
Creating a Parquet dataset
Amorphic supports dataset creation for Parquet on the following Target types,
- Redshift
- S3Athena
- S3
- LakeFormation
- AuroraMySQL isn't currently available for Parquet type dataset
- The Sample file to be uploaded during dataset creation should be of CSV format
Following are the steps, as shown below, to create a Parquet dataset,
-
Go to create dataset page, select any one of creation method out of Use Template, Import JSON and Create From Scratch.
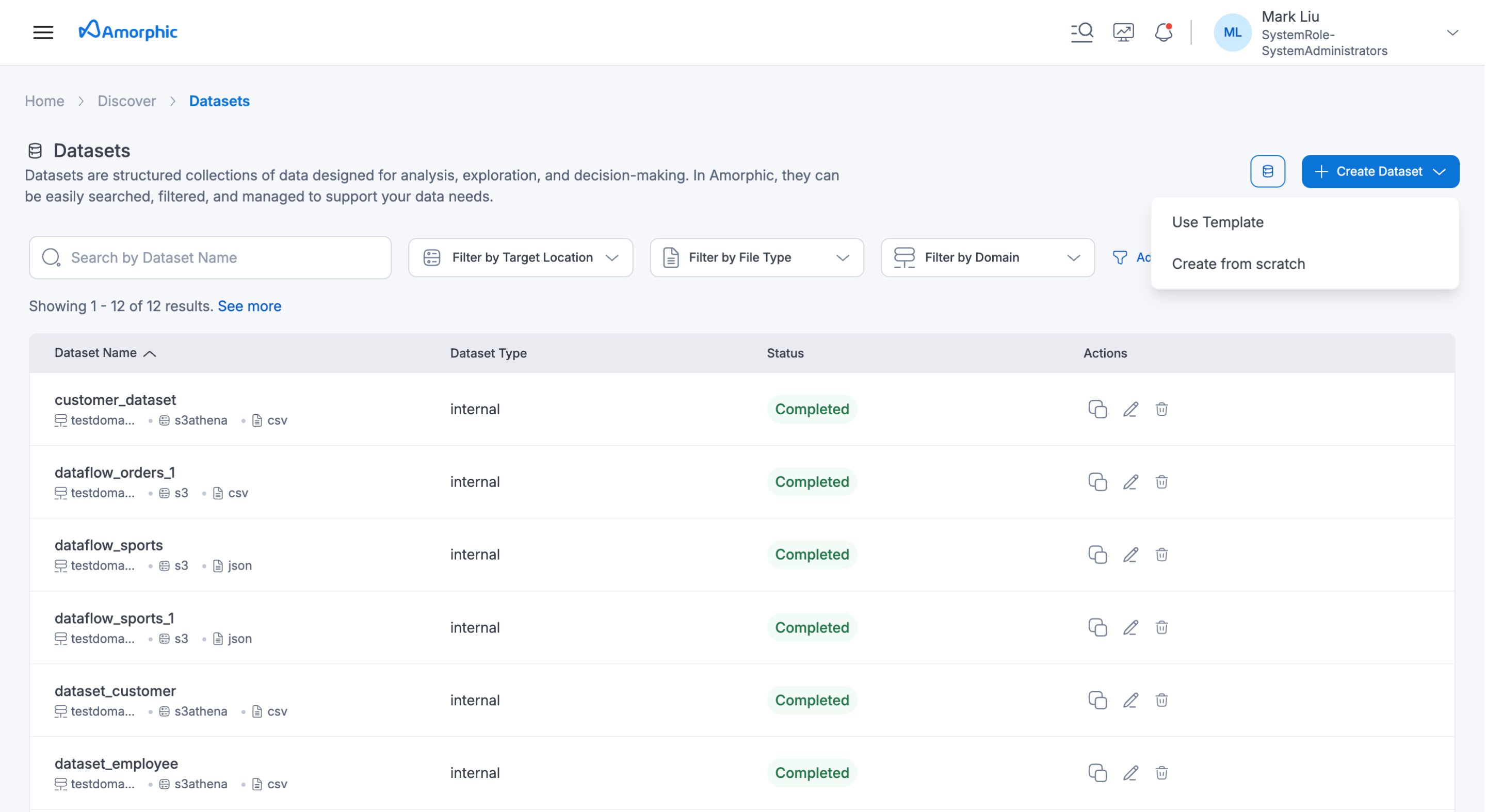
-
Creating a parquet dataset through 'Use Template'
-
Inside Use Template we have already have iceberg_s3athena_dataset_system_template with file type parquet.
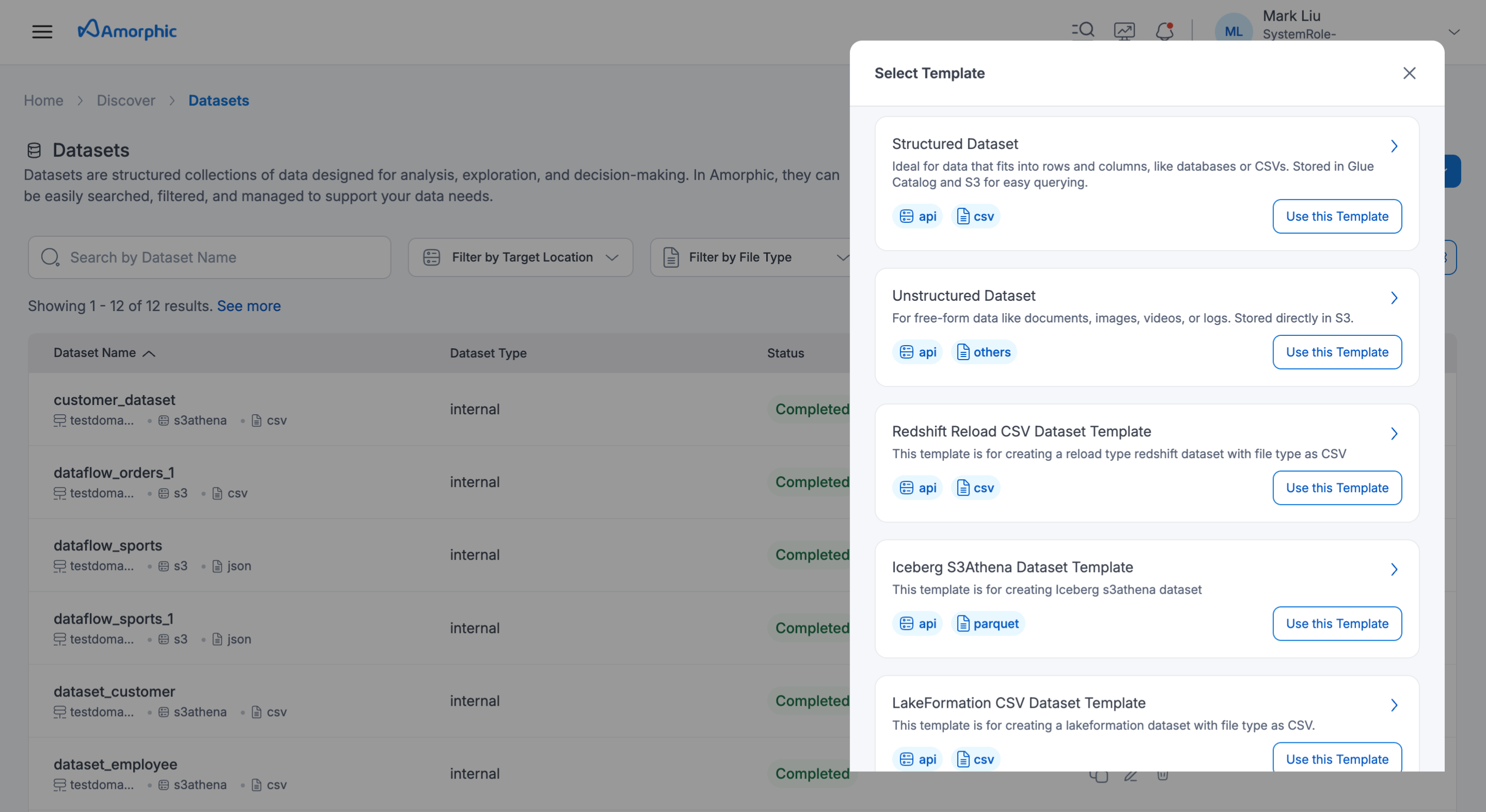
-
After choosing required template, we need to fill domain, dataset name, ingestion type while other metadata will be pre-filled.
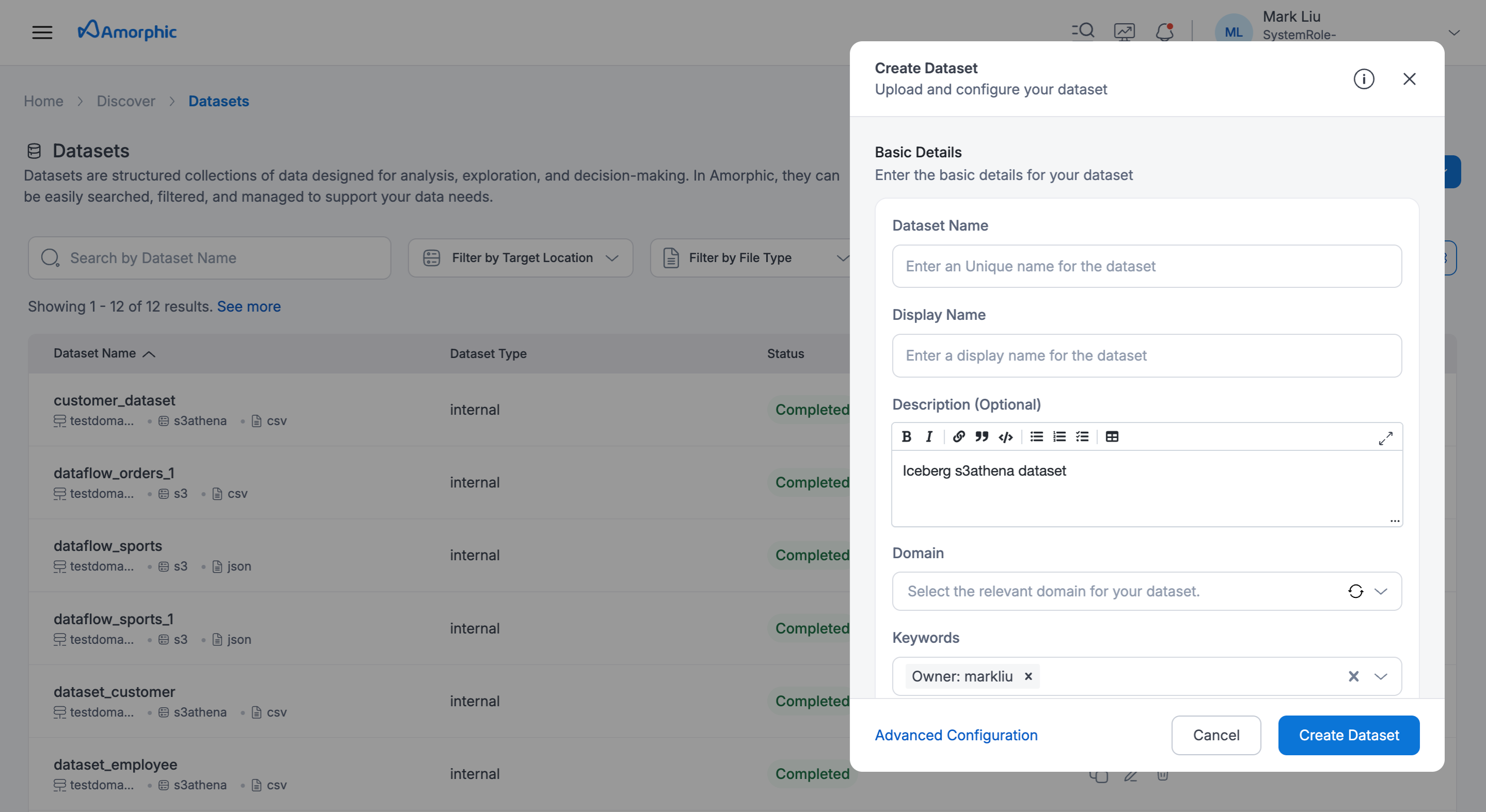
-
In the second page, Upload Schema, you'd be asked to upload a sample file to extract schema for the dataset. The sample file, should be of CSV file type even for Parquet type datasets.
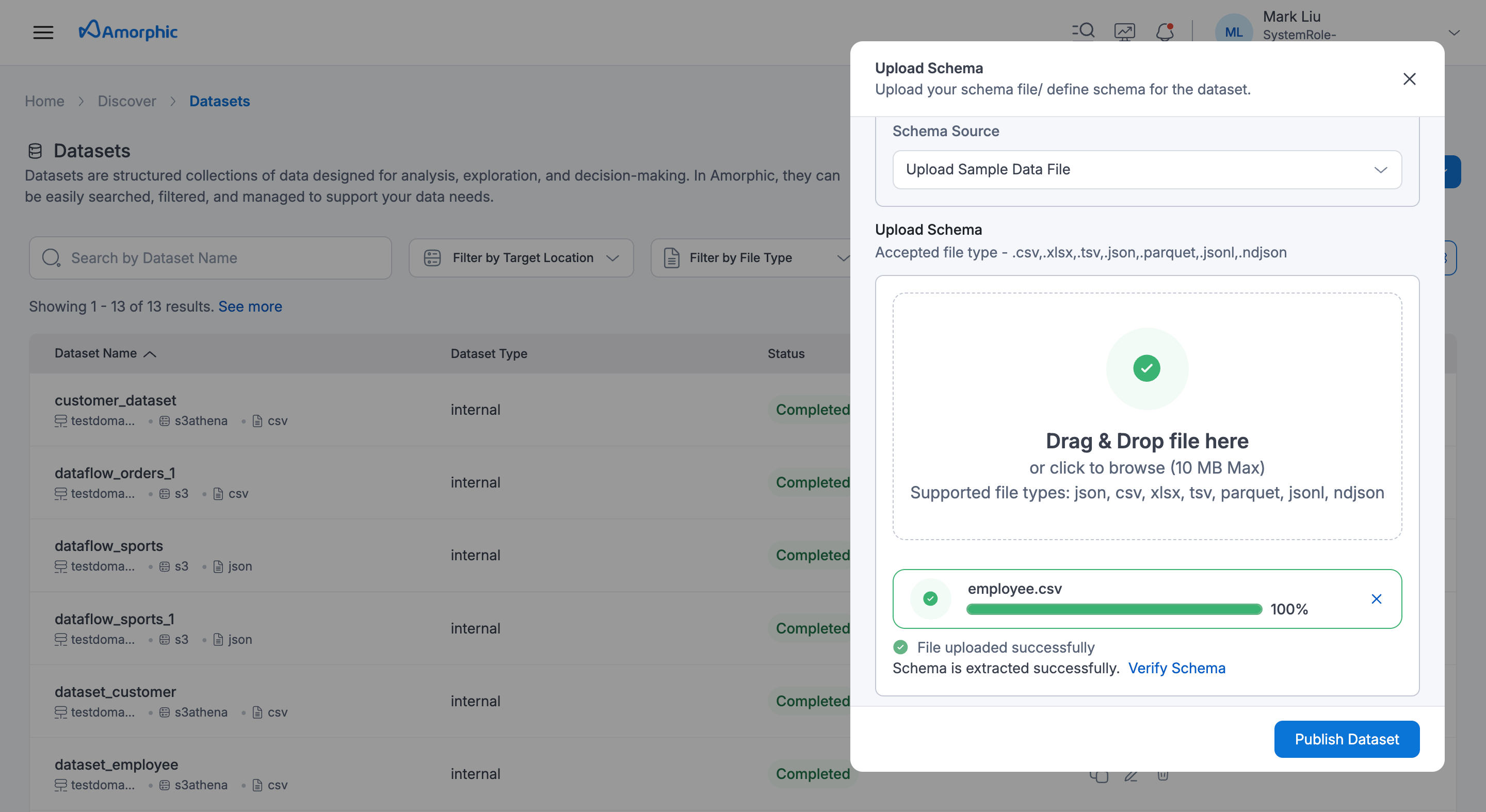
-
After uploading the sample file, click view details to review to the extracted schema and if the schema looks as per requirement, click Publish Dataset
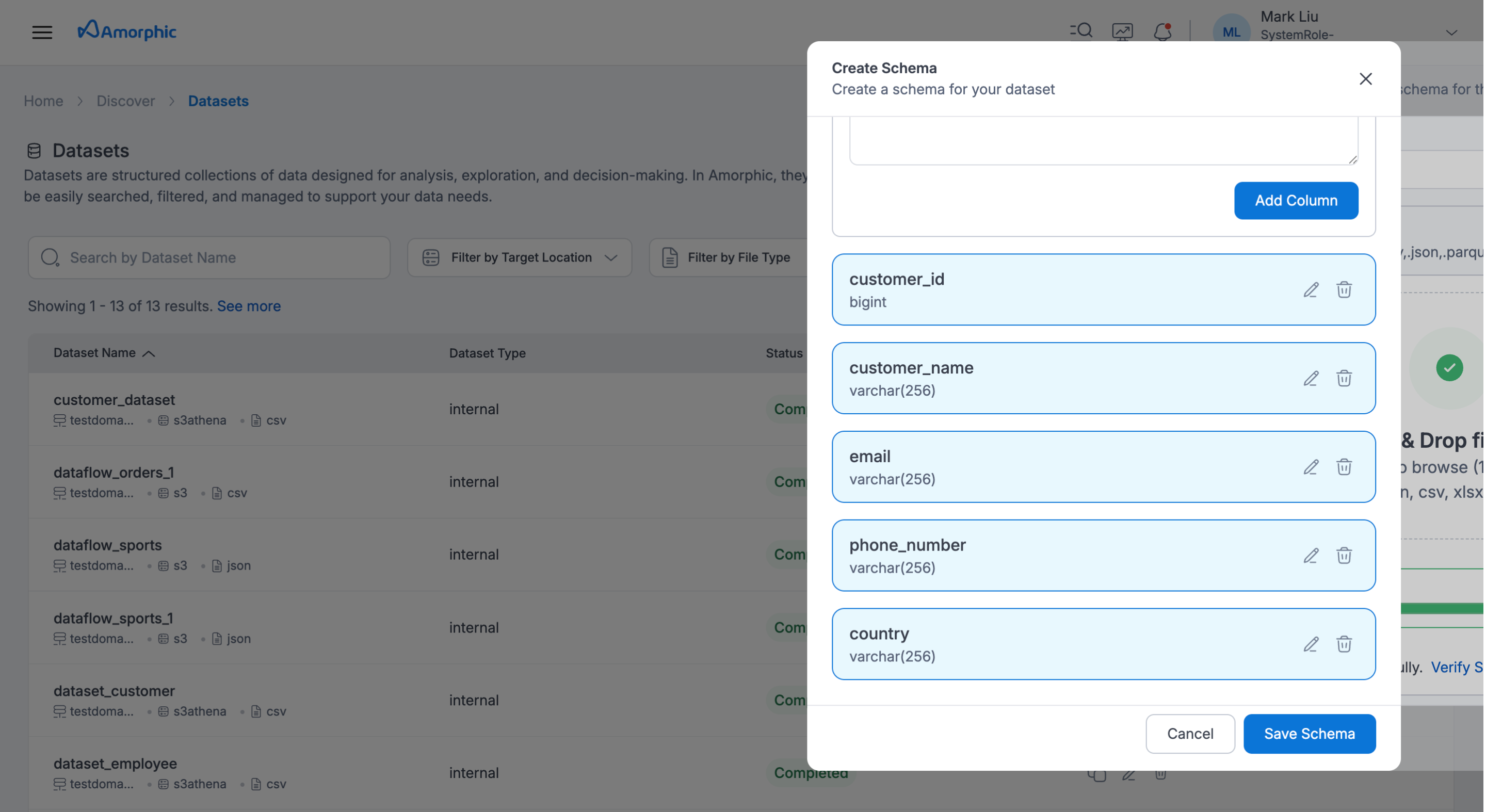
-
-
Creating parquet dataset through 'Import JSON'
-
Inside Import JSON we upload a json file that contains required metadata for parquet dataset creation.
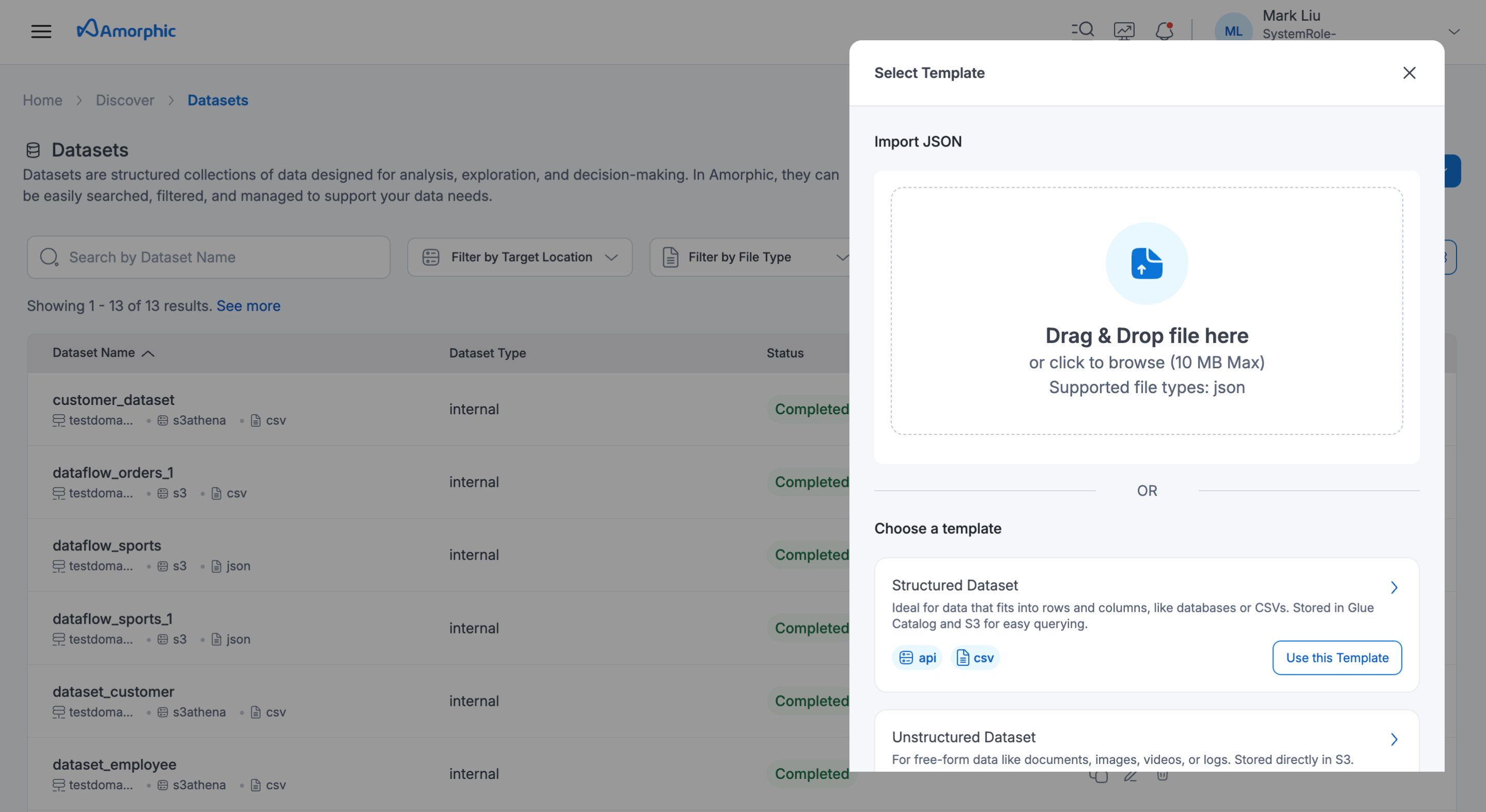
-
After choosing required template, we need fill domain, dataset name, ingestion type while other metadata will be pre-filled.
-
In the second page, Upload Schema, you'd be asked to upload a sample file to extract schema for the dataset. The sample file, should be of CSV file type even for Parquet type datasets.
-
After uploading the sample file, click view details to review to the extracted schema and if the schema looks as per requirement, click Publish Dataset
-
-
Creating parquet dataset from scratch
-
Go to create from scratch, select File Type as Parquet and fill out the appropriate values to remaining fields as per your requirement
-
In the second page, Upload Schema, you'd be asked to upload a sample file to extract schema for the dataset. The sample file, should be of CSV file type even for Parquet type datasets.
-
After uploading the sample file, click next to review to the extracted schema and if the schema looks as per requirement, click Publish Dataset
-