregate values from all sources depending on data type. Use when you want to combine or prefer the most complete record.
Default Source Priority
Configure the default precedence order for resolving conflicts when using Source System strategy:
-
Source List: View all data sources that are part of your entity mappings.
-
Reorder Sources: Drag to reorder or use the up/down arrows to set priority. Higher priority sources (lower numbers) are preferred when using 'Source Priority' strategy.
-
Source Information: Each source displays:
- Source name and dataset name
- Record count
- Current priority number
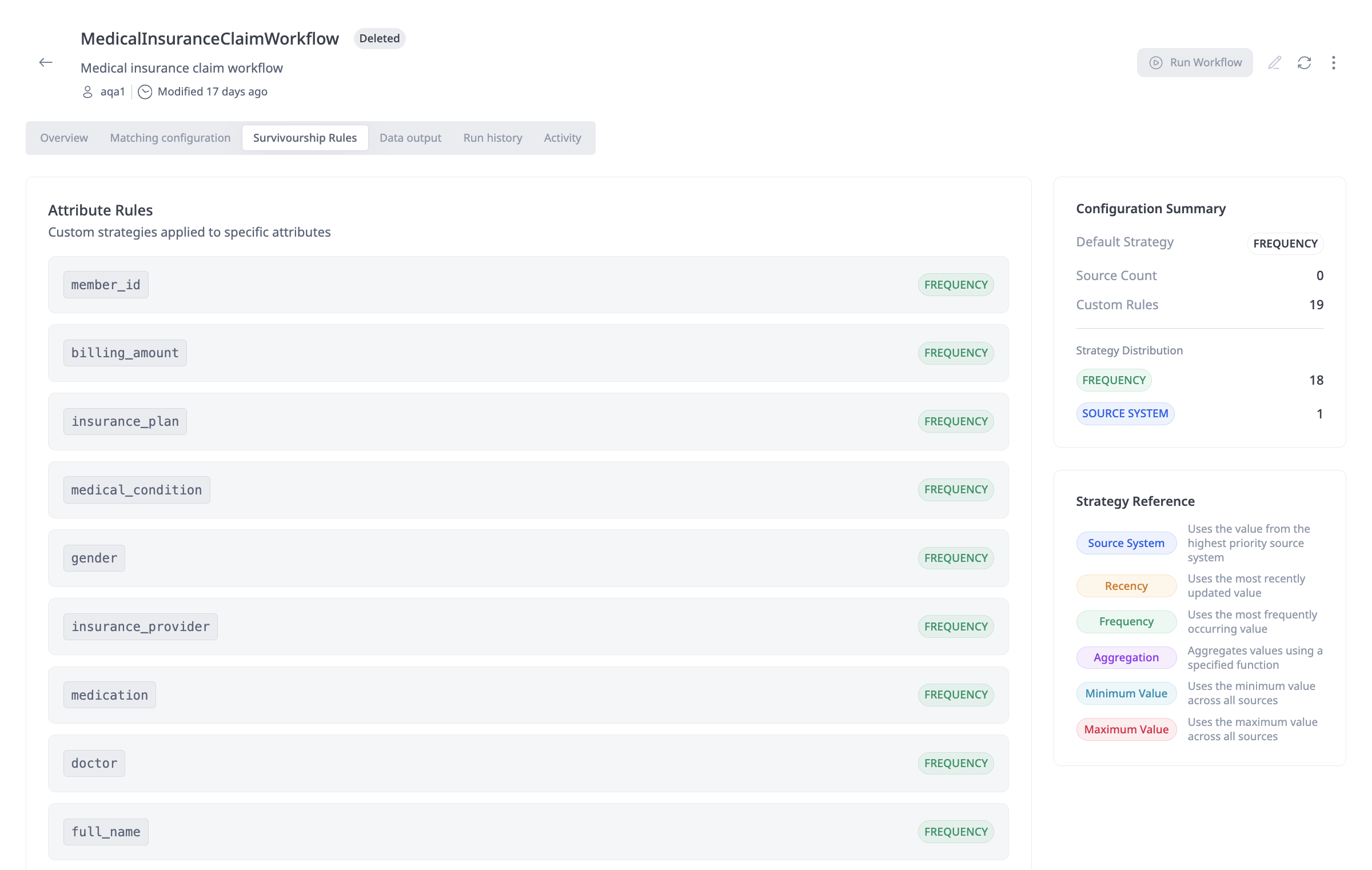
Attribute Rules
Override the default strategy for specific attributes:
-
Attribute List: View all attributes from your entity schema that will be included in the unified master record.
-
Assign Strategy: For each attribute, select a survivorship strategy:
- Source Priority: Use value from highest priority source
- Frequency: Use most frequently occurring value
- Most Recent/Recency: Use most recently updated value
- Aggregation: Aggregate values from all sources
- Minimum Value: Use the minimum value across sources
- Maximum Value: Use the maximum value across sources
-
Set Attribute Priority: For attributes using "Source Priority" strategy, you can set a custom source priority order. Check "Set this priority for all 'Source Priority' fields" to apply the same priority order to all Source Priority attributes.
The strategy you choose as Default Governance Strategy is used as the prefilled value for all attribute-level rules. You can override the strategy for individual attributes as needed.
Strategy Reference
The following survivorship strategies are available:
| Strategy | Description |
|---|---|
| Source System/Source Priority | Uses configured source rank order. The value from the highest priority source is selected. |
| Most Recent/Recency | Value from most recently updated record. The system uses the record's last update timestamp. |
| Frequency | Use most frequently occurring value across all matched records. |
| Aggregation | Record with most populated fields, or aggregate values from all sources depending on data type. |
| Minimum Value | Use the minimum value across sources. Applicable to numeric and date fields. |
| Maximum Value | Use the maximum value across sources. Applicable to numeric and date fields. |
Confidence Thresholds (Only for ML Matching based workflows)
Configure automatic processing thresholds:
-
Automatically Process Records: Set a confidence threshold (e.g., 95%+) for records that will be automatically processed without manual review.
-
Records Requiring Review: Set a threshold (e.g., below 94%) for records that require manual review before being included in the unified master dataset.
Step 4: Output Data
Configure where the resolved records are written:
Output Destination
-
Create New Dataset: Create a new dataset in the Amorphic Gold Zone for resolved records.
- Domain Name: Enter the domain name for the new dataset (e.g.,
SupplierData,CustomerRecords) - Dataset Name: Enter a unique dataset name (e.g.,
gold_suppliers,customer_unified_master_records) - Description: Optionally provide a description explaining the purpose of this dataset
- Target Location: Select the storage location (e.g.,
DynamoDB,S3)
- Domain Name: Enter the domain name for the new dataset (e.g.,
-
Write to Existing Dataset: Append or update records in an existing Amorphic Gold Zone dataset.
- Domain Name: Select the domain from the dropdown
- Dataset Name: Select the existing dataset from the dropdown
- Validate Dataset: Click to validate that the selected dataset exists and is accessible
When using a pre-created Amorphic DynamoDB dataset as the target dataset, ensure that the PartitionKey is set to GoldenId. See DynamoDB Datasets for creating and configuring DynamoDB datasets.
Do not use the same output dataset for multiple workflows. Metrics and review items are read from the output DynamoDB table. If two workflows write to the same dataset, review items and metrics from one workflow can appear for the other, which is misleading. Use a dedicated output dataset for each workflow.
Workflow Overview
The workflow overview displays a visual representation of your workflow:
- Input: Shows the number of datasets that will be processed
- Engine: Entity Resolution engine that performs the matching and survivorship
- Output: The Gold dataset where resolved records are written
Completing Workflow Creation
Once all four steps are completed:
- Review your configuration in the workflow overview
- Click "Create Workflow" to save and create the workflow
- The workflow will be created with "Active" status and can be run immediately
- Click "Cancel" at any time to discard your changes
After creating a workflow, you can edit it at any time. However, changes to certain configurations (like entity mappings) may require re-running the workflow to take effect.
Data Engineers and Admins can create, edit, and run workflows. Data Stewards and App Viewers can only view workflows.
How to run an ER Workflow
You can run an ER Workflow in several ways depending on the configured processing cadence:
Manual Execution
For workflows with Manual or Incremental Processing cadence:
- Navigate to the Workflows page
- Find the workflow you want to run in the workflows list
- Click the Play icon in the Actions column, or
- Open the workflow details page and click the "Run Workflow" button
- The workflow will start executing and you can monitor its progress in the Run history tab
Automatic Execution
For workflows with Automatic/Full Processing cadence:
- The workflow runs automatically when you add or update data inputs
- No manual intervention is required
- Execution is triggered by data changes in the source datasets
Monitoring Workflow Execution
-
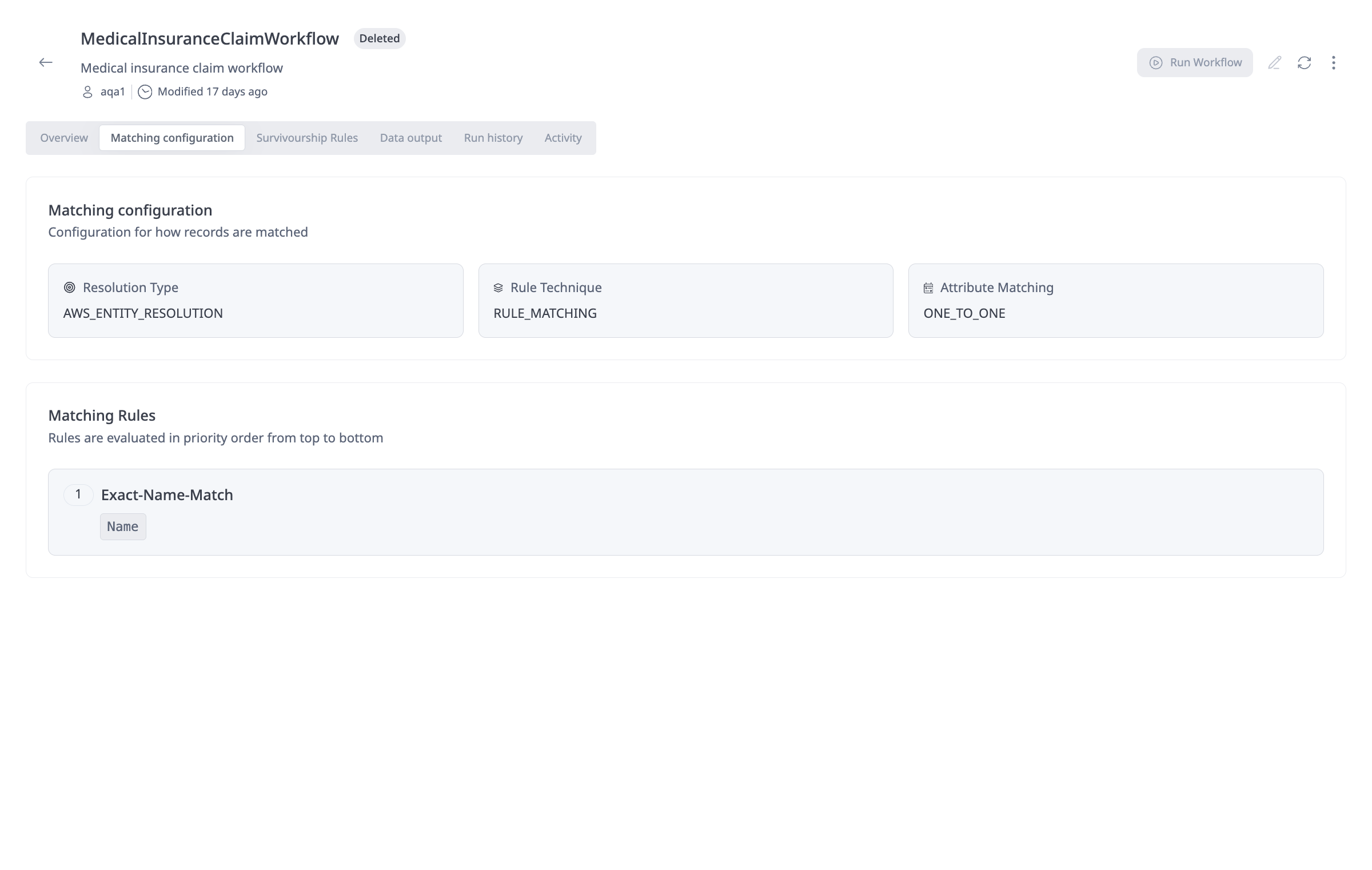
Matching configuration: On the workflow details page, the Matching configuration tab shows how the workflow is set up for matching:
-
Resolution Engine, Resolution Type and Attribute Matching: The first part displays the Resolution Type (e.g., AWS Entity Resolution), Rule Technique (rule-based matching or ml-based matching) that are used to match records and Attribute Matching (One-to-One or Many-to-Many).
-
Matching rules: The second part lists the Matching Rules that are evaluated in priority order from top to bottom. For each rule you can see the rule name and which match keys (e.g., Email, Address) are used for that rule.
-
-
Survivorship rules: The Survivorship Rules tab on the workflow details page shows how values for each attribute will be chosen after matching when multiple source records are merged into a unified master record. Attribute Rules list each attribute (e.g.,
first_name,city,email,surname) and the survivorship strategy applied to it (e.g., FREQUENCY—use the most frequently occurring value). This is where you can see or adjust which strategy is used per attribute.
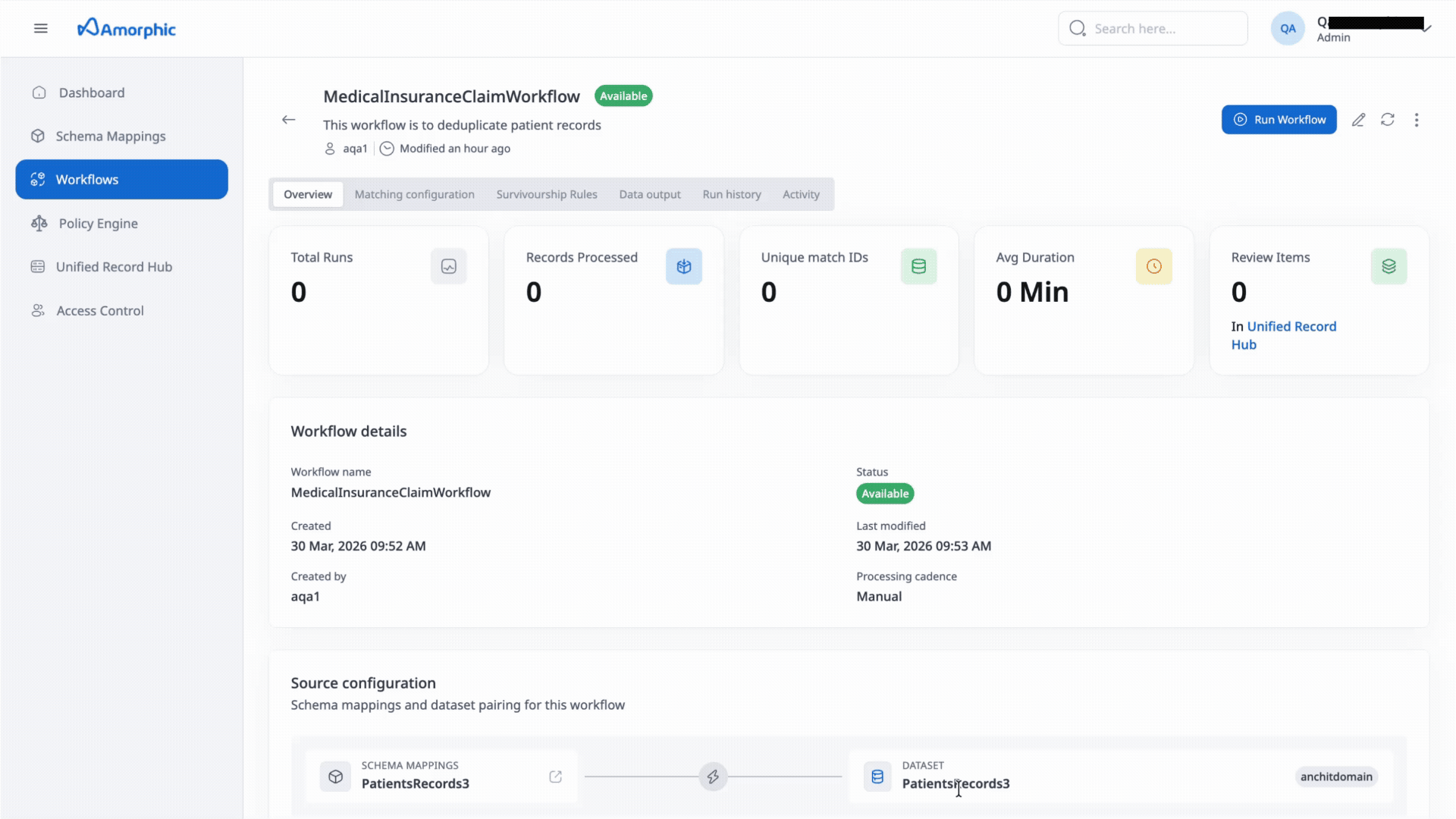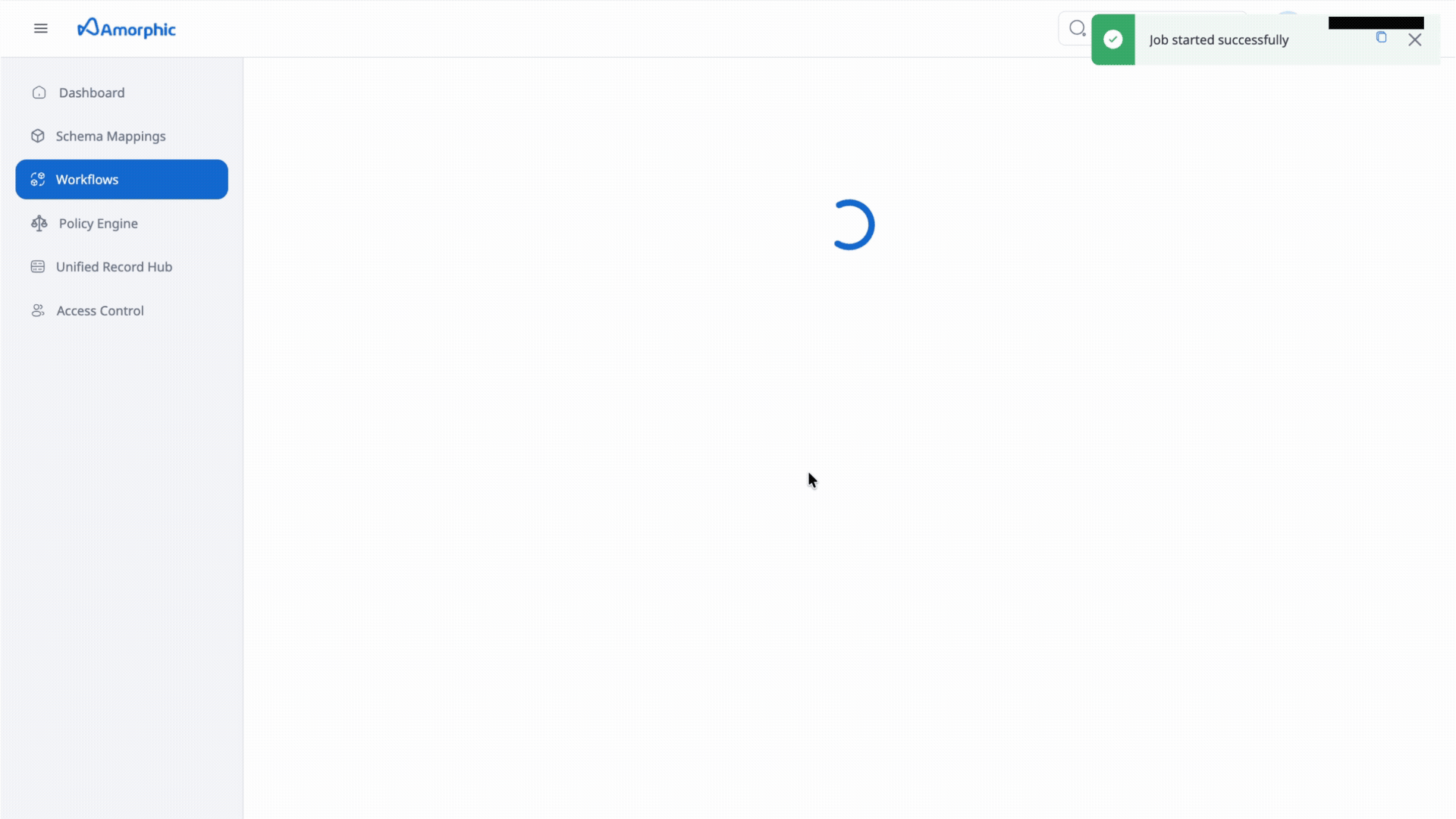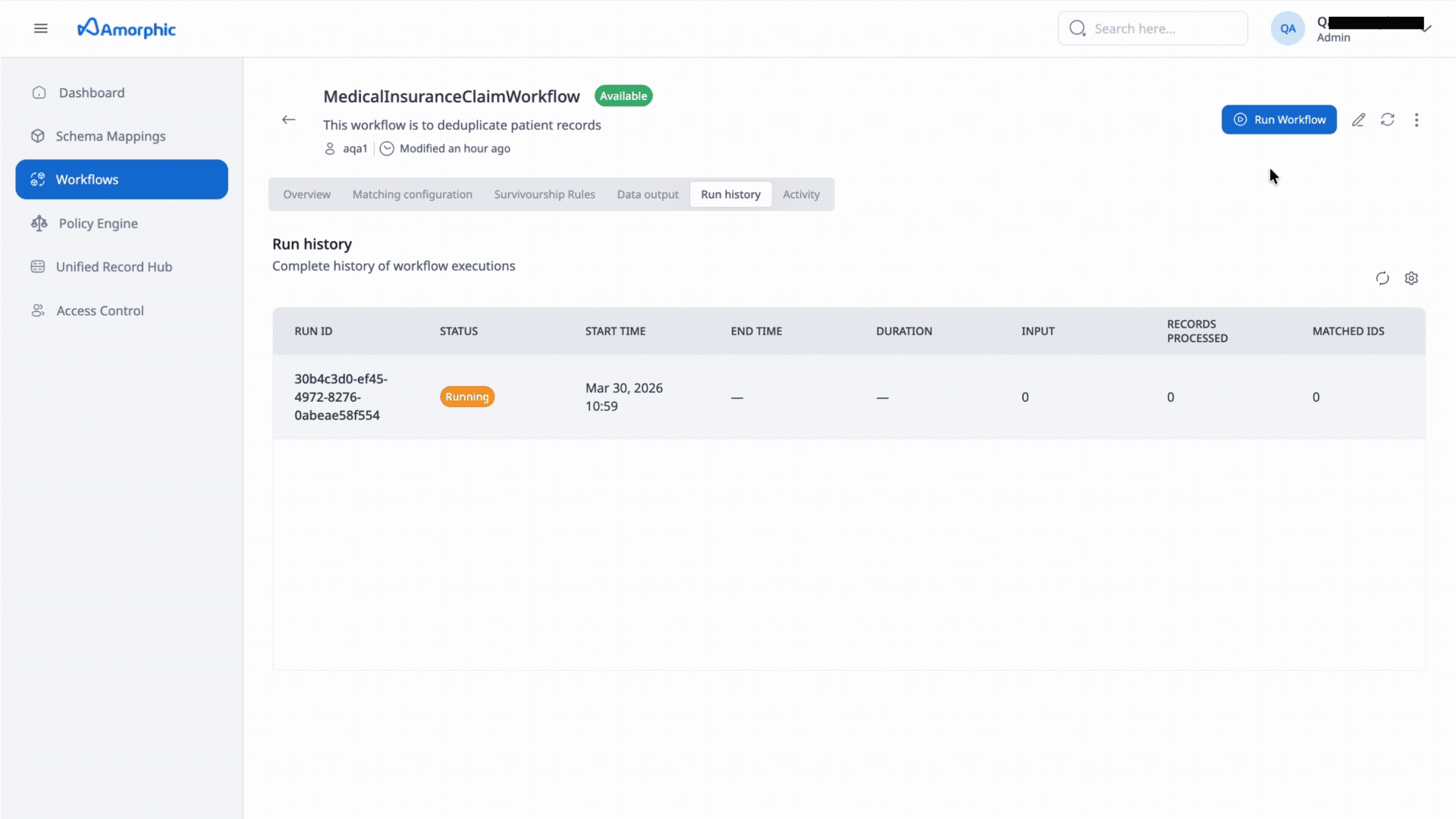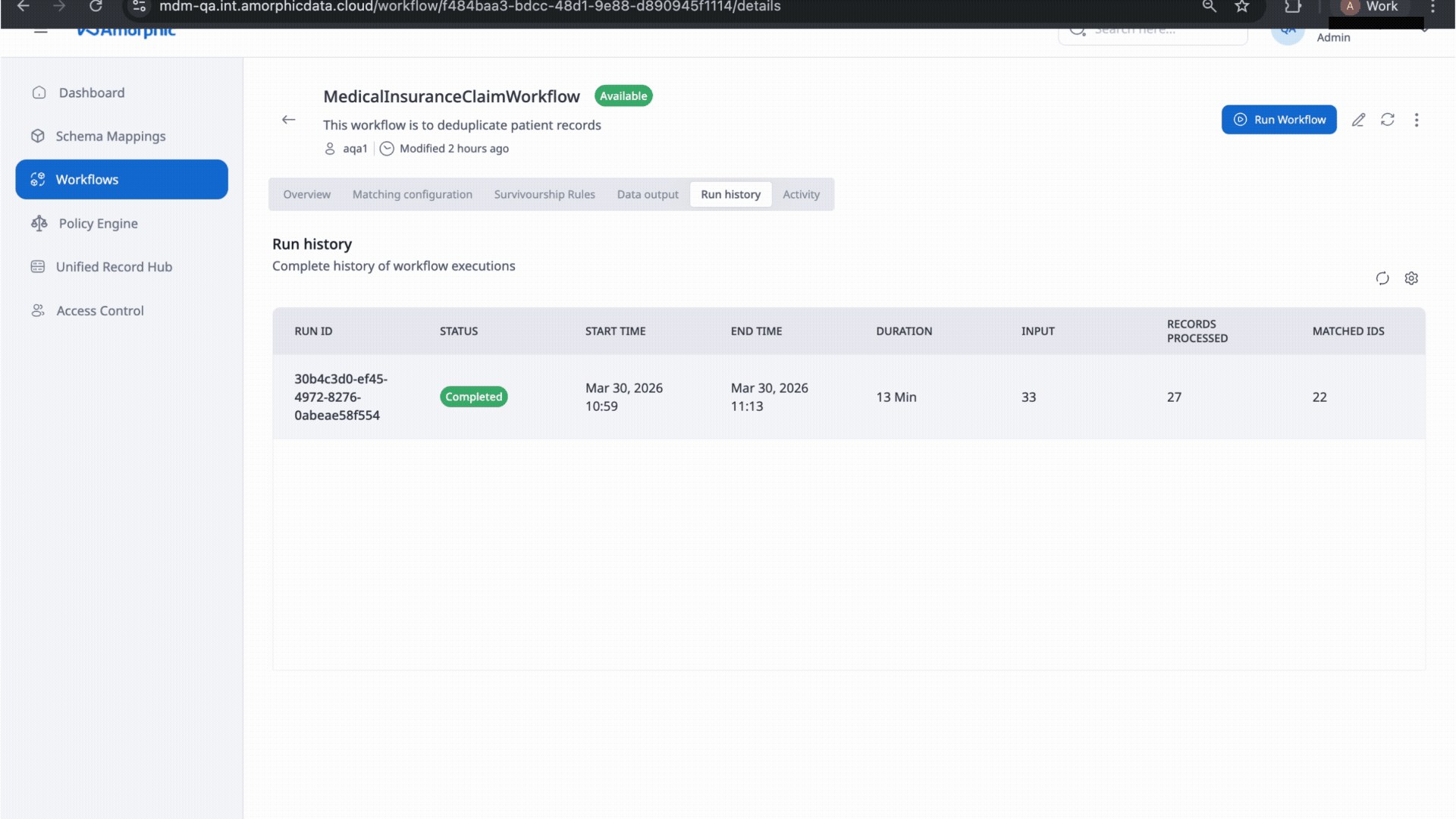
- Run History Tab: View the complete history of workflow executions:
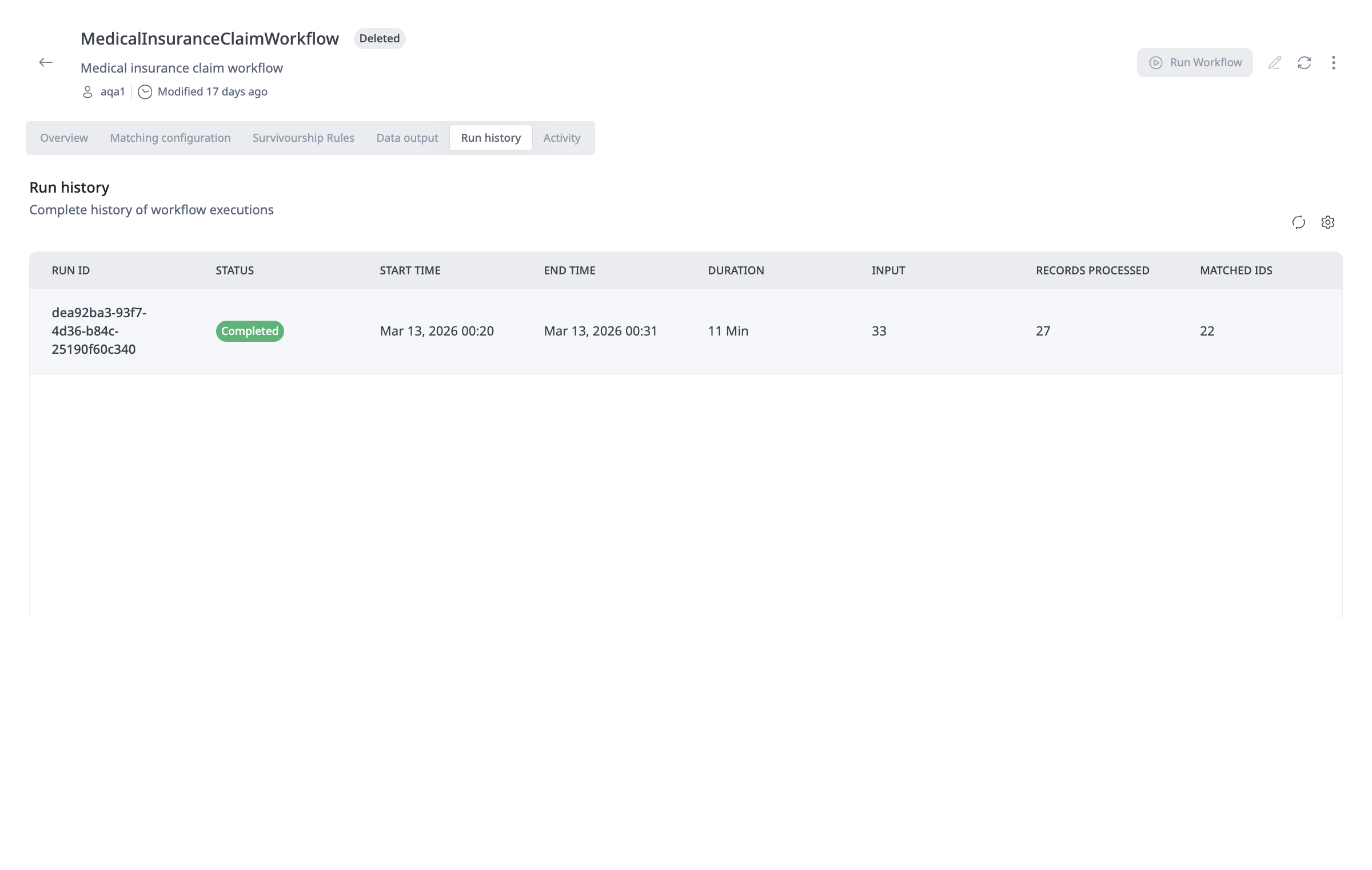
- Run ID: Unique identifier for each execution
- Status: Current status (Running, Completed, Failed)
- Start Time: When the workflow execution began
- End Time: When the workflow execution completed
- Duration: Total execution time
- Input: Number of input records processed
- Records Processed: Number of records successfully processed
- Matched IDs: Number of unique matches identified
- Activity Tab: View recent changes and events for the workflow, including:

- Workflow updates
- Workflow publications
- Workflow creation
- User actions and timestamps
- Overview Tab: View key performance metrics:
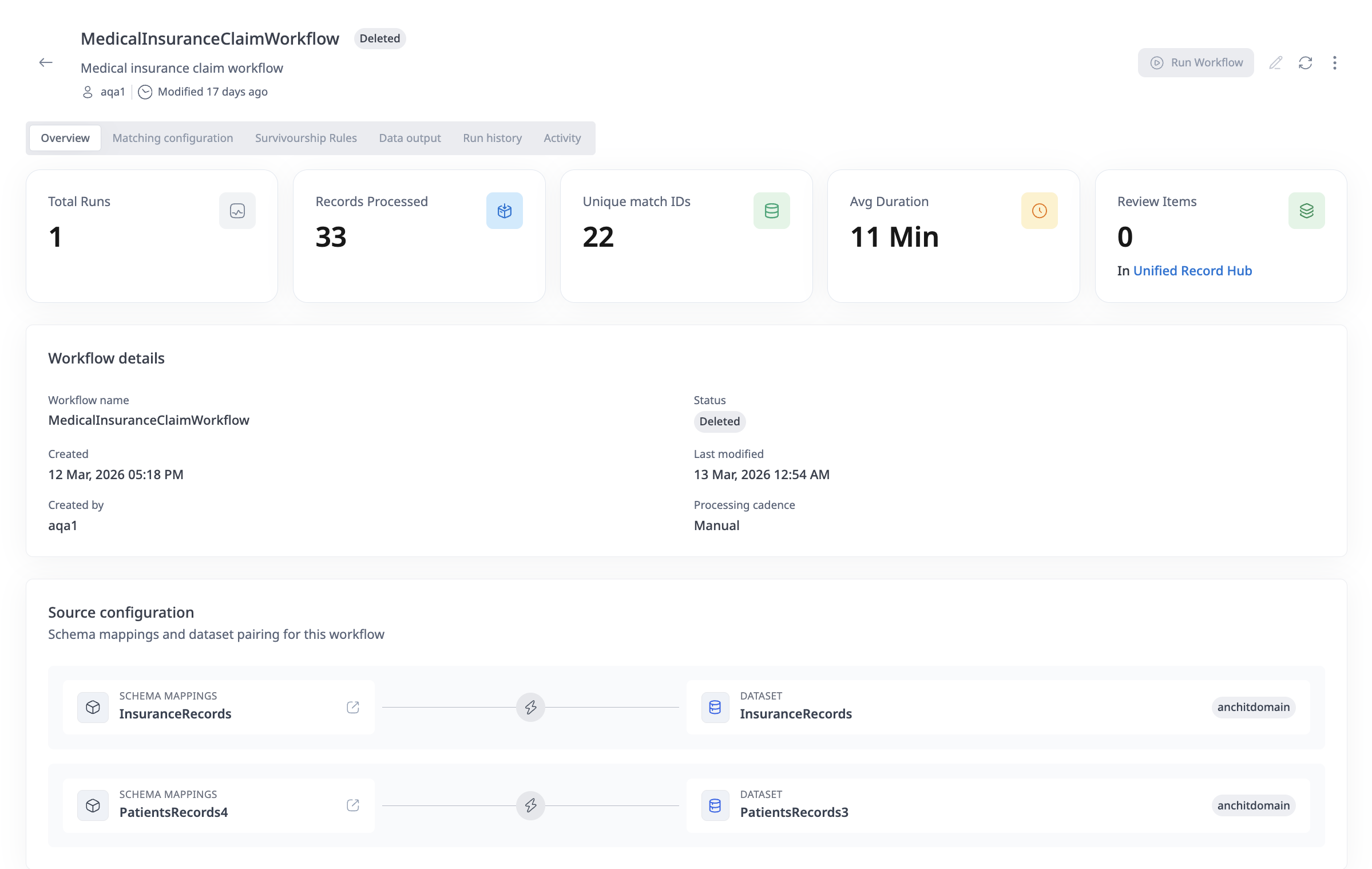
- Total Runs: Number of times the workflow has been executed
- Records Processed: Total number of records processed across all runs
- Unique Matches: Number of unique entity matches identified
- Avg Duration: Average execution time
- Review Items: Number of records requiring manual review (if confidence thresholds are configured)
Workflow Execution Status
Workflows can have the following statuses:
- Running: The workflow is currently executing
- Completed: The workflow execution finished successfully
- Failed: The workflow execution encountered an error and did not complete
How to update an ER Workflow
You can update an ER Workflow to modify its configuration:
- Navigate to the Workflows page
- Find the workflow you want to update
- Click the Edit icon in the Actions column, or open the workflow details page and click the "Edit" button
- The workflow creation wizard will open with your current configuration
- Navigate through the steps to modify any settings:
- Update workflow name or description
- Modify entity mappings
- Change matching technique settings
- Adjust survivorship rules
- Update output destination
- Click "Save" or "Update Workflow" to save your changes
When you update a workflow:
- Changes to entity mappings may require re-running the workflow
- Changes to matching rules or survivorship strategies will only affect new workflow runs
- Existing unified master records are not automatically updated when you change survivorship rules
- You may need to re-run the workflow to apply changes to existing data
Editing Workflow Details
- Workflow Name: Can be updated, but must remain unique. Only letters (A–Z, a–z), numbers, hyphens, and underscores are allowed.
- Description: Can be updated at any time
- Entity Mappings: Can add or remove entity mappings, but removing mappings may affect existing runs
Editing Matching Configuration
- Resolution Type: Can be changed, but may require reconfiguration of matching rules
- Rule Type: Only Simple is supported in the current version (not editable).
- Processing Cadence: Can be changed at any time
- Matching Rules: Can add, remove, or modify rules. Rule priority can be reordered.
Editing Survivorship Rules
- Default Strategy: Can be changed at any time
- Source Priority: Can be reordered at any time
- Attribute Rules: Can add, remove, or modify attribute-specific strategies
Editing Output Configuration
- Output Destination: Can be changed, but writing to a different dataset will create new records rather than updating existing ones
- Output Fields: Can modify which fields are included, hidden, or hashed
How to delete an ER Workflow
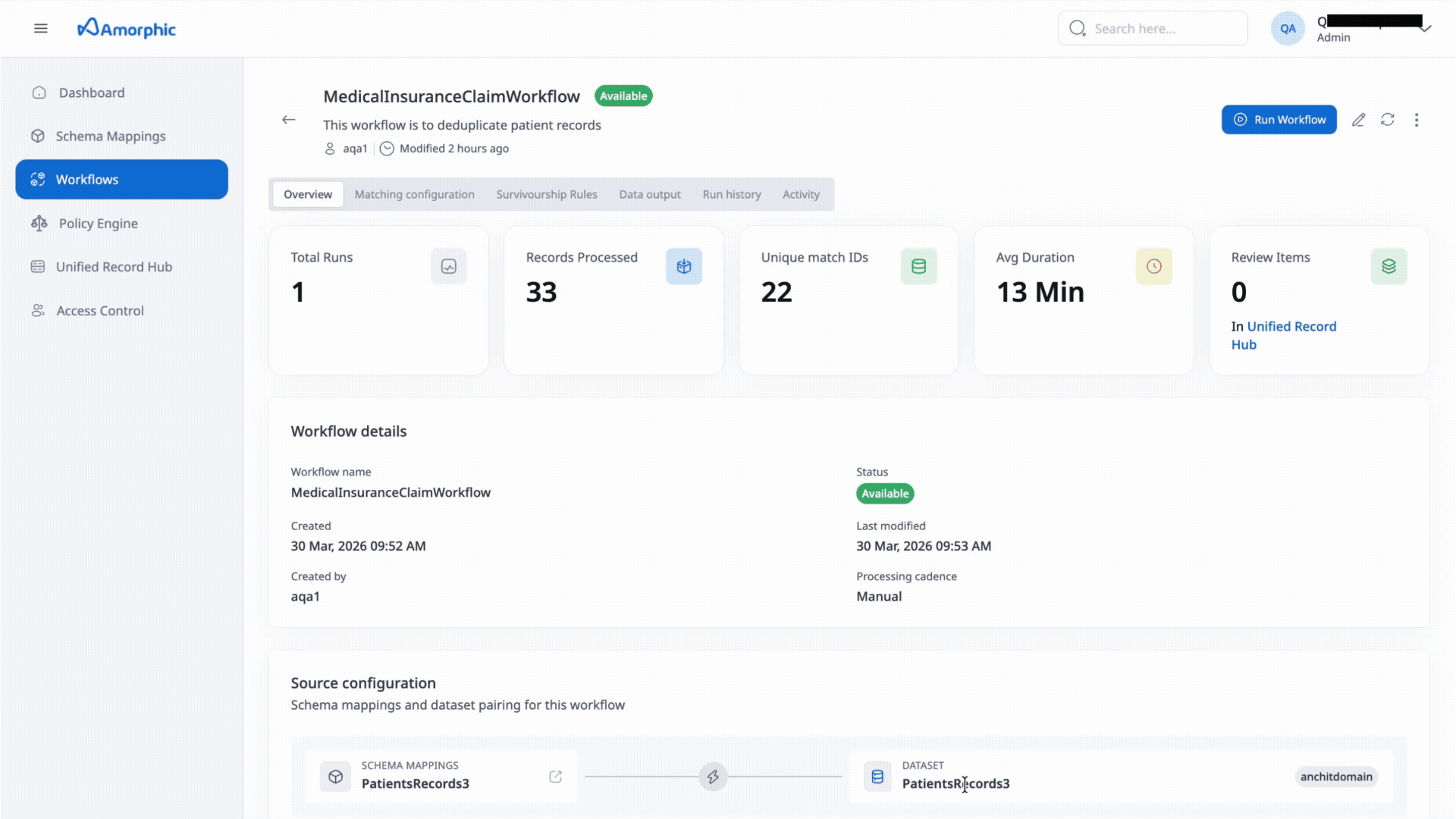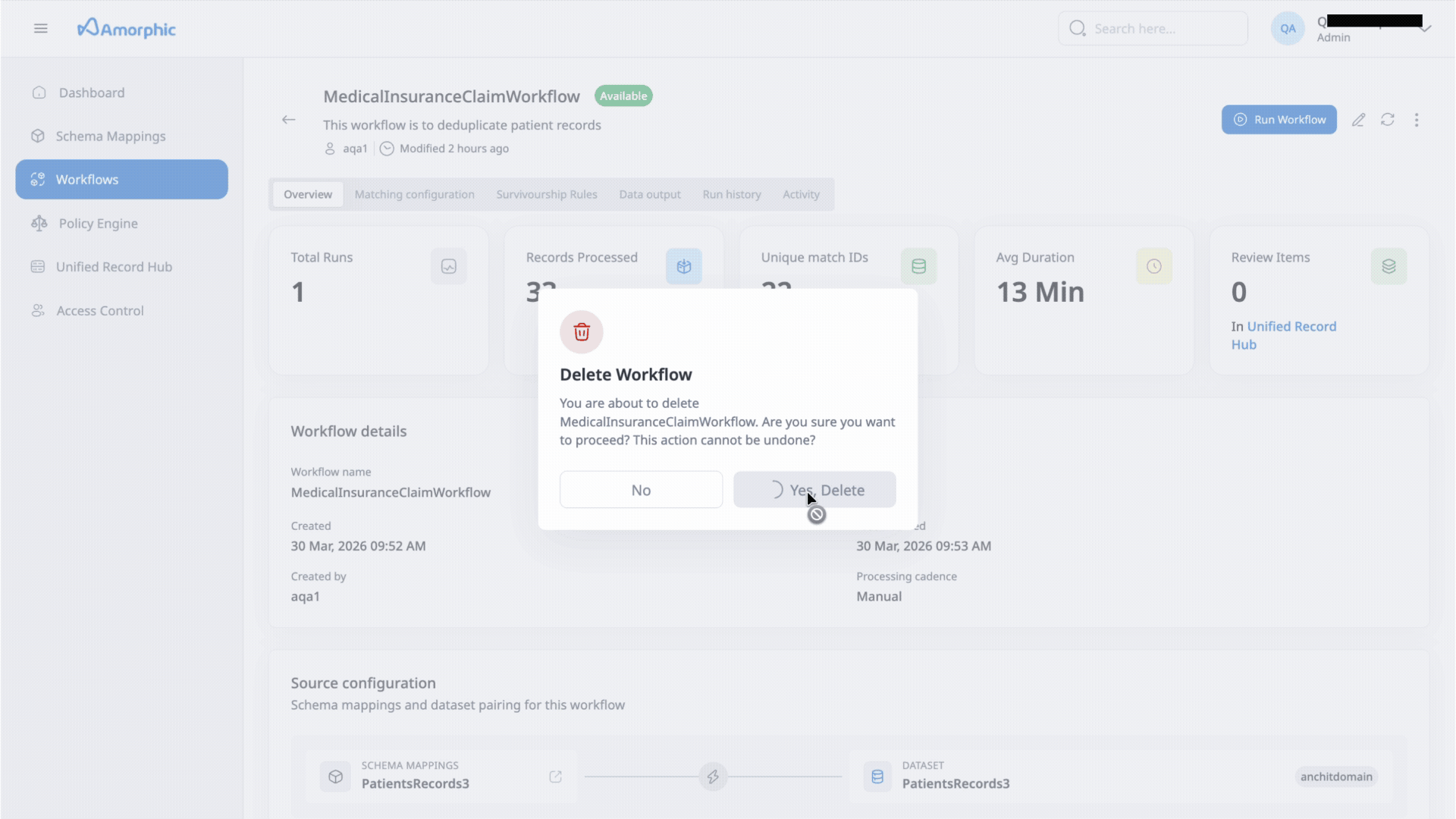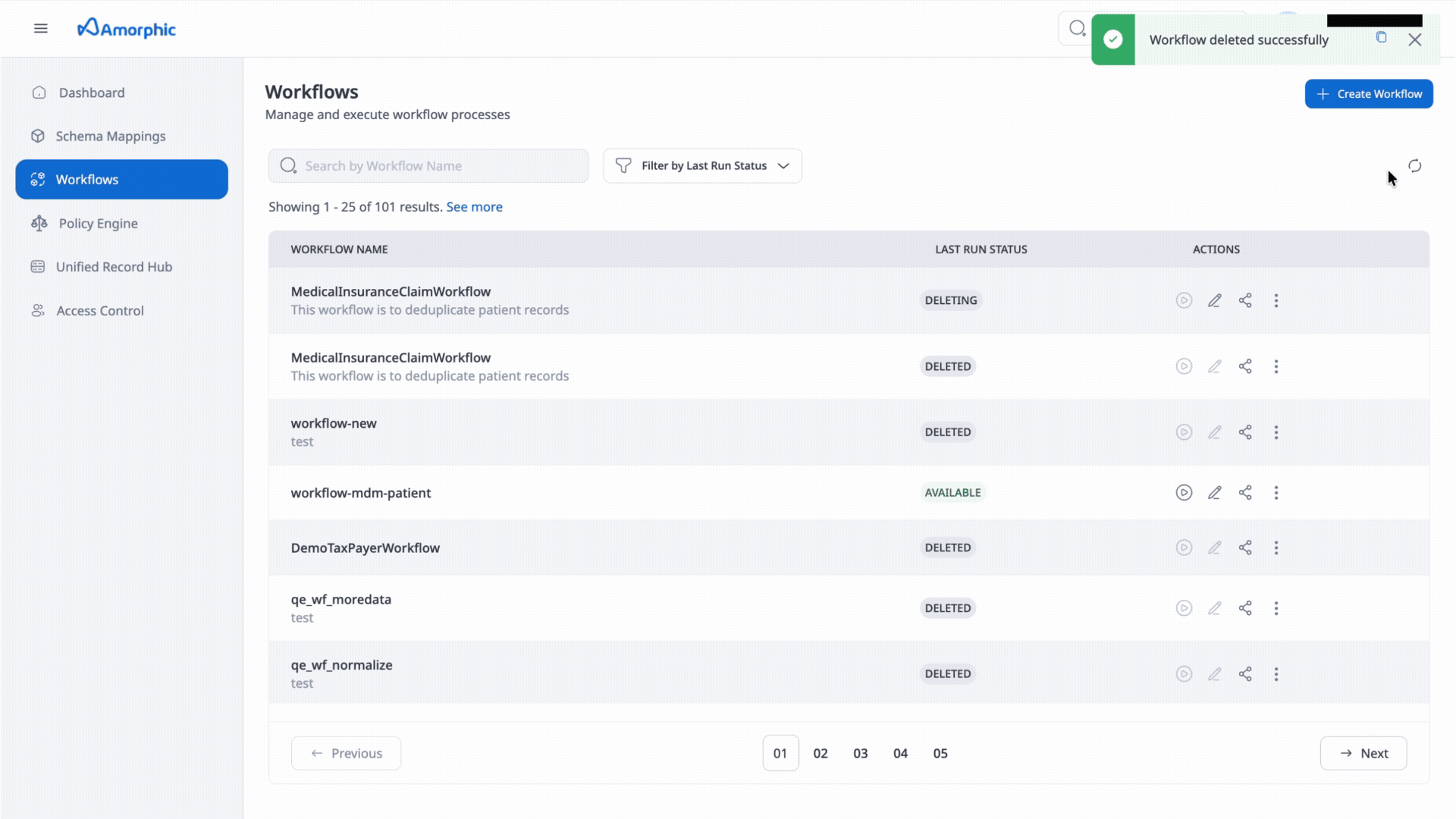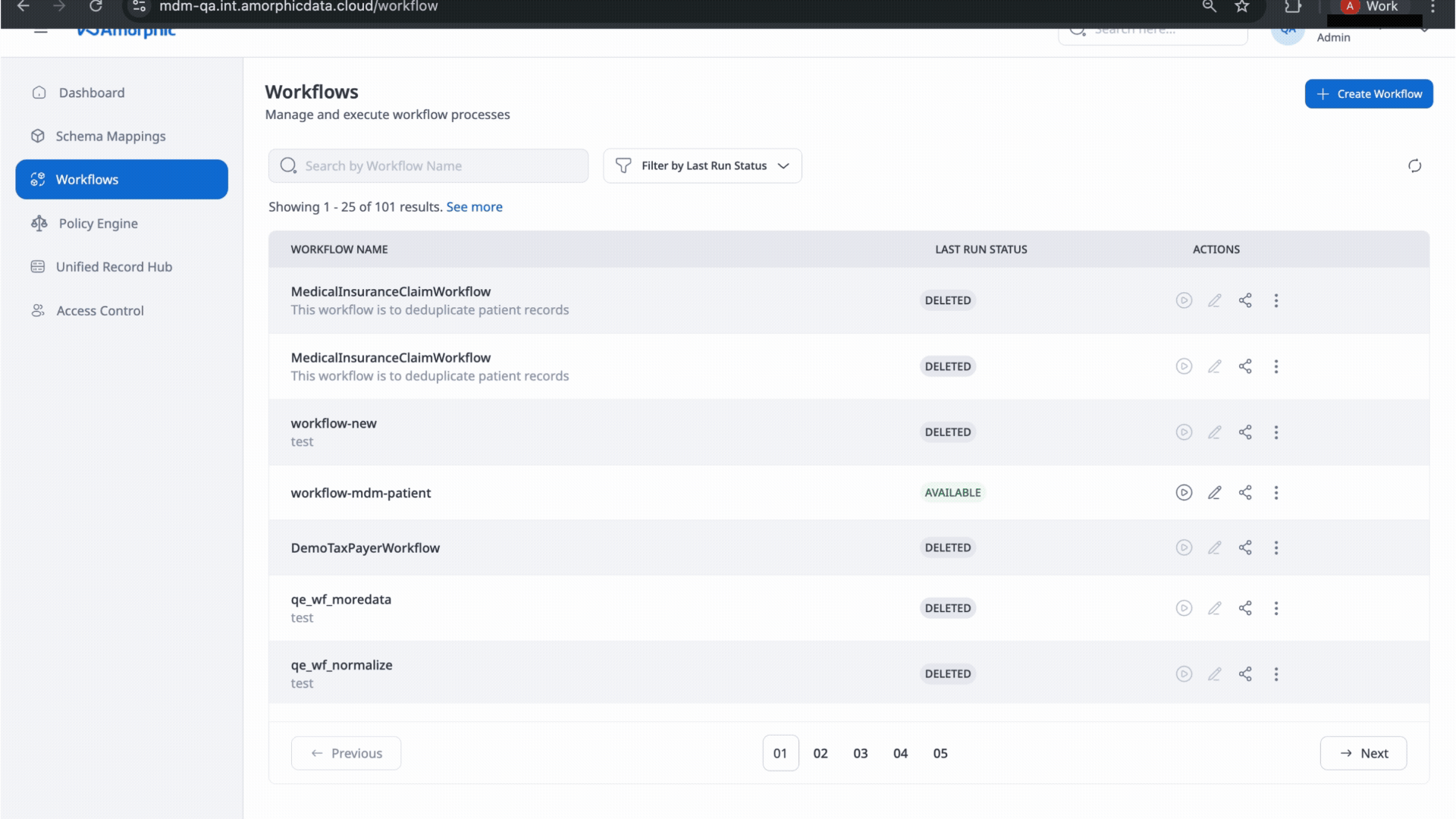
To delete an ER Workflow:
- Navigate to the Workflows page
- Find the workflow you want to delete
- Click the three vertical dots (ellipsis) icon in the Actions column
- Select "Delete" from the dropdown menu
- Confirm the deletion in the dialog that appears
Deleting a workflow:
- Cannot be undone
- Unified Master Records and workflow metadata remain intact; only backend services are cleaned up
- Does not delete the output datasets or unified master records that were created by the workflow
- Does not delete the run history (historical execution records may be retained for audit purposes)
Data Engineers and Admins can delete workflows. Data Stewards and App Viewers cannot delete workflows.