
JDBC Advanced Data Load Entities
JDBC Advanced data load entities in Amorphic use AWS MSK Kafka Clusters.An AWS MSK Kafka cluster durably stores and replicates event streams across multiple brokers and availability zones, providing ordered and replayable data. Producers (source connectors) write data from your databases to topics in the cluster, and consumers (sink connectors) read from those topics to send data to Amorphic datasets.
This feature allows setting up multiple dataflows with a single entity, rather than one entity for each dataflow. When the global entity flag is set to true, entities can be shared across different datasources, enabling greater resource utilization and cost optimization.
How to Create an Entity (Shared Cluster)
Below are the steps required to create a entity for JDBC Advanced data load datasources:
Entity Configuration
-
Entity Name: Name of the entity to be used as an identifier. -
Description: Purpose of this entity to help authorized users understand its requirement. -
IsGlobalEntity: It's a Boolean value. When it's true, entity can be used in any dataflows across datasources. When false, entity is restricted to current datasource only. -
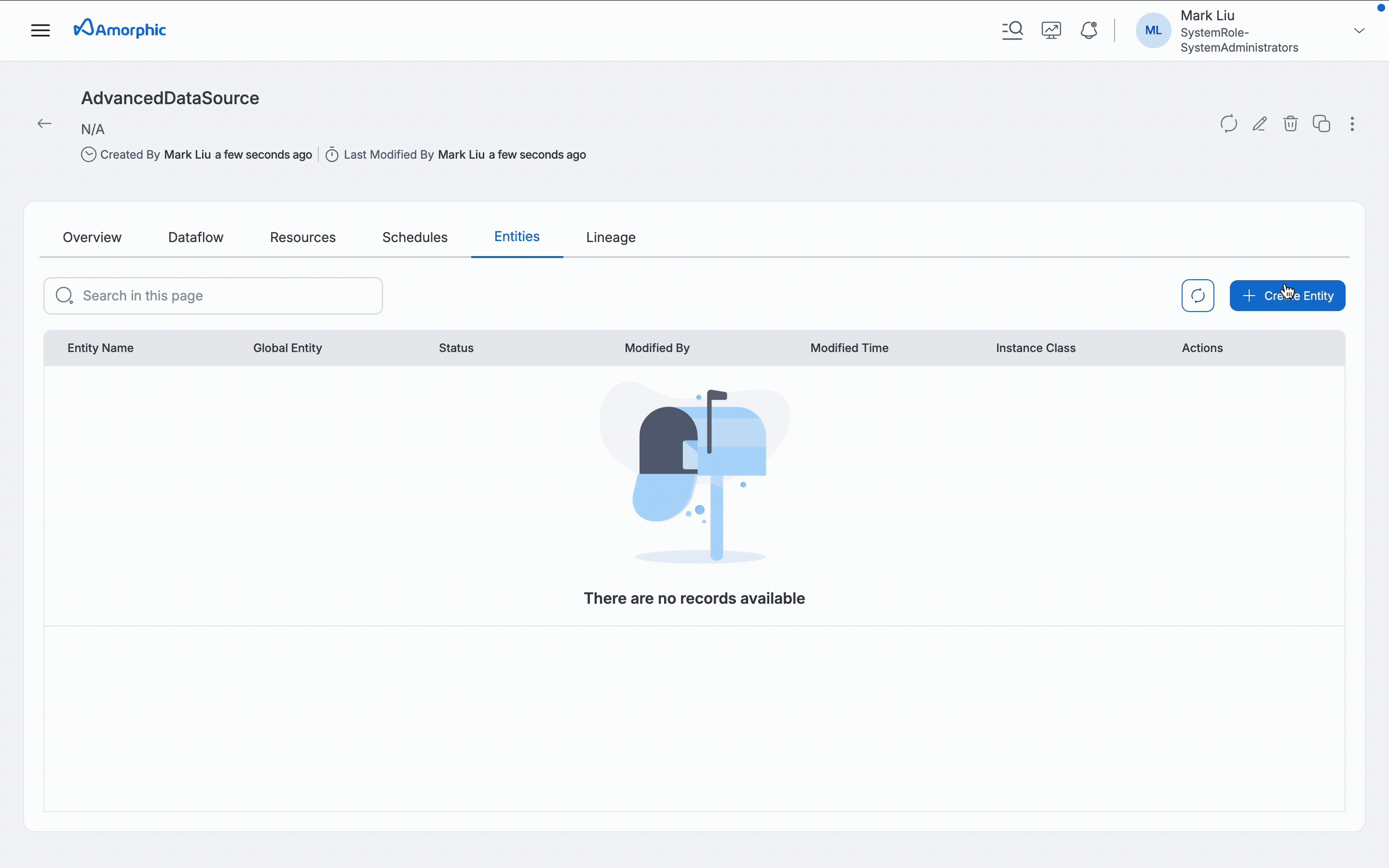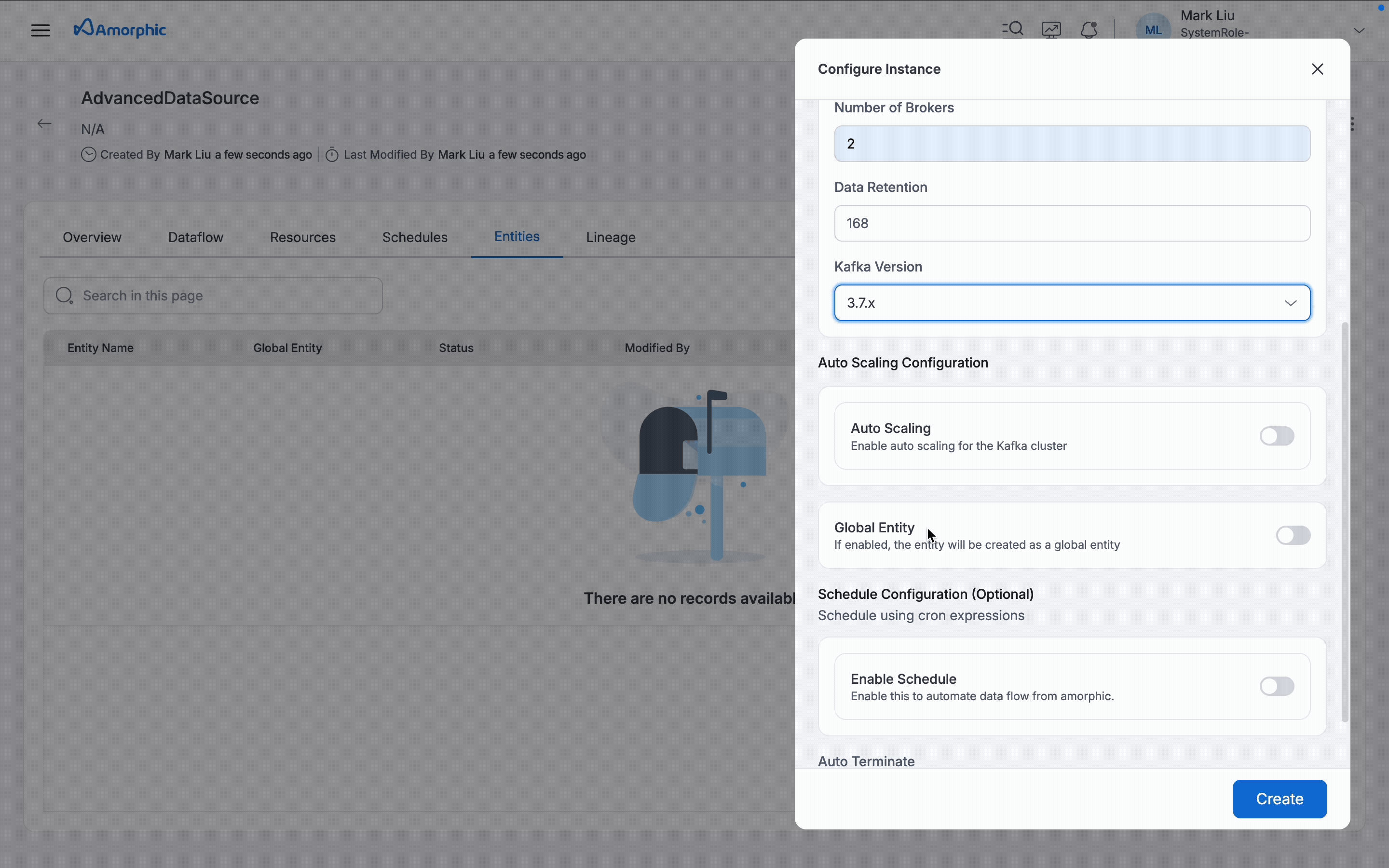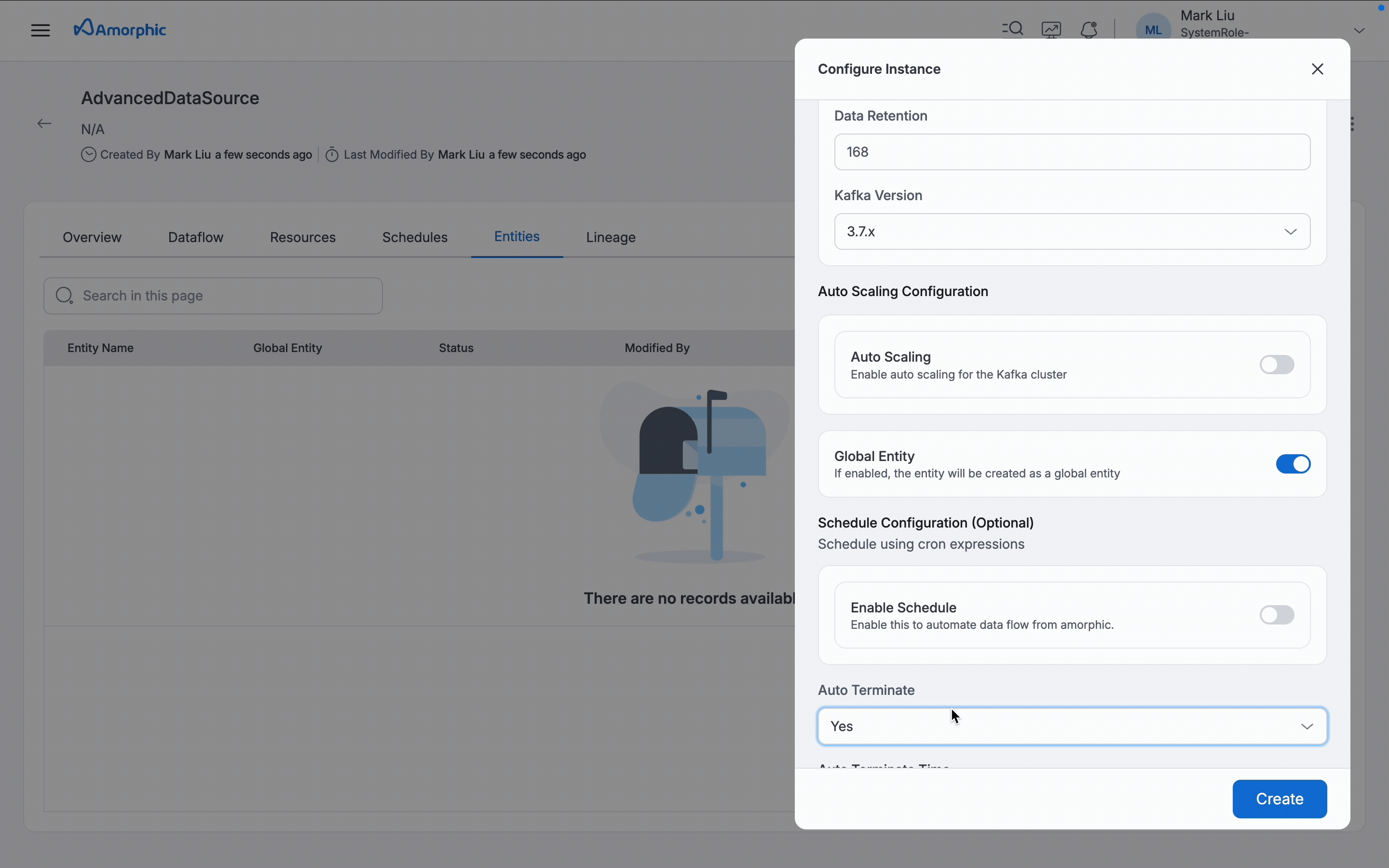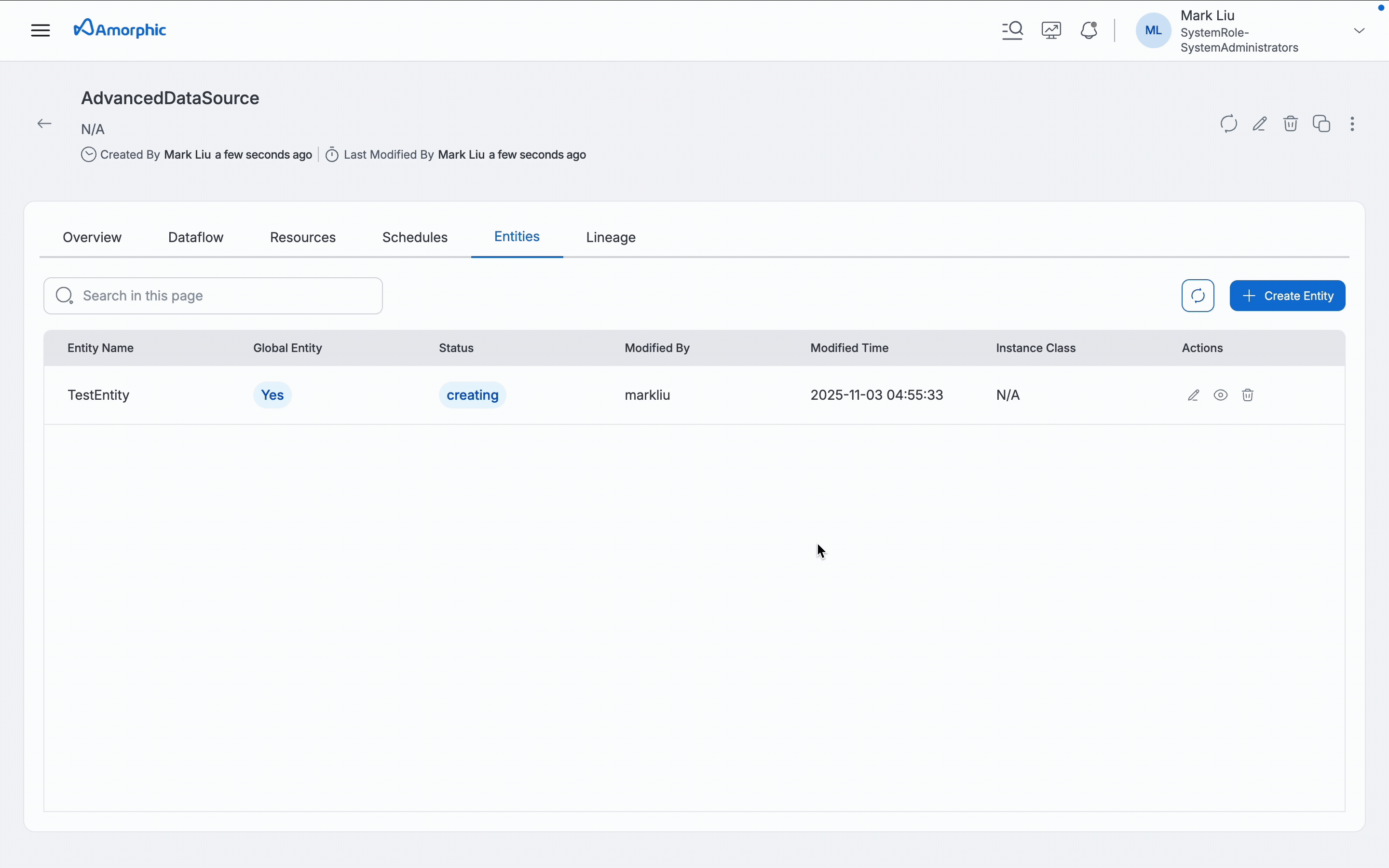
Cluster Size: Defines the instance type and the overall processing power allocated for your advanced dataload datasource. For additional information, refer to Amazon MSK broker sizes. -
Number of Brokers: The number of broker nodes working together to manage and balance the data load. -
Cluster Storage: The amount of data storage available for each broker node handling ingestion process. -
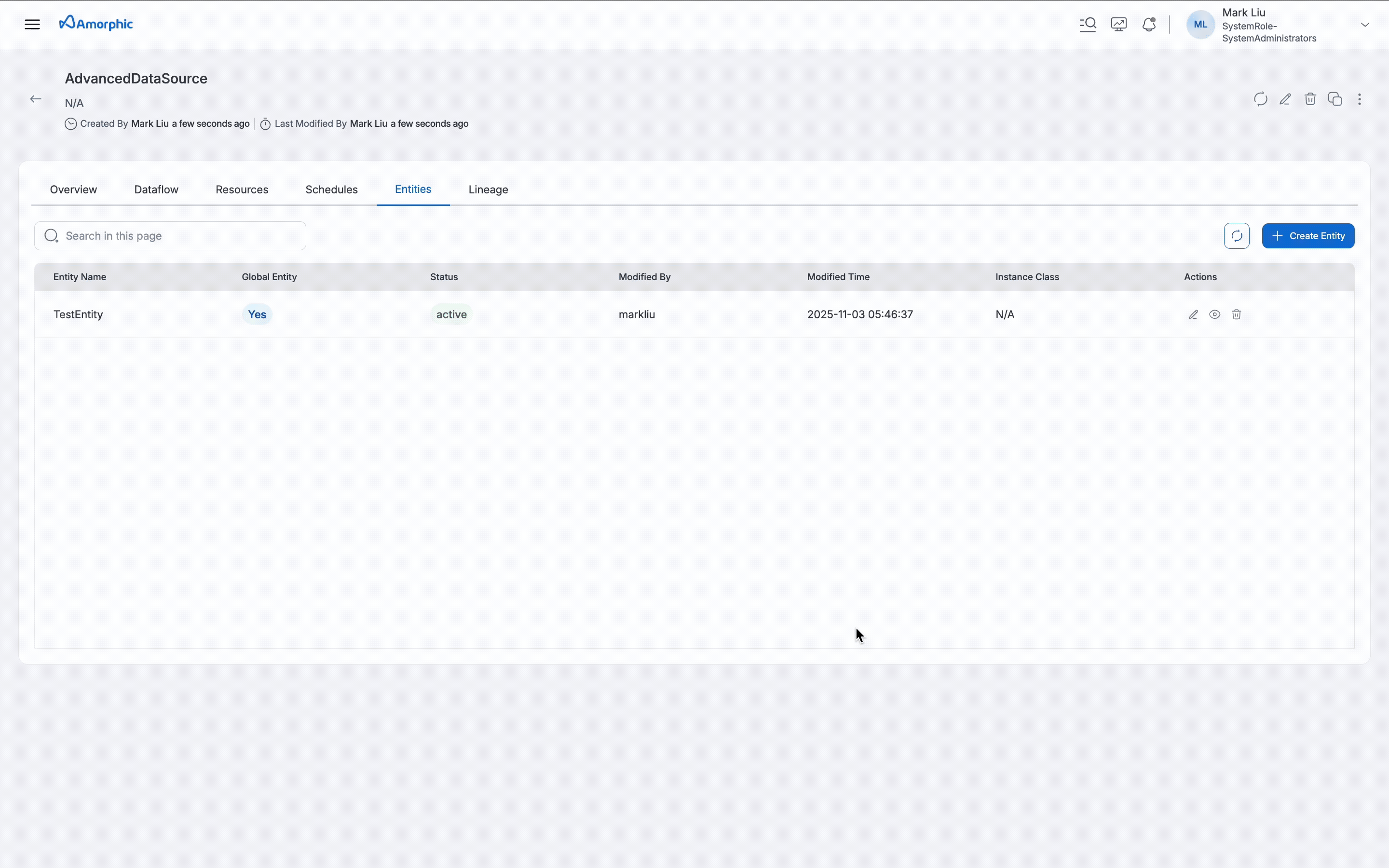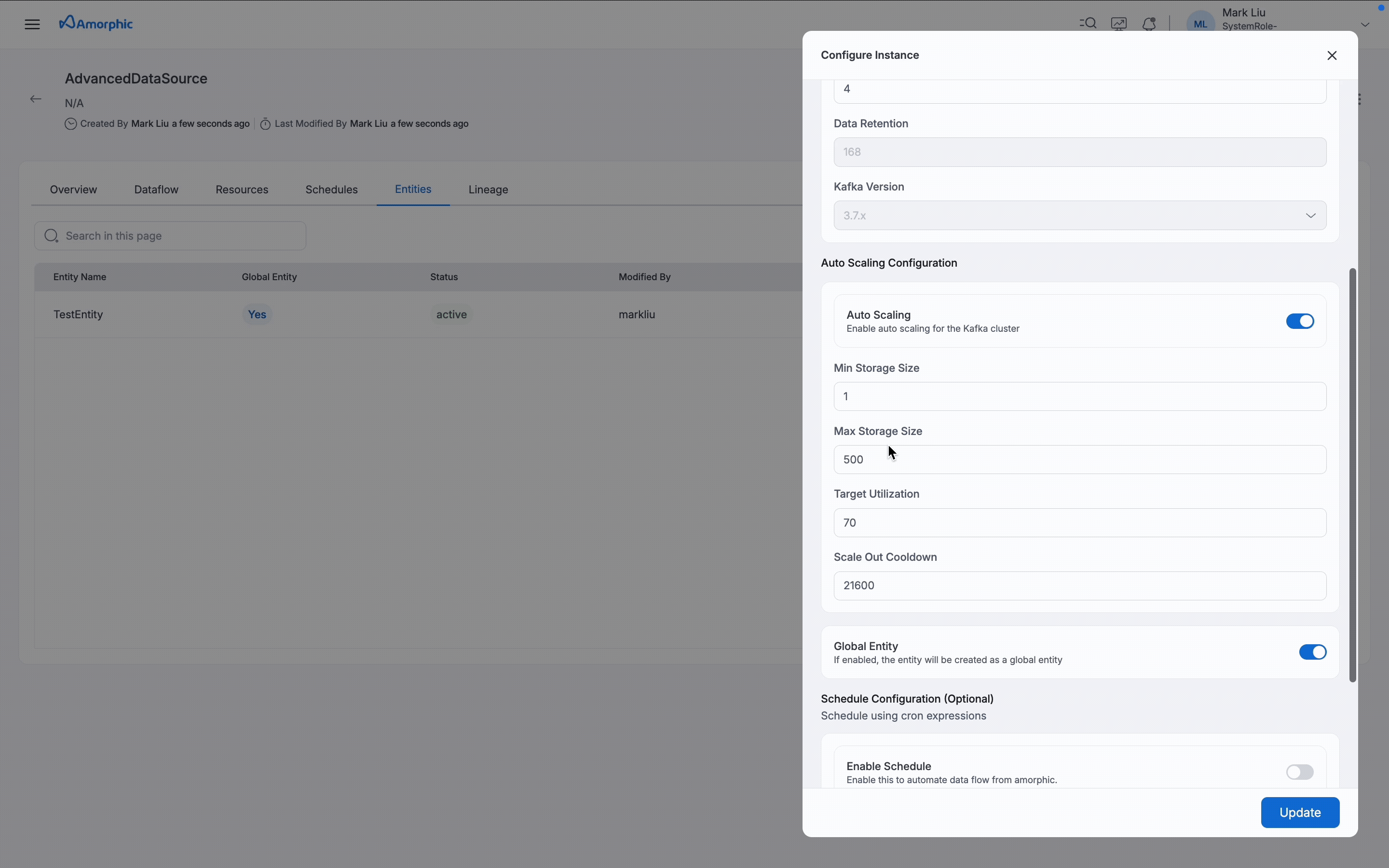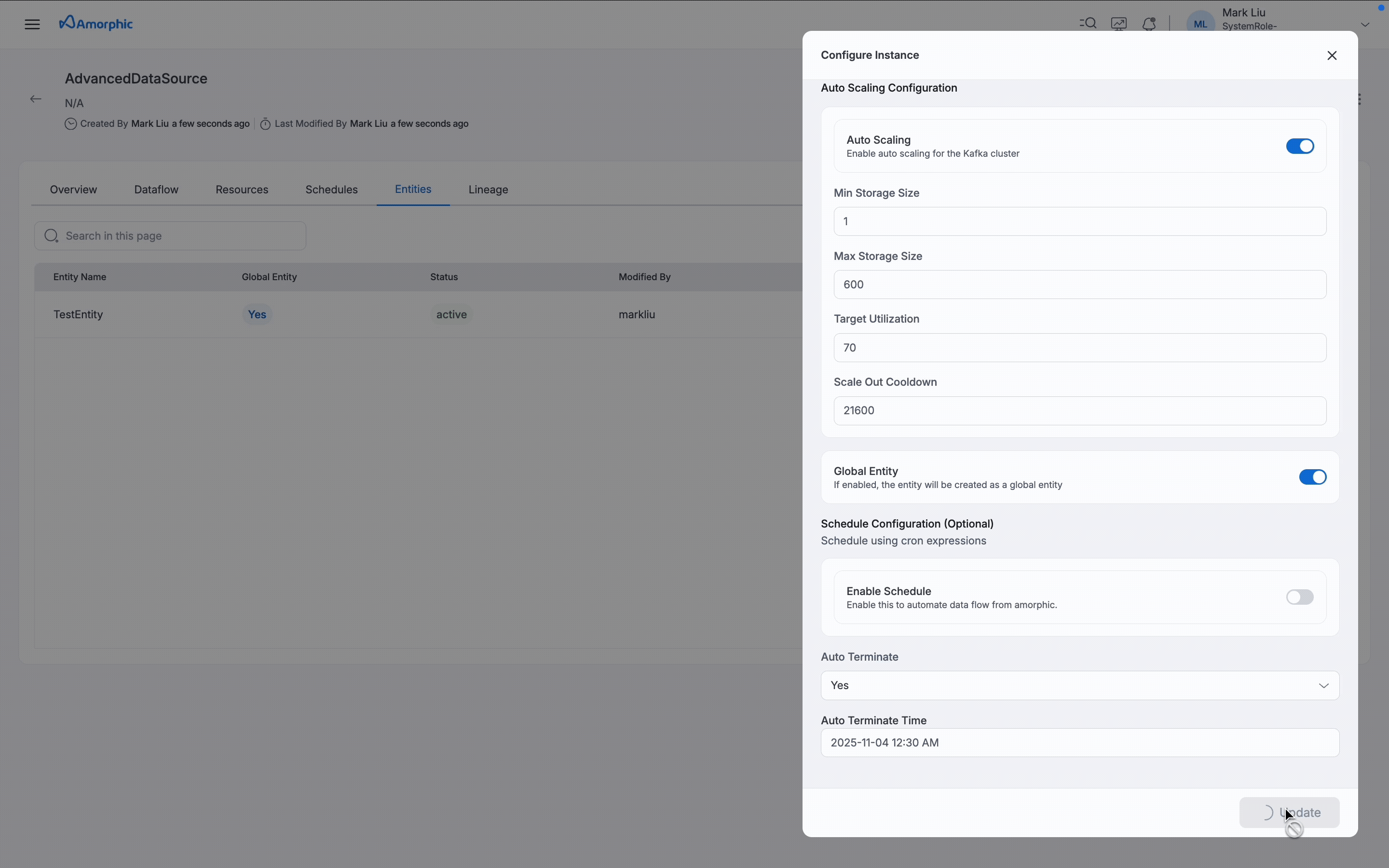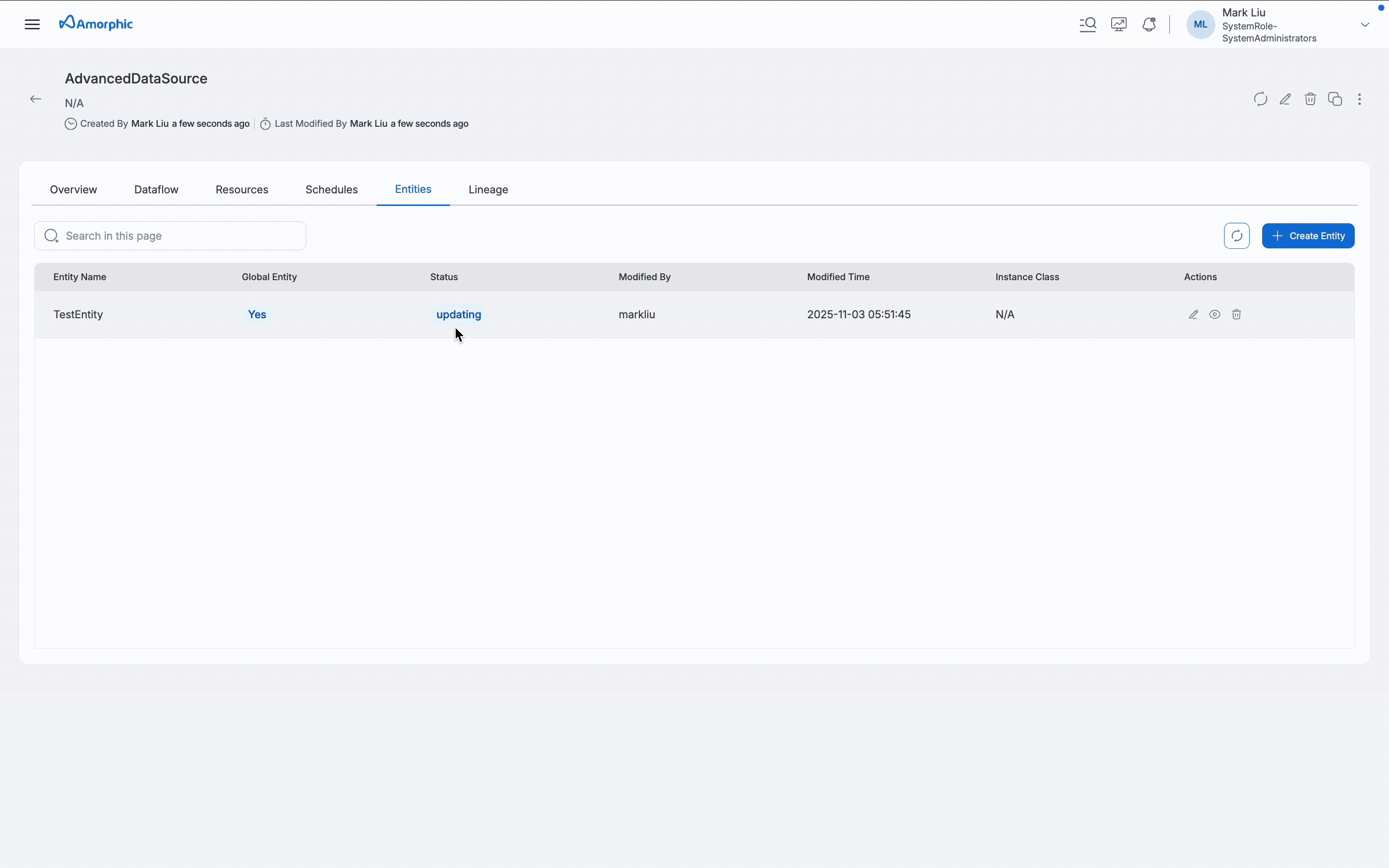
Data Retention: The duration for which ingested data is kept in Kafka topics before being cleaned up. -
Kafka Version: The underlying streaming engine version used to process and transfer data. -
Schedule Config: Defines when the entity should be created. If enabled, you can specify a schedule expression which supports both cron or rate formats. If disabled, the entity is created immediately. -
Auto Terminate: This enables Shared Cluster termination to save resource costs based on the termination time value provided by the user. Auto termination process is triggered every hour and looks for any Shared Cluster that needs to be notified or deleted and sends an email when one of the below criteria is met. The user will receive a notification email in the following scenarios:- If the difference between the auto-terminate process trigger run (every whole hour) and the termination time is less than 30 minutes.
- If the auto-termination process was successfully able to delete the Cluster after the termination time
- If the auto-termination process wasn't able to delete the Cluster due to some fatal errors.
-
IsAutoScalingEnabled: Boolean value to enable or disable auto scaling. When enabled, auto scaling configuration becomes available to automatically adjust storage based on actual usage. By default, auto scaling is enabled.Min Storage Size: Minimum storage capacity that the cluster will always maintain (1 GiB per broker for MSK Standard)Max Storage Size: Maximum storage capacity the cluster can scale up toTarget Utilization: Storage usage threshold (in %) at which scaling actions are triggeredScale Out Cooldown: Minimum wait between storage scale-outs, in seconds
{
"ClusterSize": "kafka.t3.small",
"ClusterStorage": "20",
"NumberOfBrokers": "2",
"KafkaVersion": "3.7.x",
"DataRetentionInHours": "168",
"IsAutoScalingEnabled": true,
"AutoScalingConfig": {
"MinStorageSize": 1,
"MaxStorageSize": 500,
"TargetUtilization": 70,
"ScaleOutCooldown": 21600
}
}
How to edit an Entity
Once the entity creation is successful and is in active status, entity configuration can be updated with Edit option.
Only certain configurations can be updated and the same will be shown when an update entity is clicked and the configuration that are not editable will be greyed out. Entity Name, Data Retention and Kafka Version are not editable and the rest all can be changeable.
In cluster config, among the 3 keys - Cluster Size, Number of Brokers, and Cluster Storage - only one key can be edited at a time.
View Entity details and Dataflows associated
To view additional details of the entity and also the list of all dataflows associated with the entity, one can click on View Entity button which will show all the additional details and the dataflows.
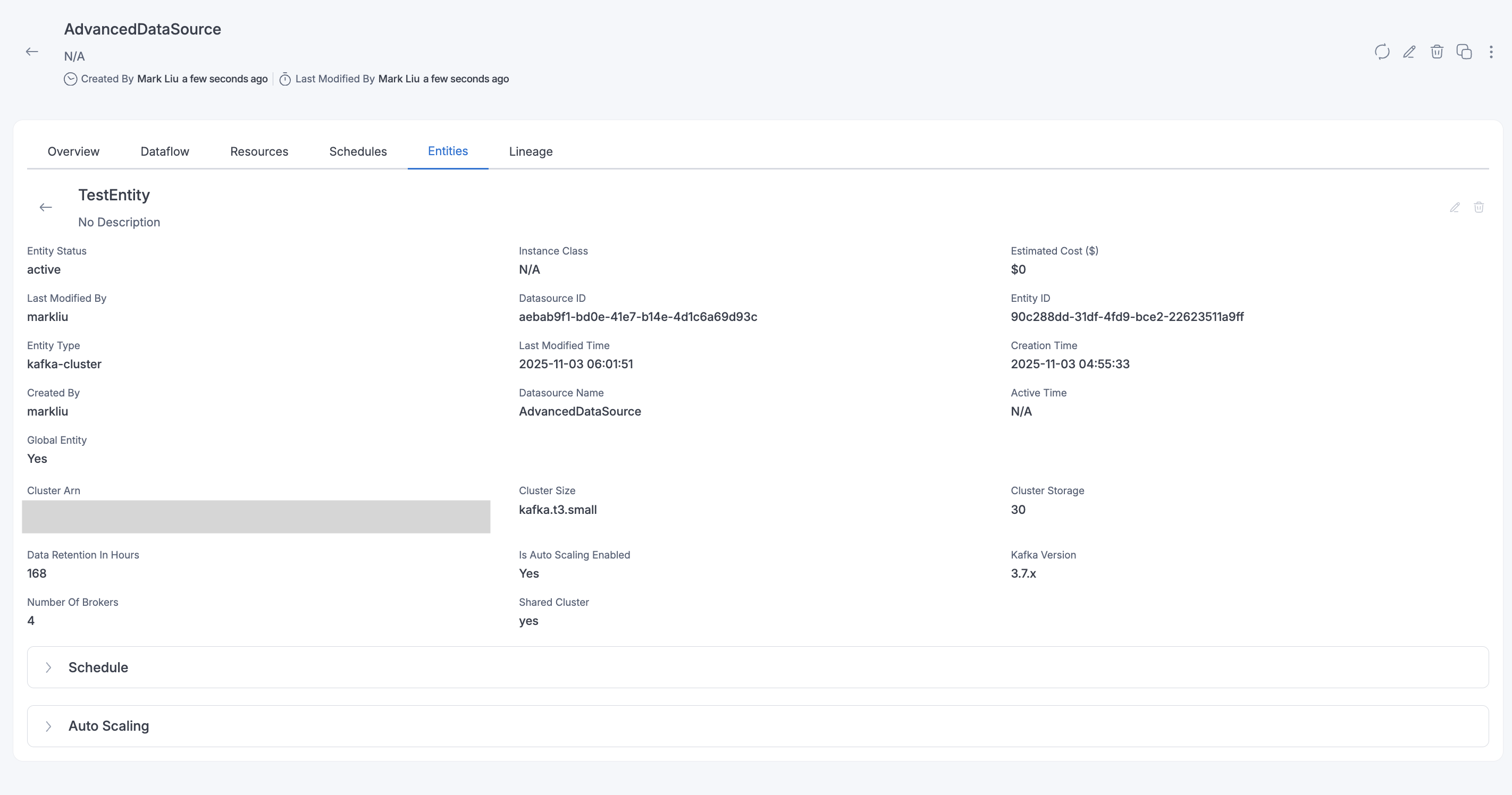
How to delete an Entity
Please note that if there are any active dataflows linked to the entity, it cannot be deleted.
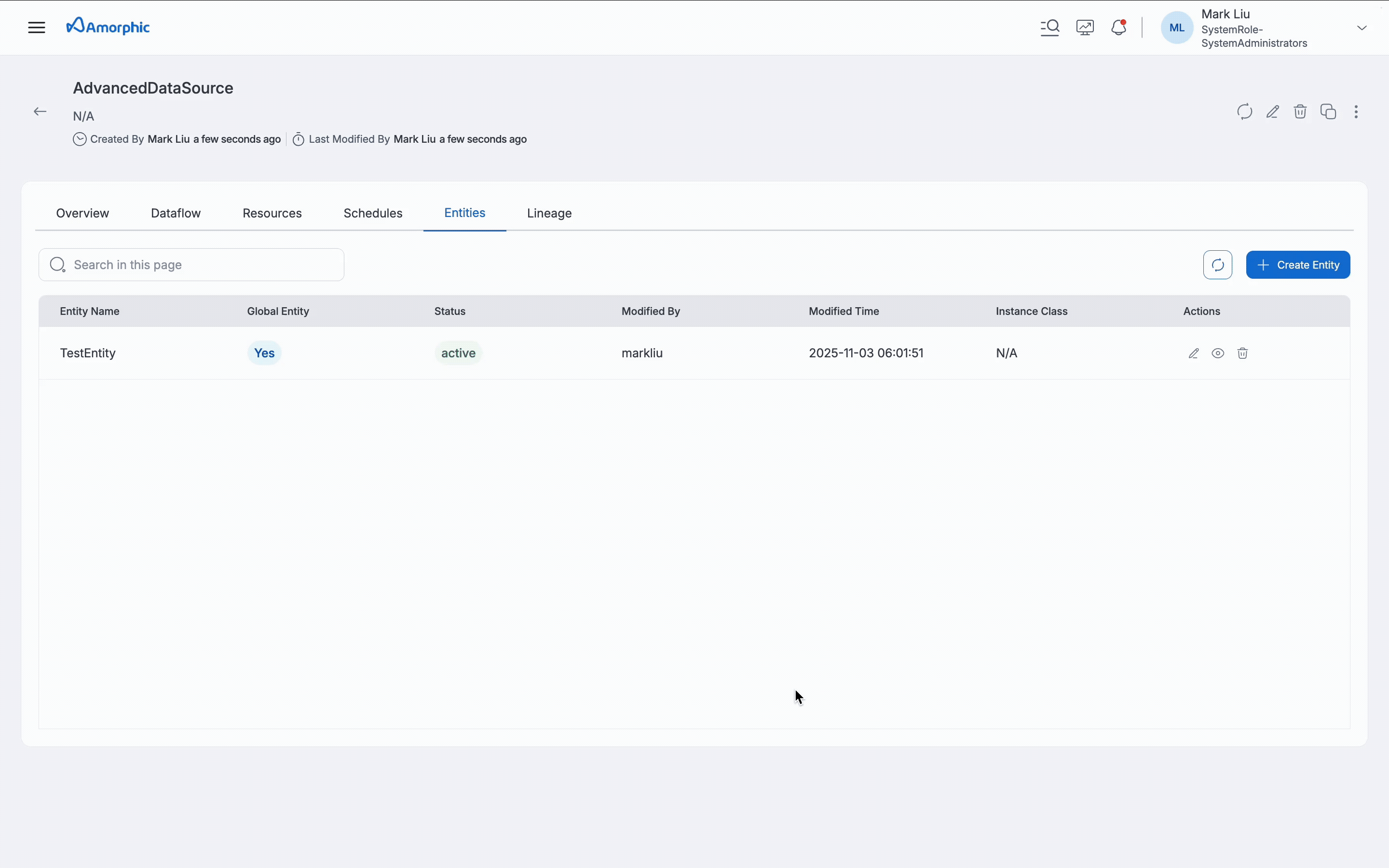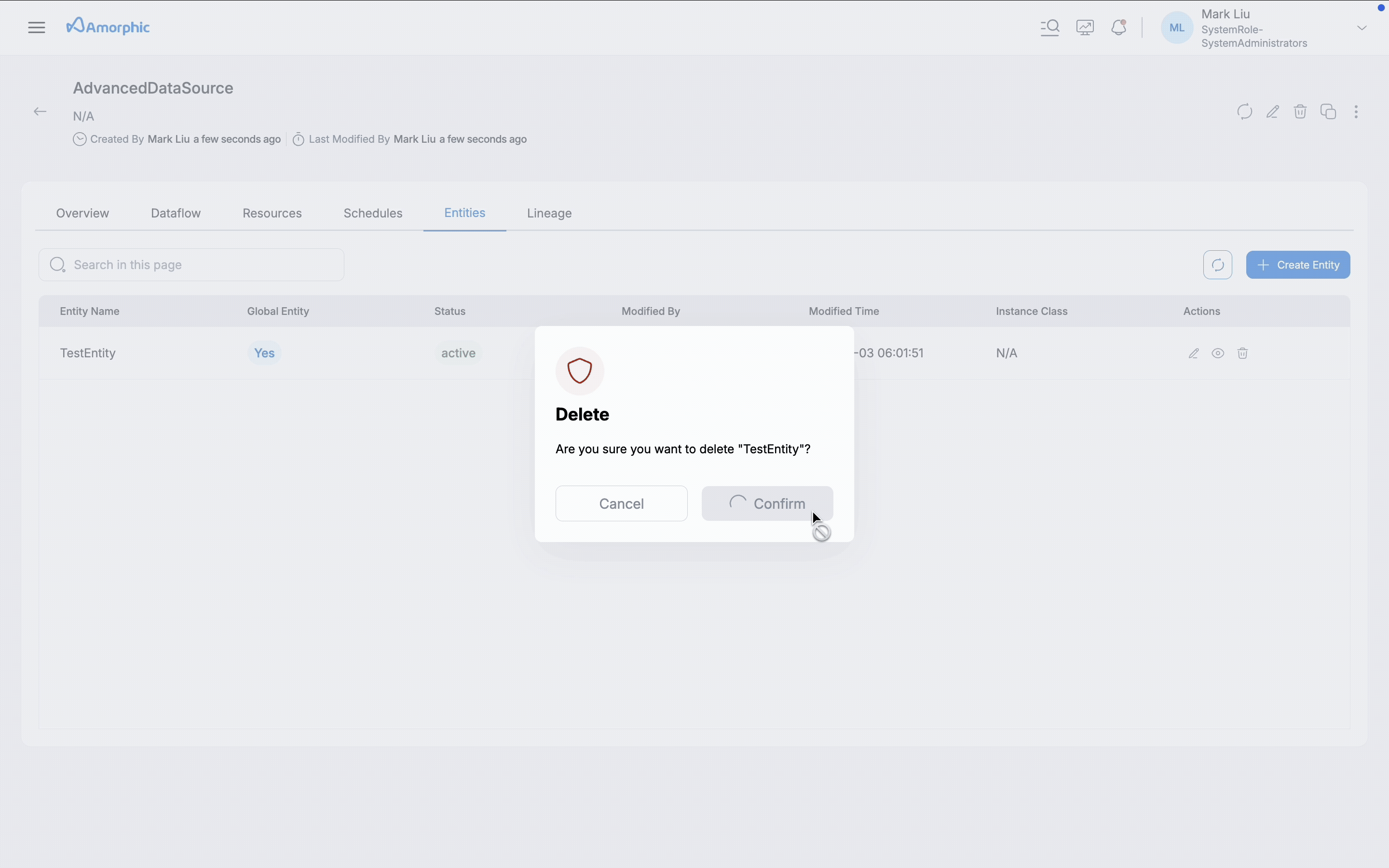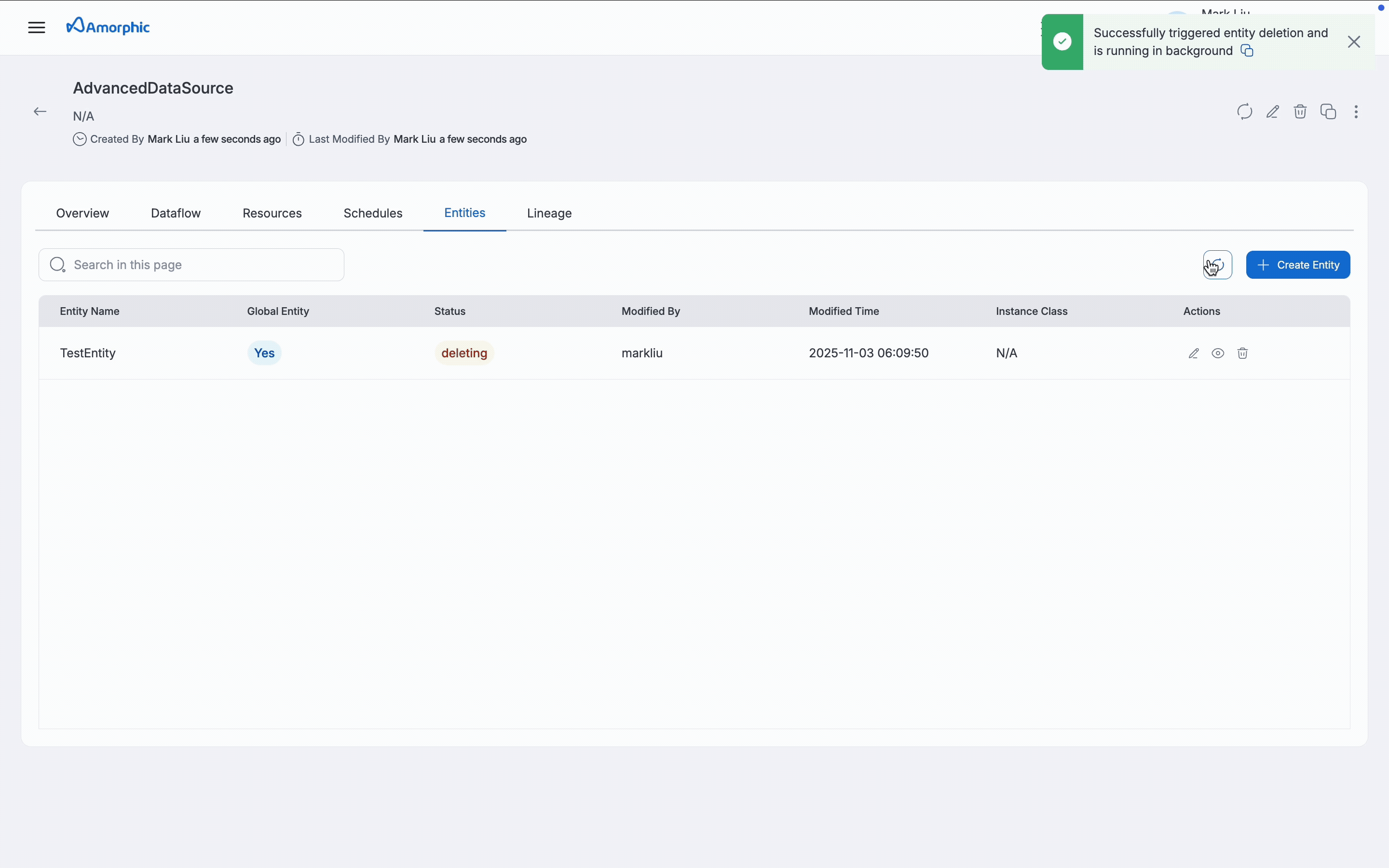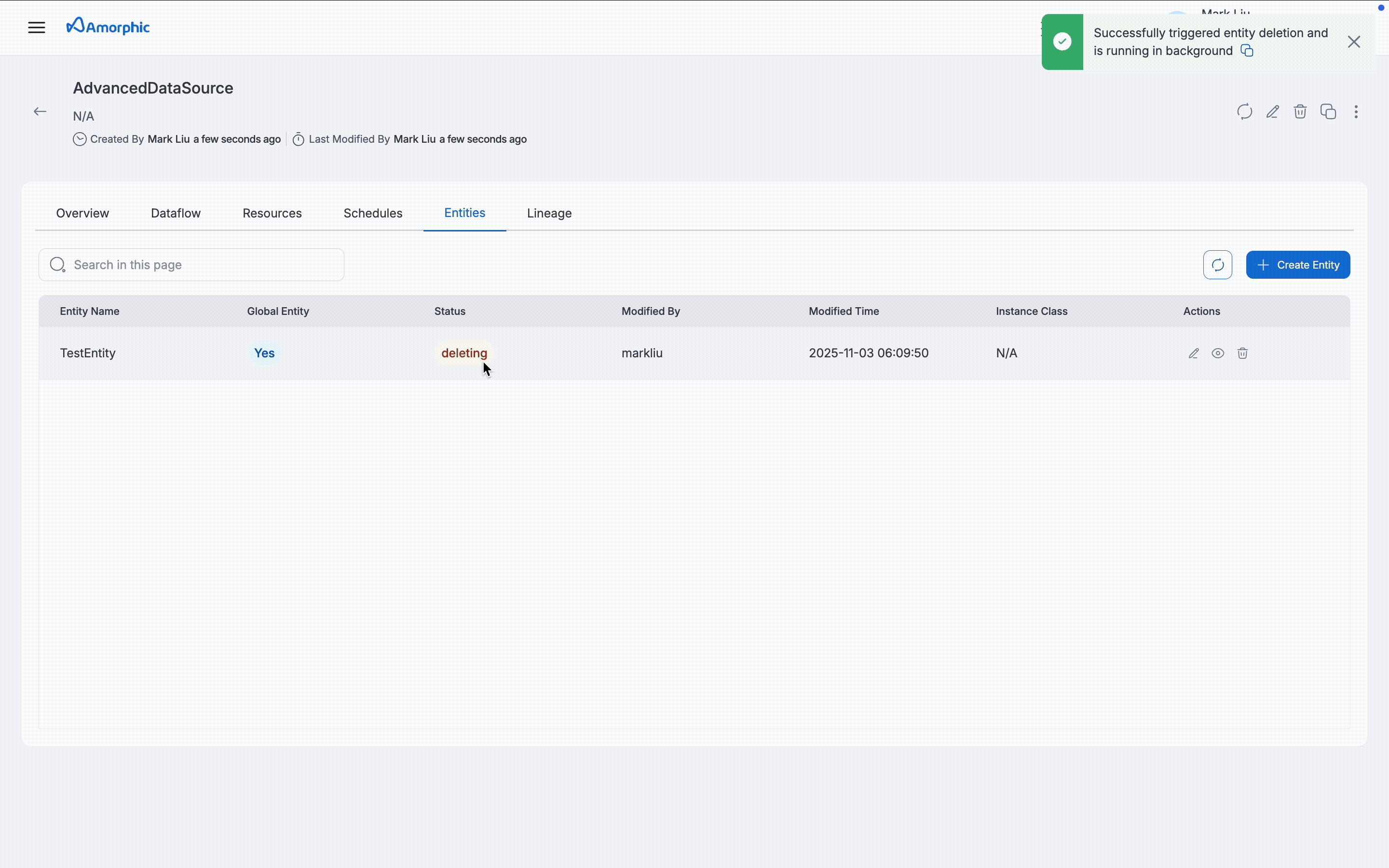
In the Entity listing page, all entities used in the JDBC AdvancedDataload datasource are shown (Shared + Dedicated clusters), but only shared entities can be edited or deleted on this page. Dedicated cluster details can be edited on the datasource page using the Edit Datasource option.
When global entity flag is enabled, editing or deleting an entity can only be done from the datasource where the entity was originally created.