
Run data reload
Create a dataset with Reload type in create dataset page. For information on how to create a dataset please visit create new dataset
The image below showcases the Create Dataset page in Amorphic.

Data reload for a dataset can be done in two ways, either via API or via UI.
Reload through UI
Use the Upload File(s) option at the top of the UI to begin uploading files. You can upload either a single file or multiple files simultaneously.
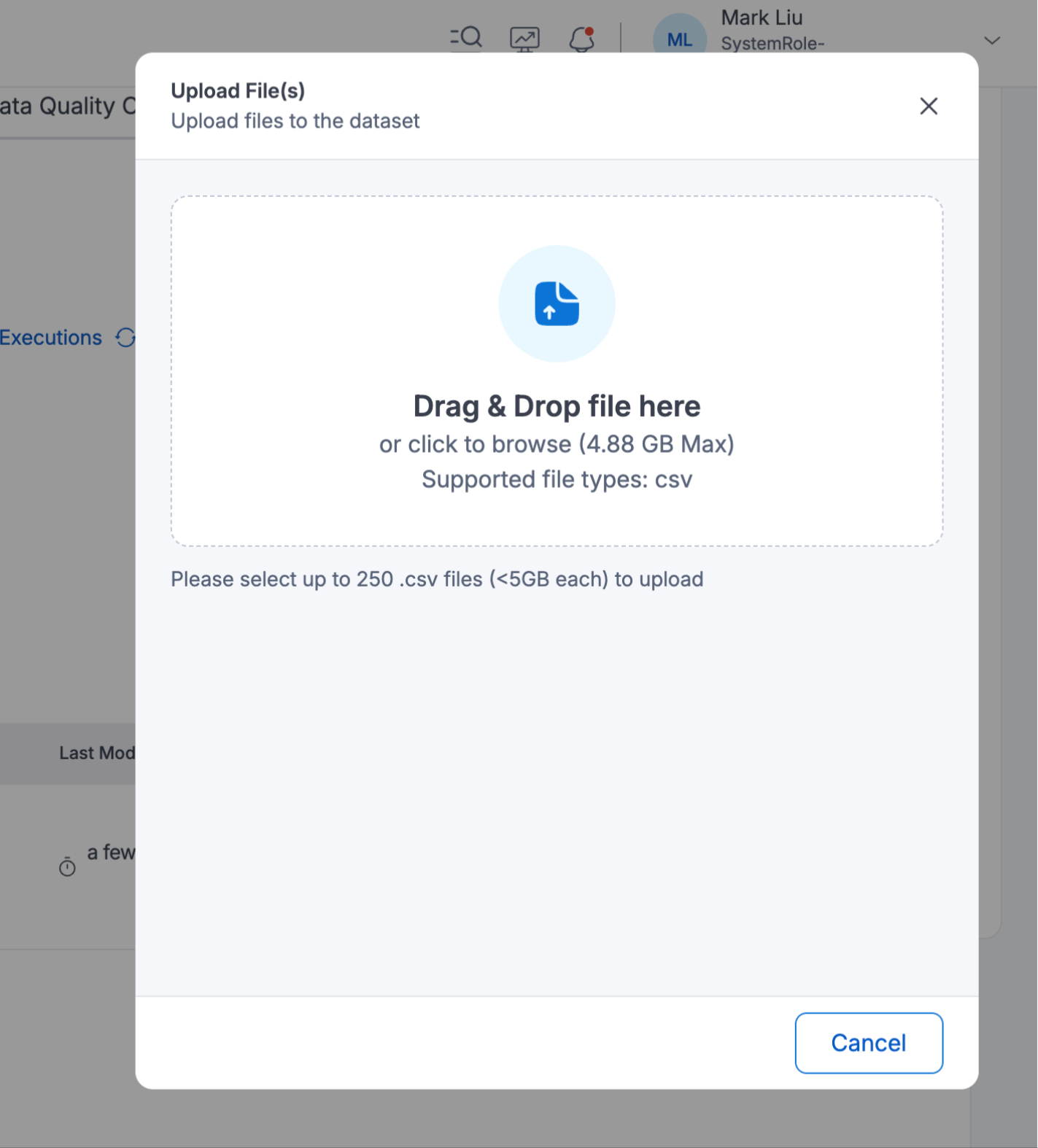
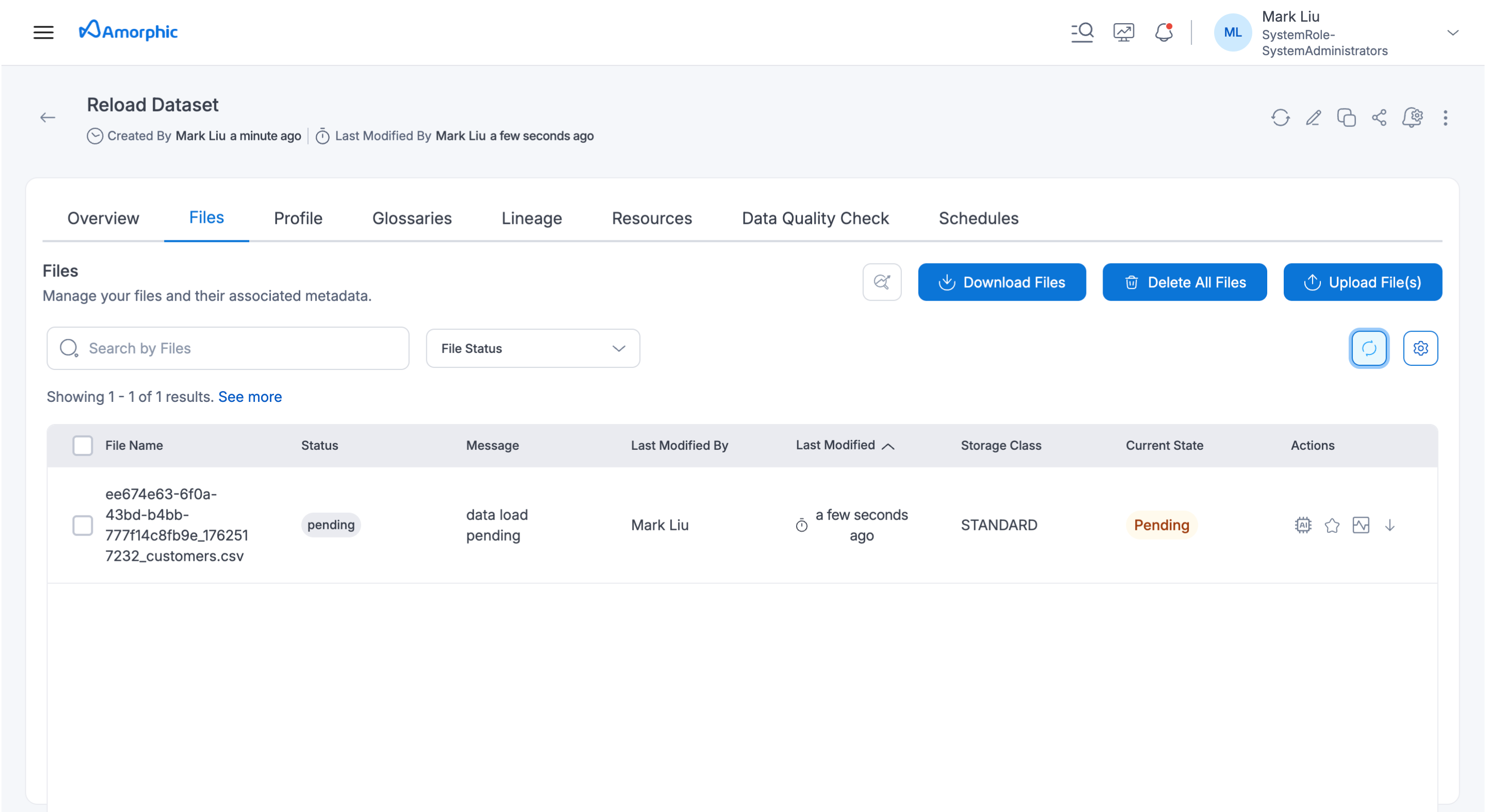
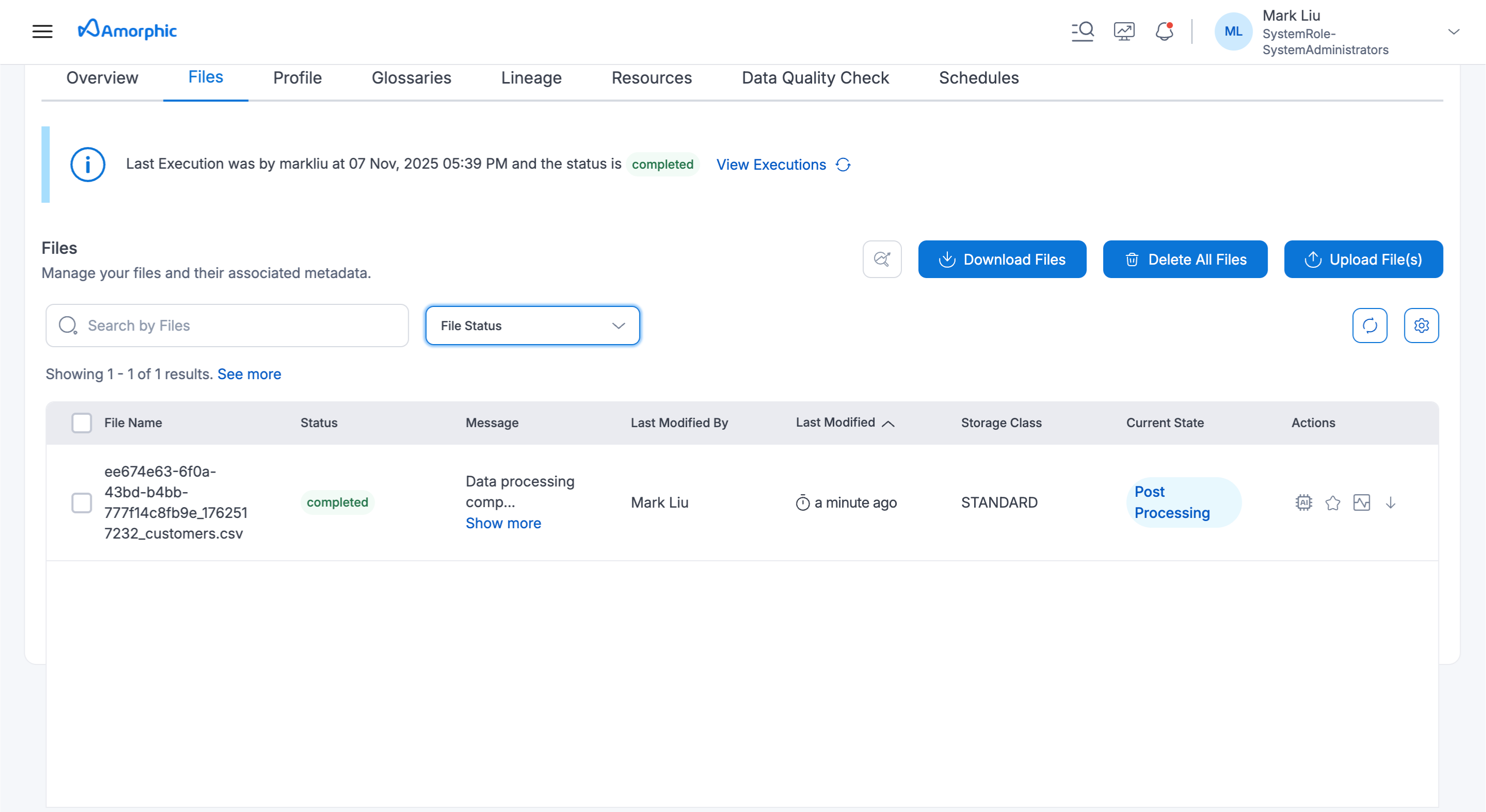
After successfully uploading the files, they will be in a pending status. This will require user action for further processing. The example below illustrates the file status after a successful upload.
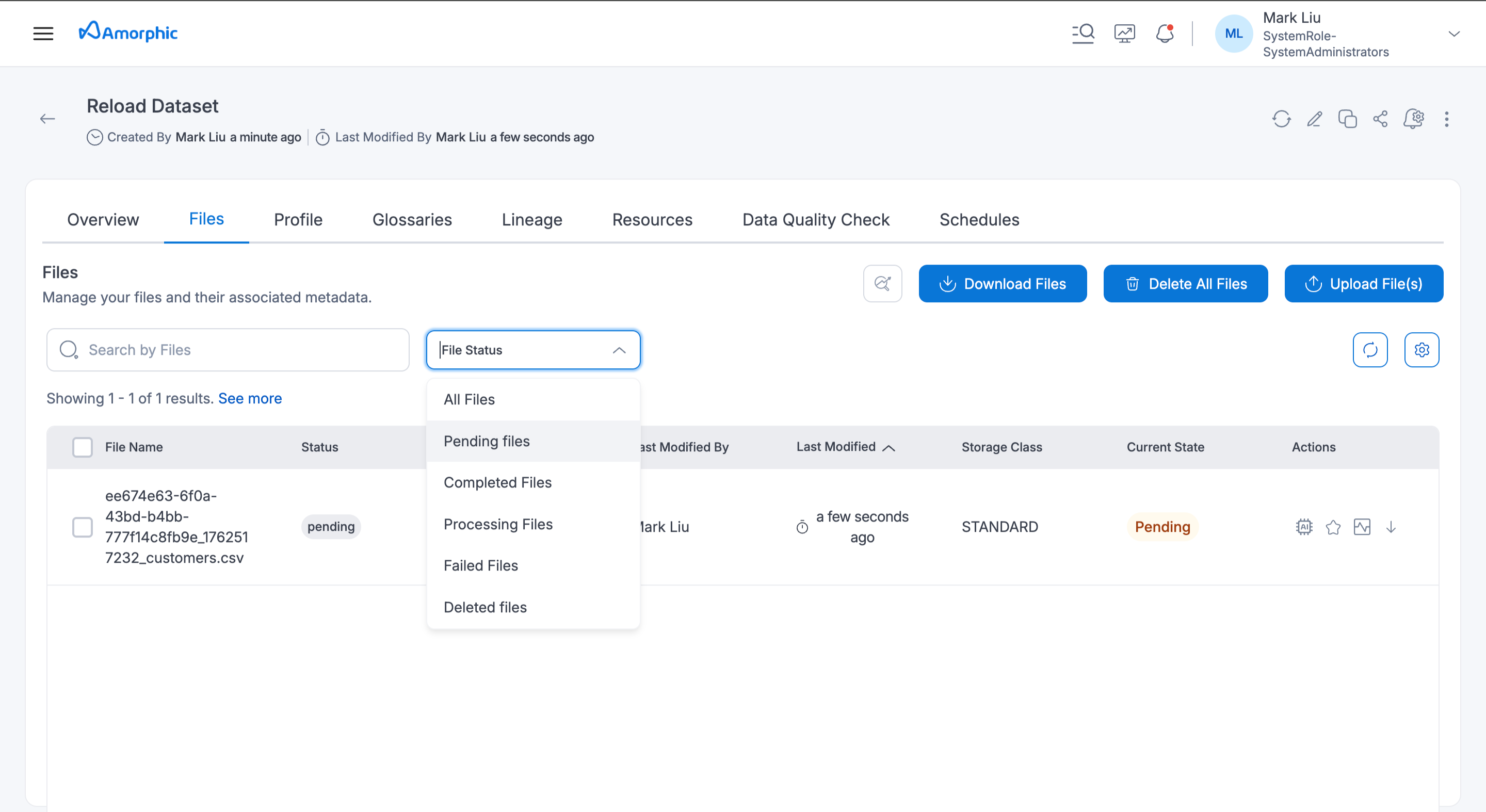
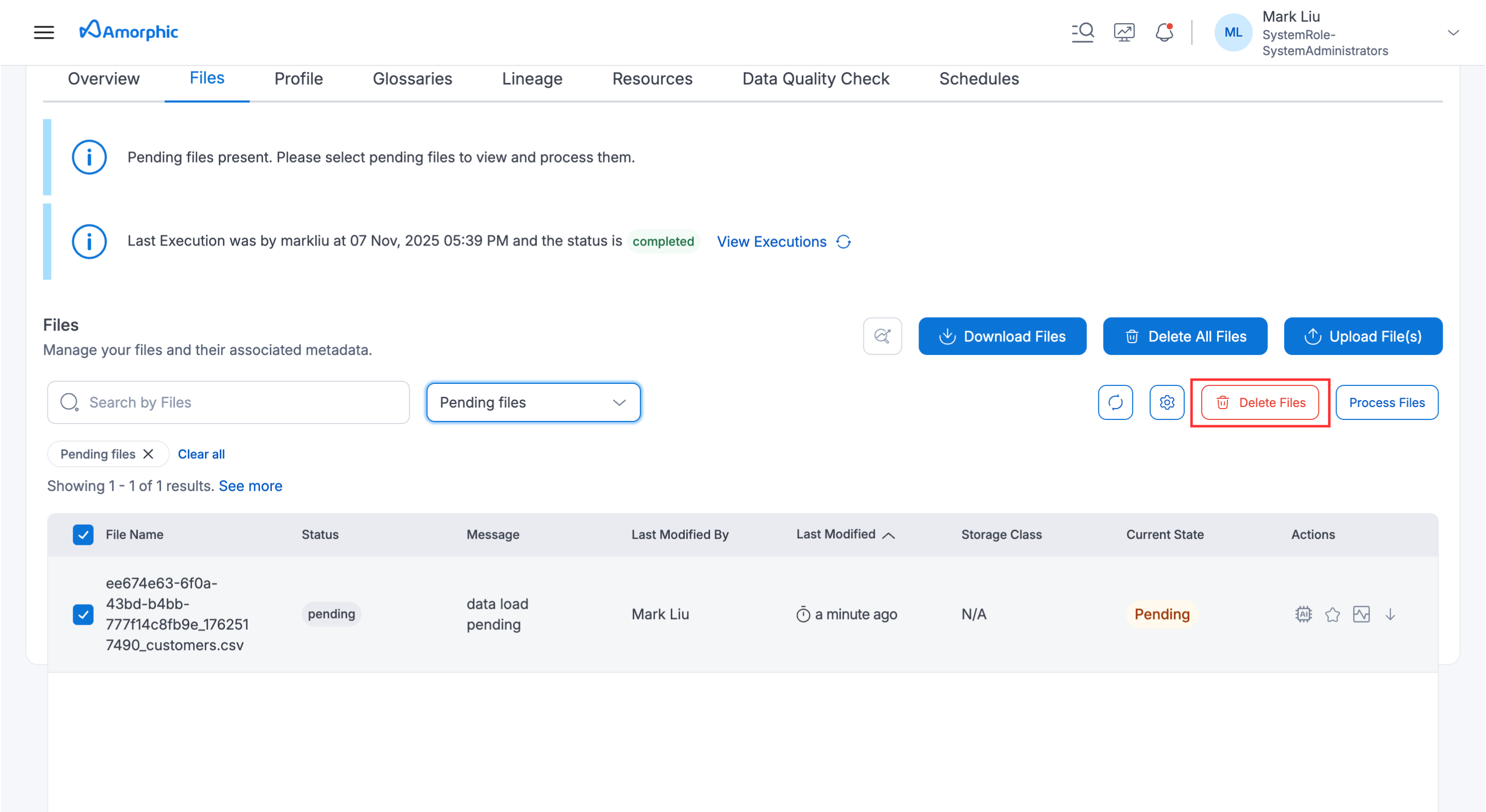
Go to the FileStatus tab and select Pending files to filter all files in pending status. From there, users can choose to select or deselect files for processing.
User have to select the files that are required for processing from the pending files & then click on the Process Files option as shown in image below. This will start the Data Reload process and will continue running in the background.
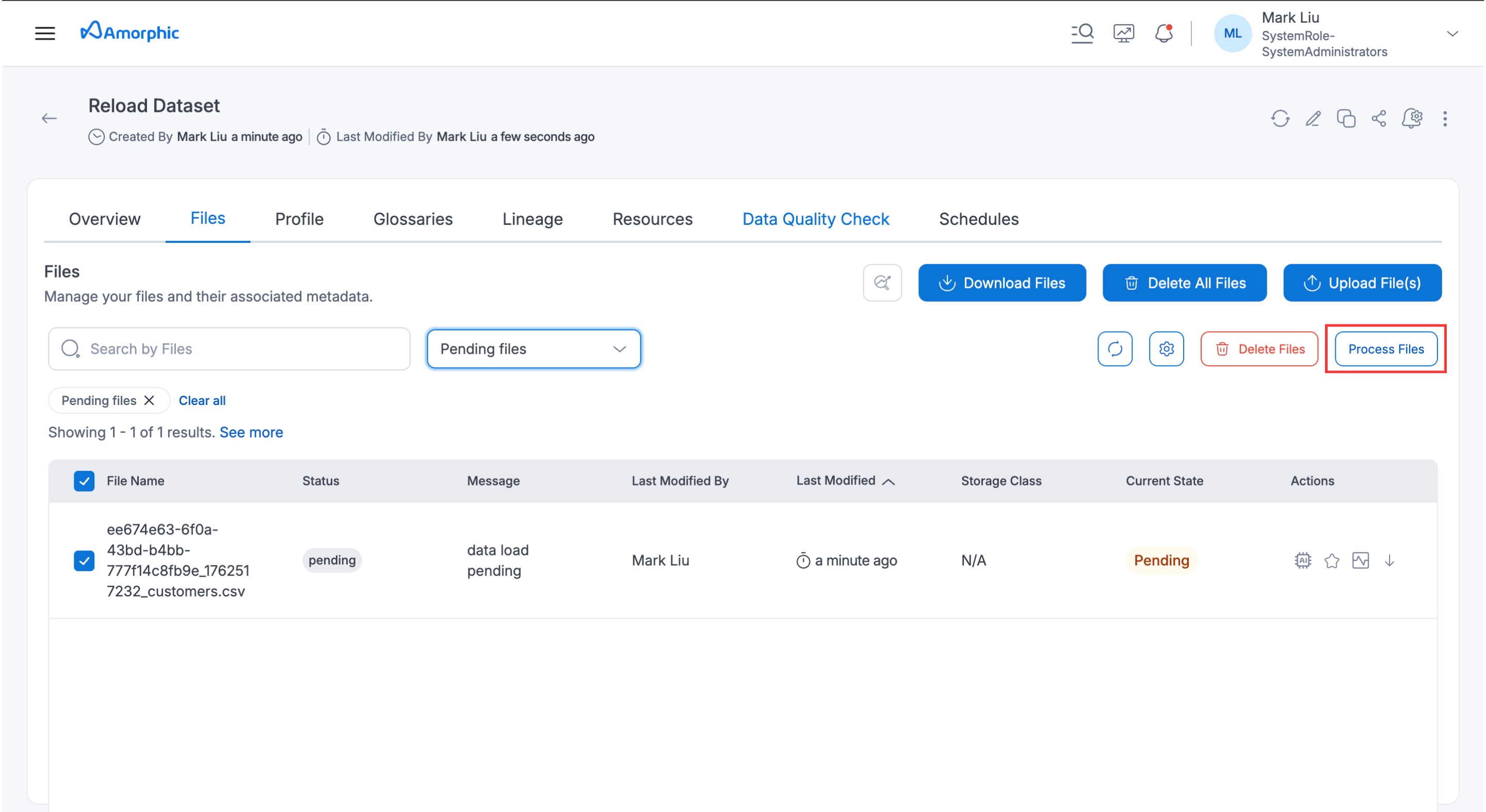
The status of the selected files will update to processing during the reload. After the successful completion of the data load, the file statuses will change to completed, and the message will be updated accordingly.
Reload through API
- User have to write the data files to LZ(Landing Zone) location via ETL or Glue jobs in the Dataset landing location in the below format.
s3://<LZBucket>/<Domain>/<DatasetName>/upload_date=<epoch>/<UserId>/<FileType>/<FileName1>
s3://<LZBucket>/<Domain>/<DatasetName>/upload_date=<epoch>/<UserId>/<FileType>/<FileName2>
s3://<LZBucket>/<Domain>/<DatasetName>/upload_date=<epoch>/<UserId>/<FileType>/<FileName3>
s3://<LZBucket>/<Domain>/<DatasetName>/upload_date=<epoch>/<UserId>/<FileType>/_SUCCESS
-
Once all files are uploaded to the LZ bucket, a trigger file named (_SUCCESS) must be placed in the same directory as the data files to initiate the data load.
-
As soon as the trigger file is detected in the LZ location, the data reload process will begin automatically and run in the background.
-
Even after all files have been written to the LZ location, users can manually initiate the data reload from the UI as described earlier.
The _SUCCESS file can be a dummy file not necessarily a real data file as it acts as a trigger and not included in the dlz bucket writing. Ensure that file named _SUCCESS should not have file extension.
Delete Unwanted files
All unwanted files that have been added to the dataset can be deleted from the Pending files. User have to select all the files that are not required for this dataset and click on Delete Files at the end of the page which deletes the files that are pending status.
Additional Information
- Users will receive an email notification upon successful completion or failure of a data reload, including details on the status and any errors encountered, if any.
- If a data reload process is already running for a dataset, concurrent execution is not permitted. Attempting to start another process via the UI will result in an exception, while API uploads will trigger an email notification to the user.
- Datafiles that are added to the dataset will be in pending status and can be processed later in any of the cases above.